论文 DeepID 系列
Introduction
DeepID 已演进数次。
- DeepID1: Deep Learning Face Representation from Predicting 10,000 Classes
- DeepID2: deep learning face representation by joint identification-verification
- DeepId2+: Deeply learned face representations are sparse, selective, and robust
- DeepID3: Face Recognition with Very Deep Neural Networks
卷积神经网络在DeepID中的作用是是学习特征,即将图片输入进去,学习到一个160维的向量。然后再这个160维向量上,套用各种现成的分类器,即可得到结果。
DeepID 算法优化的主要手段就是增大数据集。
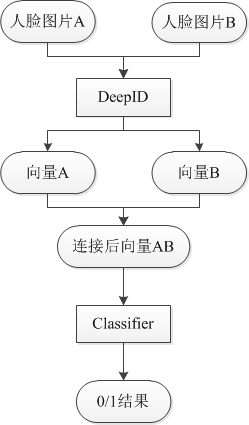
在上述的流程中,DeepID可以换为Hog,LBP等传统特征提取算法。Classifier可以是SVM,Joint Bayes,LR,NN等任意的machine learning分类算法。
在引入外部数据集的情况下,训练流程是这样的。首先,外部数据集4:1进行切分,4那份用来训练DeepID,1那份作为训练DeepID的验证集;然后,1那份用来训练Classifier。这样划分的原因在于两层模型不能使用同一种数据进行训练,容易产生过拟合。
DeepID1
face patchs ---- ConvNet ----> high-level feature of last hidden layer
features ---- joint bayesian or neural network ----> face verification
DeepID features -> Last hidden layer of each ConvNet (160d)
200+ ConvNets (each ConvNets are corresponding to one patch)
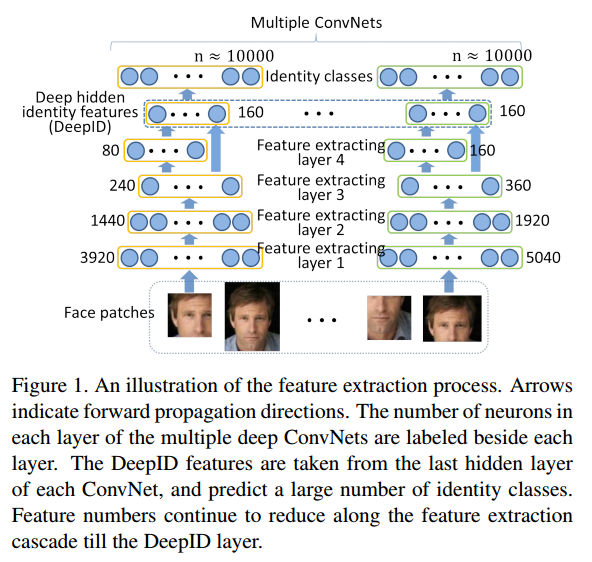
Deep ConvNets
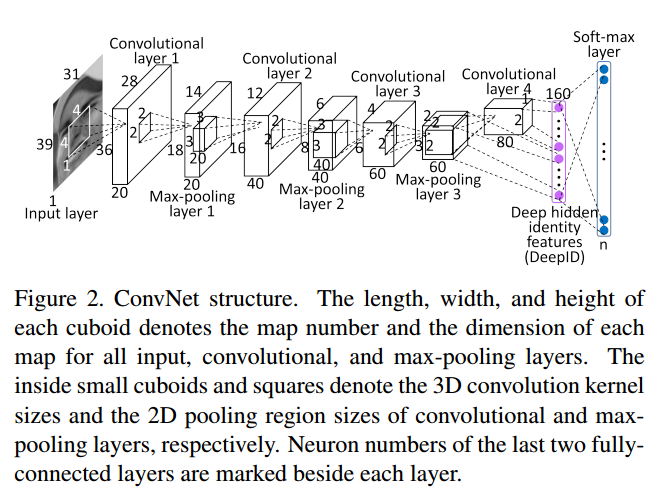
注意倒数第二层,DeepID feature 那一层,与 Convolutional layer 4 和 Max-pooling layer 3 相连,是为了减少信息损失,既考虑局部的特征,又考虑全局的特征。
The last hidden layer of DeepID is fully connected to both the third and fourth convolutional layers (after max- pooling) such that it sees multi-scale features. This is critical to feature learning because after successive down-sampling along the cascade, the fourth convolutional layer contains too few neurons and becomes the bottleneck for information propagation.
