论文 FaceNet - A Unified Embedding for Face Recognition and Clustering
Introduction
核心思想
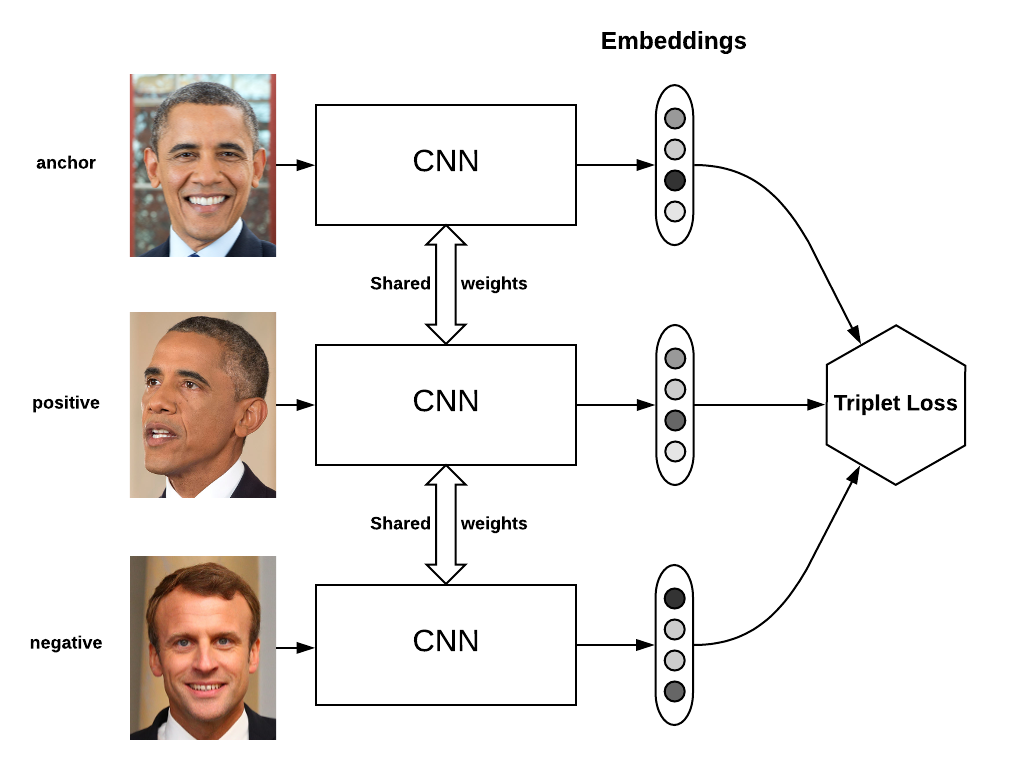
Face Image -> 128-D Embedding (End to End)
Euclidean distance between Embeddings = Measure of face similarity
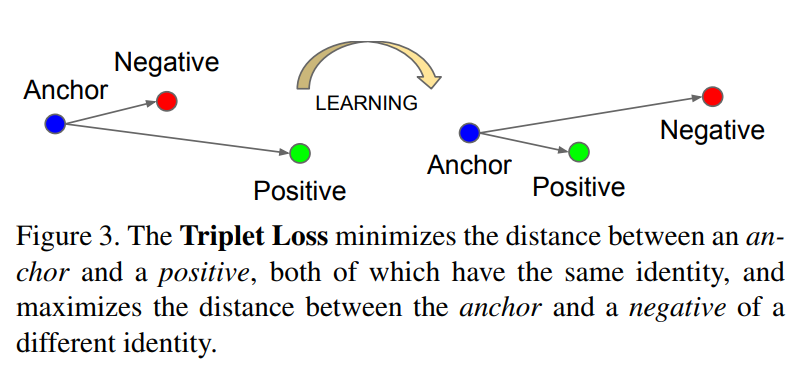
Triplet Loss = minimize sum(||A - P|| - ||A - N|| + α),P和N如何选择很重要
with Embedding, face recognition, verification, clustering 变成了常规任务,Embedding 之间距离的较量。
图片是 tight crops of the face area,无 2D or 3D alignment。
Triplet Loss
为什么不用 softmax?