Feature Extraction

人脸图片的预处理方式 aligned and patch。
- Faces are globally aligned by similarity transformation according to the two eye centers and the mid-point of the two mouth corners.
- Features are extracted from 60 face patches with ten regions, three scales, and RGB or gray channels.
Face Verification
Joint Bayesian

Neural Network
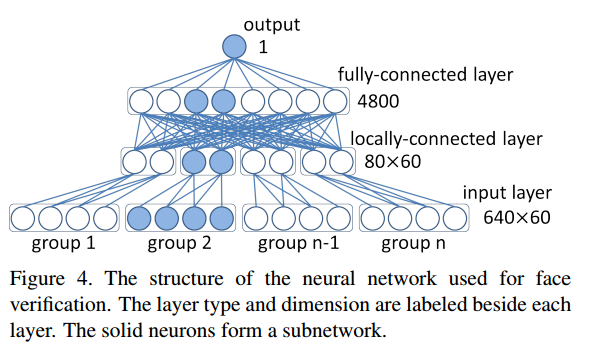
Input layer: 60 groups, each has [2 (a patch pair) * 160 (d features of a convnet) * 2 (patch and its horizontally flipped counterpart)]
Features in the same group are highly correlated.
Experiments
- 使用multi-scale patches的convnet比只使用一个只有整张人脸的patch的效果要好。
- DeepID自身的分类错误率在40%到60%之间震荡,虽然较高,但DeepID是用来学特征的,并不需要要关注自身分类错误率。
- 使用DeepID神经网络的最后一层softmax层作为特征表示,效果很差。
- 随着DeepID的训练集人数的增长,DeepID本身的分类正确率和LFW的验证正确率都在增加。
DeepID2
face identification signal + face verification signal
DeepID1的卷积神经网络最后一层softmax使用的是Logistic Regression作为最终的目标函数,也就是识别信号 face identification signal;
但在DeepID2中,目标函数上添加了验证信号 face verification signal,两个信号使用加权的方式进行了组合。
Identification-Verification Guided Deep Feature Learning
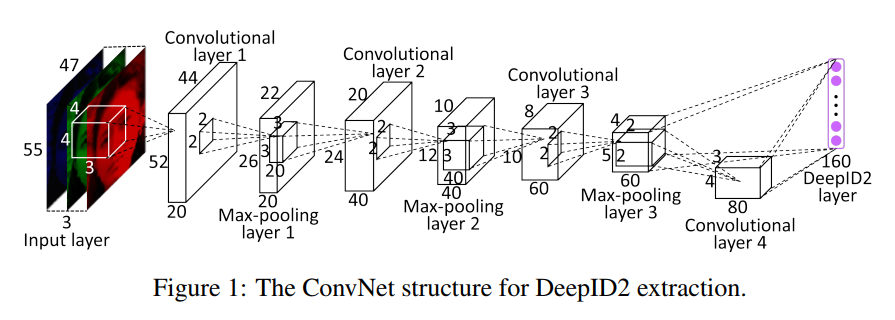
x is input face patch, f is DeepID2 vector, θc is convnet parameters to be learned.
Two supervisory signals:
- face identification signal 识别信号
Classifies each face image into one of n different identities.
softmax
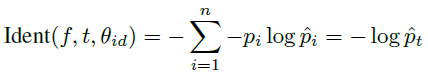
f is the DeepID2 vector, t is the target class, θ is the softmax layer parameters, p is the target probability distribution, p hat is the predicted probability distribution. - face verification signal 验证信号
encourages DeepID2 extracted from faces of the same identity to be similar.
Regularize DeepID2 to reduce the intra-personal variations. Can be L1/L2 norm and cosine similarity.
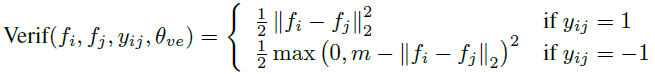
f1 and f2 are DeepID2 vectors of two images; y=1 means same identity, minimize L2; y=-1 means different identity, distance larger than margin m.