- Usually in supervised learning we have a fixed number of classes and train the network using the softmax cross entropy loss. However in some cases we need to be able to have a variable number of classes. In face recognition for instance, we need to be able to compare two unknown faces and say whether they are from the same person or not.
Triplet loss tries to enforce a margin between each pair of faces from one person to all other faces. 和 SVM 的 margin 有点像。
triplets of embeddings:
- an anchor
- a positive of the same class as the anchor
- a negative of a different class
公式

即 For some distance on the embedding space , the loss of a triplet is:
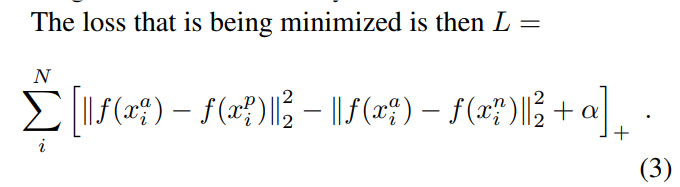
Triplet 应当选 hard triplets,违反公式1的例子,这样才对模型的训练有帮助,fast convergence。
Triplet Selection and Training Procedure
Three categories of triplets:
- Easy Triplets
triplets which have a loss of 0, because - Hard Triplets
triplets where the negative is closer to the anchor than the positive, i.e. - Semi-hard Triplet
triplets where the negative is not closer to the anchor than the positive, but which still have positive loss:
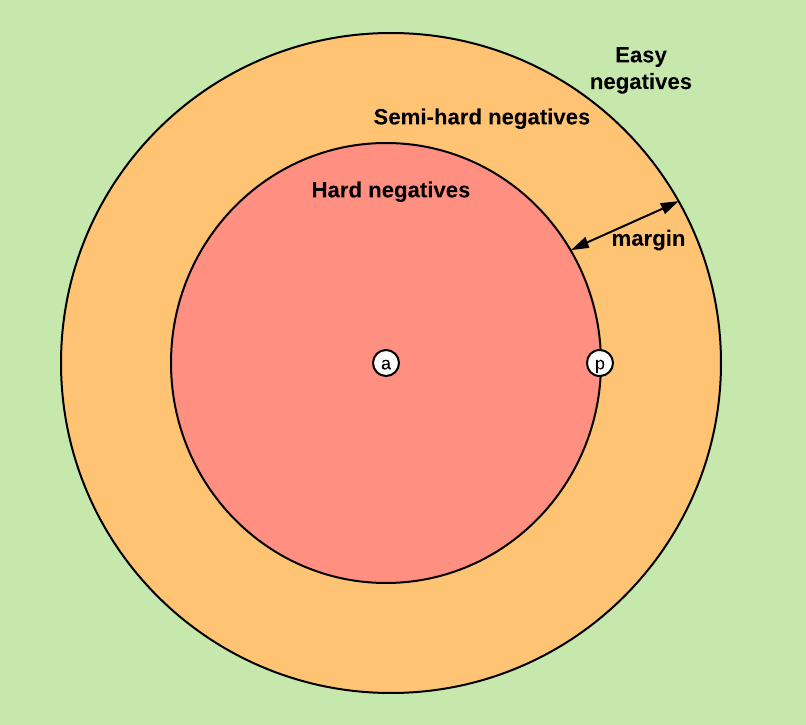
在选择 triplet 时,我们想要 Hard Positive $$argmax_{x_i^p} \parallel f(x_i^a) - f(x_i^p) \parallel_2^2$$ 和 Hard Negative $$argmin_{x_i^n} \parallel f(x_i^a) - f(x_i^n) \parallel_2^2$$。
但是在整个训练集上计算不现实,而且 outlier 和 mislabelled 会严重影响选择。
The paper pick a random semi-hard negative for every pair of anchor and positive, and train on these triplets.
有两条出路:
- Offline Triplet Mining
Generate triplets offline every n steps, using the most recent network checkpoint and computing the argmin and argmax on a subset of the data.
Not efficient enough. - Online Triplet Mining
Generate triplets online. This can be done by selecting the hard positive/negative exemplars from within a mini-batch.
Online Generation
In online mining, we have computed a batch of embeddings from a batch of inputs.
valid triplet: (i,j,k) 中 i,j 属于同一人,k 则不。
Suppose that you have a batch of faces as input of size , composed of different persons with images each. A typical value is . 有两种策略:
- Batch All
select all the valid triplets, and average the loss on the hard and semi-hard triplets.- a crucial point here is to not take into account the easy triplets (those with loss
0), as averaging on them would make the overall loss very small. - this produces a total of triplets ( anchors, possible positives per anchor, possible negatives).
- a crucial point here is to not take into account the easy triplets (those with loss
- Batch Hard (better)
for each anchor, select the hardest positive (biggest distance and the hardest negative among the batch.- this produces triplets.
- the selected tripltes are the hardest among the batch.
Model Architecture
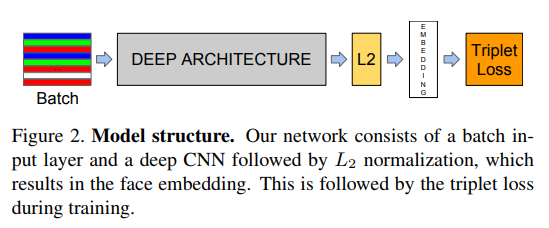
Train the CNN using Stochastic Gradient Descent (SGD) with standard backprop and AdaGrad.
两种,Zeiler&Fergus based Model,GoogLeNet style Inception Model。
Their practical differences lie in the difference of parameters and FLOPS. 选择使用哪个模型要看应用场景。