由于验证信号的计算需要两个样本,所以整个卷积神经网络的训练过程也就发生了变化,之前是将全部数据切分为小的batch来进行训练。现在则是每次迭代时随机抽取两个样本,然后进行训练。训练过程如下:

在训练过程中,lambda是验证信号的加权参数。参数是动态调整的,调整策略是使最近的训练样本上的验证错误率最低。
Experiments
首先使用SDM算法对每张人脸检测出21个landmarks,然后根据这些landmarks,再加上位置、尺度、通道、水平翻转等因素,每张人脸形成了400张patch,使用200个CNN对其进行训练,水平翻转形成的patch跟原始图片放在一起进行训练。这样,就形成了400×160维的向量。
这样形成的特征维数太高,所以要进行特征选择,不同于之前的DeepID直接采用PCA的方式,DeepID2先对patch进行选取,使用前向-后向贪心算法选取了25个最有效的patch,这样就只有25×160维向量,然后使用PCA进行降维,降维后为180维,然后再输入到联合贝叶斯模型中进行分类。
DeepID2使用的外部数据集仍然是CelebFaces+,但先把CelebFaces+进行了切分,切分成了CelebFaces+A(8192个人)和CelebFaces+B(1985个人)。首先,训练DeepID2,CelebFaces+A做训练集,此时CelebFaces+B做验证集;其次,CelebFaces+B切分为1485人和500人两个部分,进行特征选择,选择25个patch。最后在CelebFaces+B整个数据集上训练联合贝叶斯模型,然后在LFW上进行测试。在上一段描述的基础上,进行了组合模型的加强,即在选取特征时进行了七次。第一次选效果最好的25个patch,第二次从剩余的patch中再选25个,以此类推。然后将七个联合贝叶斯模型使用SVM进行融合。最终达到了99.15%的结果。
其中,选取的25个patch如下:

对lambda进行调整,也即对识别信号和验证信号进行平衡,发现lambda在0.05的时候最好。使用LDA中计算类间方差和类内方差的方法进行计算。得到的结果如下:
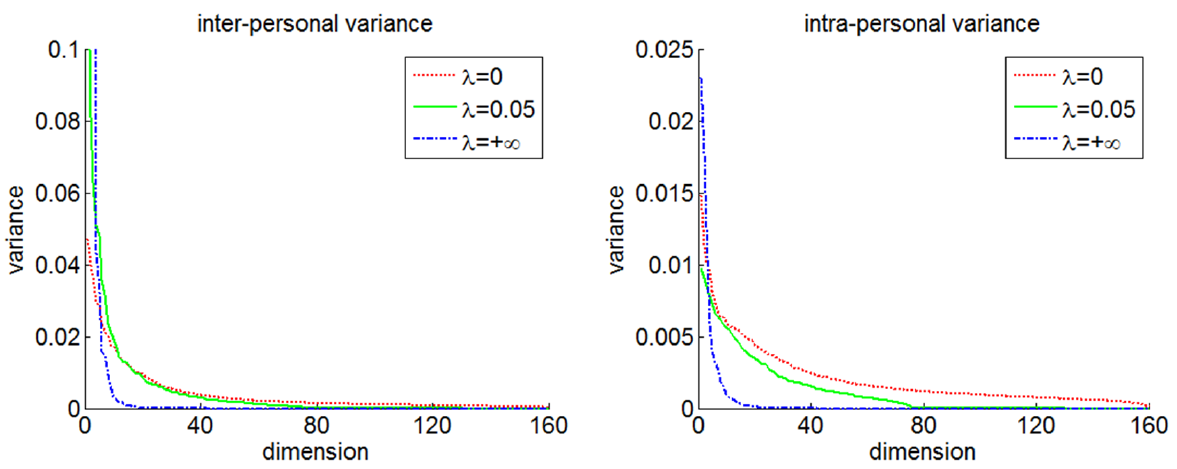
可以发现,在lambda=0.05的时候,类间方差几乎不变,类内方差下降了很多。这样就保证了类间区分性,而减少了类内区分性。如果lambda为无穷大,即只有验证信号时,类间方差和类内方差都变得很小,不利于最后的分类。
- DeepID的训练集人数越多,最后的验证率越高。
- 对不同的验证信号,包括L1,L2,cosin等分别进行了实验,发现L2 Norm最好。
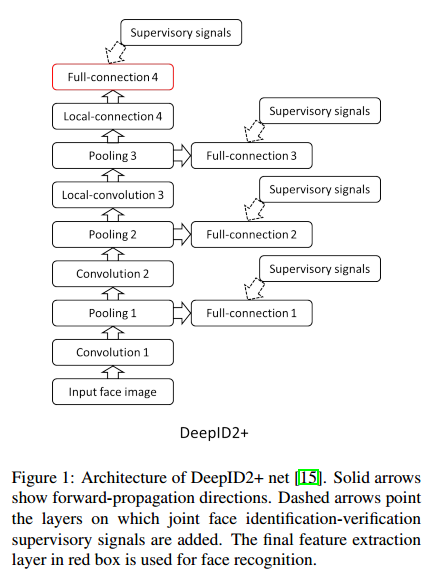
DeepID2+
Compared with the DeepID2, DeepID2+ added the supervisory signal in the early layers and increases the dimension of hidden repsresentation.
In the DeepID2+,author discover some nice property of neural network: sparsity, selectivity and robustness.
- Sparsity
神经单元的适度稀疏性,该性质甚至可以保证即便经过二值化后,仍然可以达到较好的识别效果。 - Selectivity
高层的神经单元对人比较敏感,即对同一个人的头像来说,总有一些单元处于一直激活或者一直抑制的状态。 - Robustness
DeepID2+的输出对遮挡非常鲁棒。
DeepID2+ Nets
和 DeepID2 相比有三点改动。
- DeepID 层从160维提高到512维。
- 训练集将 CelebFaces+ 和 WDRef 数据集进行了融合,共有12000人,290000张图片。
- 将 DeepID 层不仅和第四层和第三层的 max-pooling 层连接,还连接了第一层和第二层的 max-pooling层。
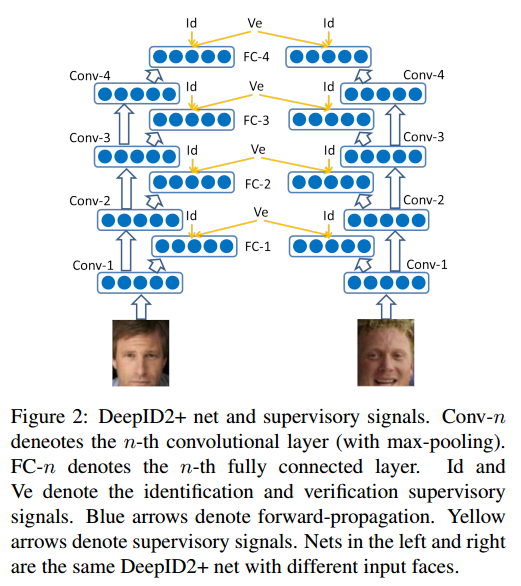
joint face identification-verification
supervisory signals
Moderate Sparsity of Neural Activations
- Sparsity for each image
一张 image 差不多激活半数的 neuron,使不同身份的 face 更可区分。 - Sparsity for each neuron
一个 neuron 差不多被半数的 image 激活,使其有更大区分度。

Activation patterns are more important than precise activation values. 所以使用阈值对最后输出的512维向量进行了二值化处理,发现效果降低有限。
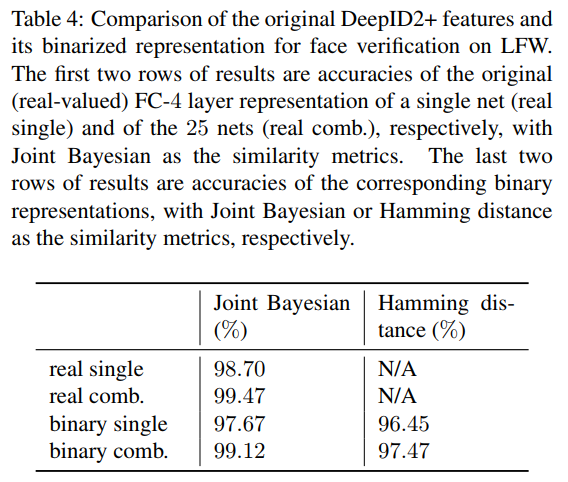
而二值化的数据更节省空间和计算能力,图片搜索更快。