- Model running in a datacenter can have many parameters and require a large number of FLOPS.
- Model running on a mobile phone needs to have few parameters, so that it can fit into memory.
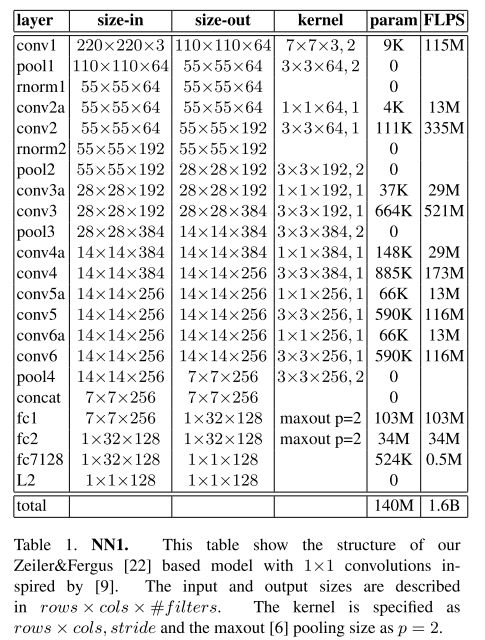
Zeiler&Fergus based Model
Per image
- 140 million parameters
- 1.6 billion FLOPS
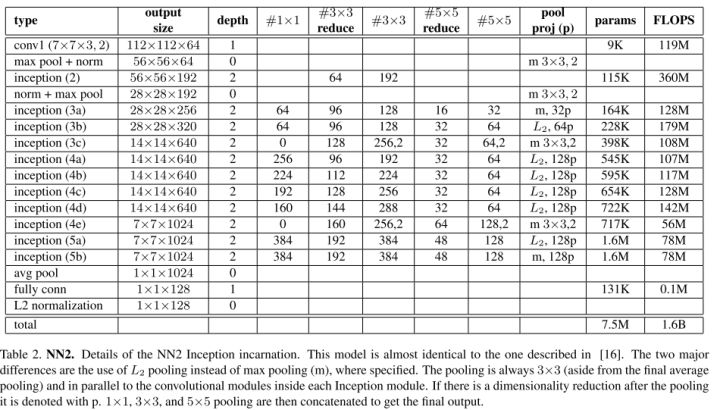
GoogLeNet style Inception Model
Per image
- 6.6M -7.5M parameters
- 500M - 1.6B FLOPS
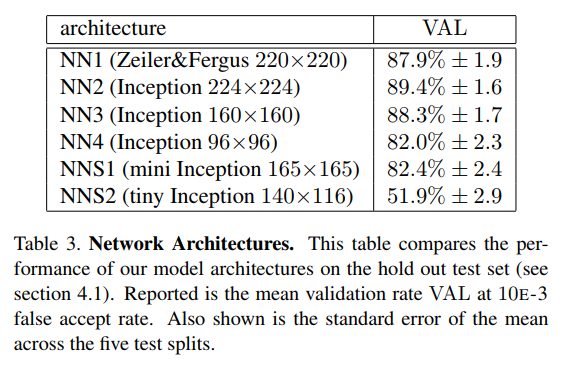
Experiments
FLOPS vs. Accuracy Trade-off
注:model parameters 与 Accuray 没看出明显相关性。
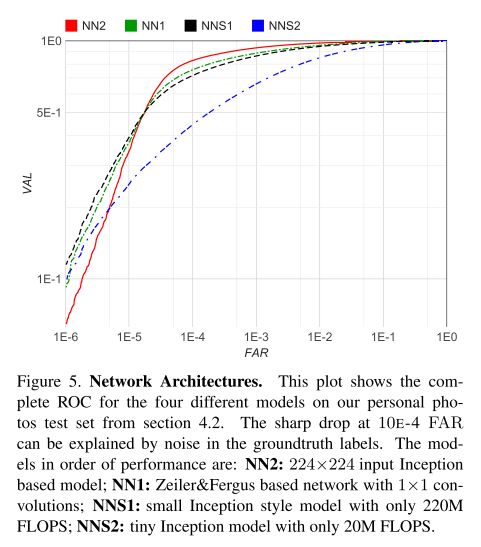
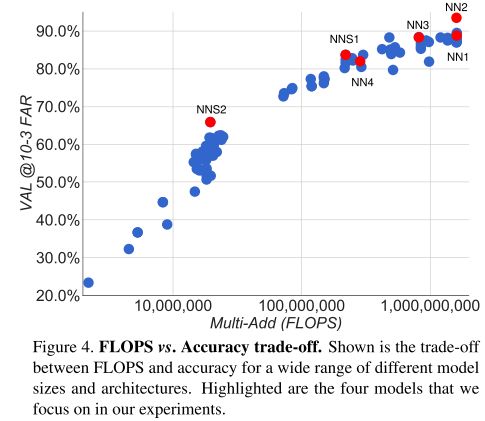
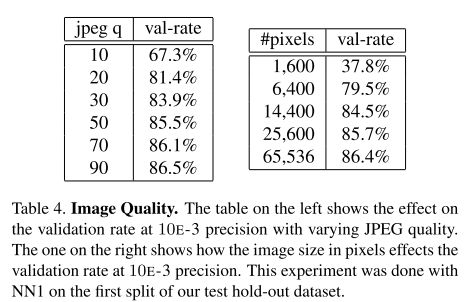
Sensitivity to Image Quality
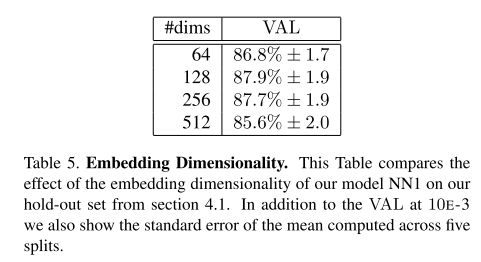
Embedding Dimensionality
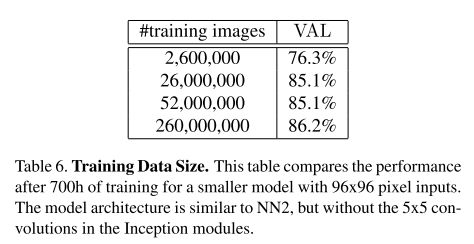
Amouint of Training Data
Summary
优点:
- 直接学习 an embedding into
an Euclidean space for face verification. - 不需要太多 alignment,只需要 tight crop arouind the face area。
未来:
- Better understanding of the error cases;
- Further improving the model;
- Reducing model size and reducing CPU + requirements;
- Reduce the currently extremely long training time.
Code
比葫芦画瓢实现了一下。
FaceNet Face Recognition
Ref:
[1] https://arxiv.org/abs/1503.03832
[2] https://omoindrot.github.io/triplet-loss