Selectiveness on Identities and Attributes
存在某个神经单元,只使用普通的阈值法,就能针对某个人得到97%的正确率。不同的神经单元针对不同的人或不同的种族或不同的年龄都有很强的区分性。这和它的激活或抑制态有关。
Robustness of DeepID+ Features
在训练数据中没有遮挡数据的情况下,DeepID2+自动就对遮挡有了很好的鲁棒性。
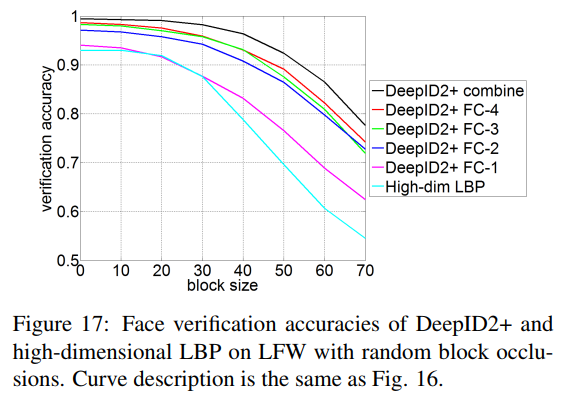
有两种方式对人脸进行多种尺度的遮挡,第一种是从下往上进行遮挡,从10%-70%。第二种是不同大小的黑块随机放,黑块的大小从10×10到70×70。

结论是遮挡在20%以内,块大小在30×30以下,DeepID2+的输出的向量的验证正确率几乎不变。
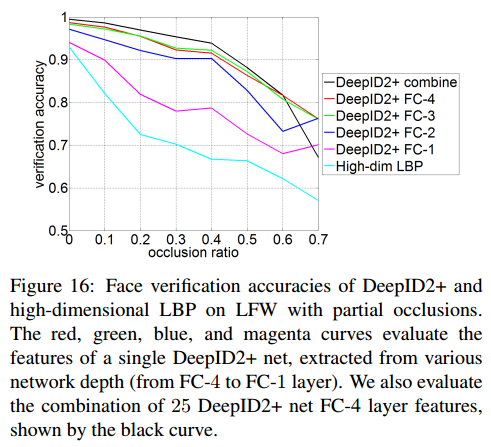
DeepID3
Explore 2 very deep neural network architectures.
Stacked convolution in VGG net
Inception layers in GoogLeNet
DeepID3 Net
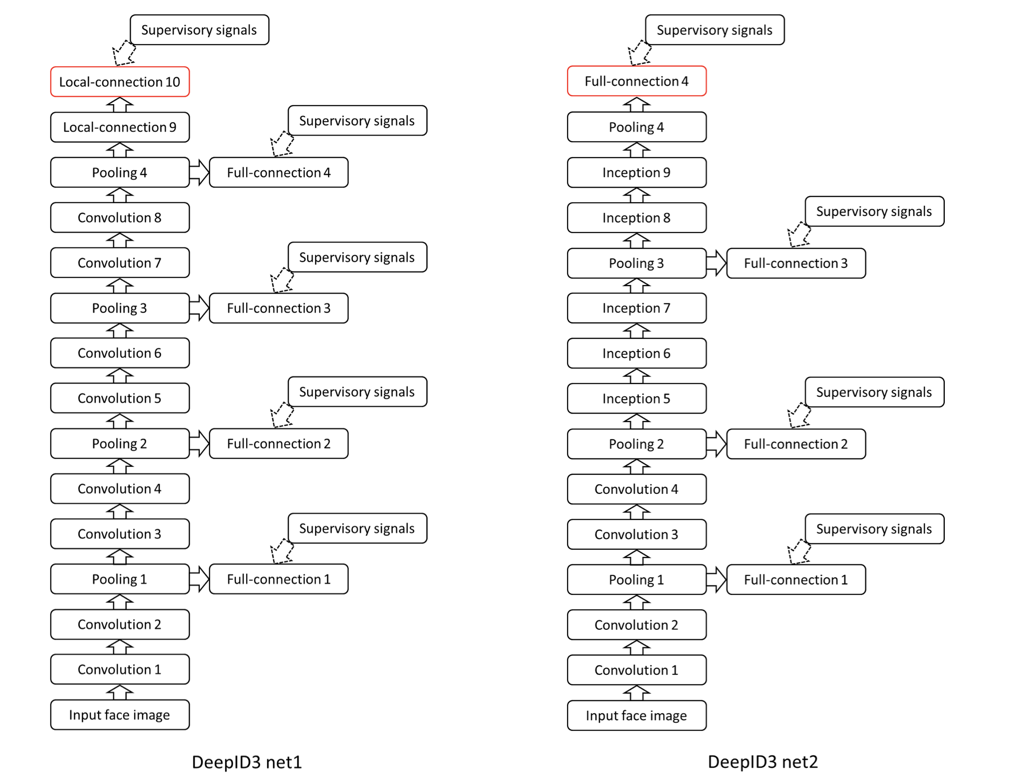
DeepID3 比起 DeepID2+ 并没有明显的优势。
Ref:
[1] https://www.researchgate.net/publication/283749931_Deep_Learning_Face_Representation_from_Predicting_10000_Classes
[2] https://arxiv.org/abs/1406.4773
[3] https://arxiv.org/abs/1412.1265
[4] https://arxiv.org/abs/1502.00873
[5] https://blog.csdn.net/stdcoutzyx/article/details/42091205