论文 StarGAN - Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Image-to-image translation for multiple domains using only a single model.

Introduction
The task of image-to-image translation is to change a particular aspect of a given image to another. 比如上图改变人物面部表情,自从generative adversarial networks(GANs)出现之后有了很大进展。
Attribute, meaningful feature inherent in an image比如发色。
Attribute value, a particular value of an attribute比如金发。
Domain, a set of images sharing the same attribute value.比如所有女士照片是一个domain,男士照片是另一个。
一些有labeled attributes的数据集。
- CelebA, 40 labels related to facial attributes, such as hair color, gender, age.
- RaFD, 8 labels for facial expressions, such as happy, angry, sad.
Cross-domain model对multi-domain image-to-image translation效率和效果都不太好。k的domain需要训练k(k-1)个generator。每个generator只能用到其对应2个domain的data。且不能使用多个数据集,因为其会是partially labeled。
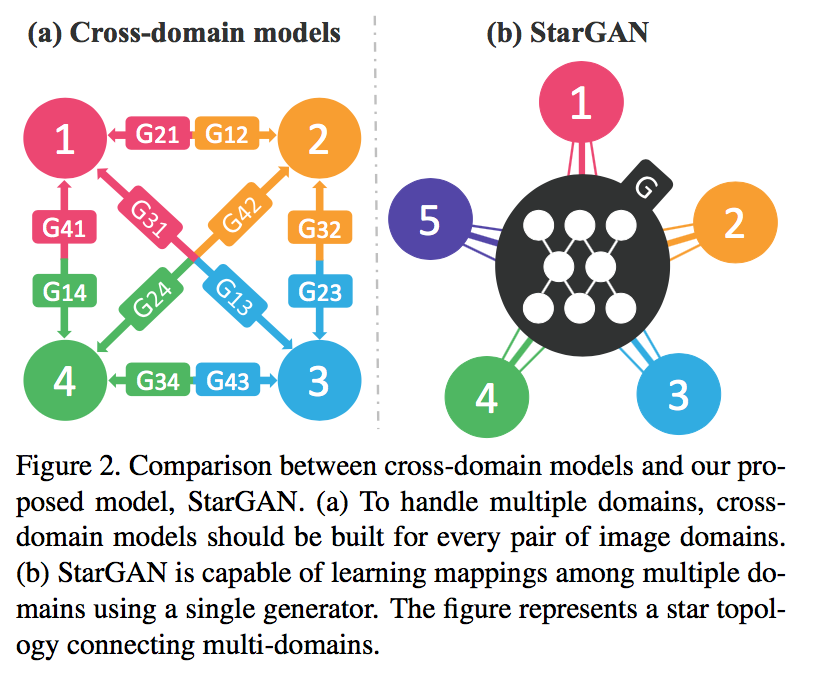
StarGAN克服了这些困难。
- one single generator and a discriminator
- multi-domain image translation between multiple datasets by utilizing a mask vector method that enables StarGAN to control all available domain labels.
Related Work
- Generative Adversarial Network.
在computer vision领域用于image generation, image translation, super-resolution imaging, face image synthesis.
典型结构包括两个module,discriminator和generator。Discriminator learns to distinguish between real and fake samples, while the generator learns to generate fake samples that are indistinguishable from real samples.
StarGAN用到其adversarial loss用来使生成图片更真实。 - Conditional GANs
Prior studies have provided both the discriminator and generator with class information in order to generate samples conditioned on the class.
应用场景如generating particular images highly relevant to a given text description, domain transfer, super-resolution imaging, photo editing. - Image-to-Image Translation
Pix2pix, cGANs. It combines an adversarial loss with a L1 loss, thus requires paired data samples.
UNIT combines variational autoencoders (VAEs) with CoGAN, a GAN framework where two generators share weights to learn the joint distribution of images in cross domains.
CycleGAN and DiscoGAN preserve key attributes between the input and the translated image by utilizing a cycle consistency loss.
然而这些都一次只能学习两个domain的关系。
Star Generative Adversarial Networks
Multi-Domain Image-to-Image Translation
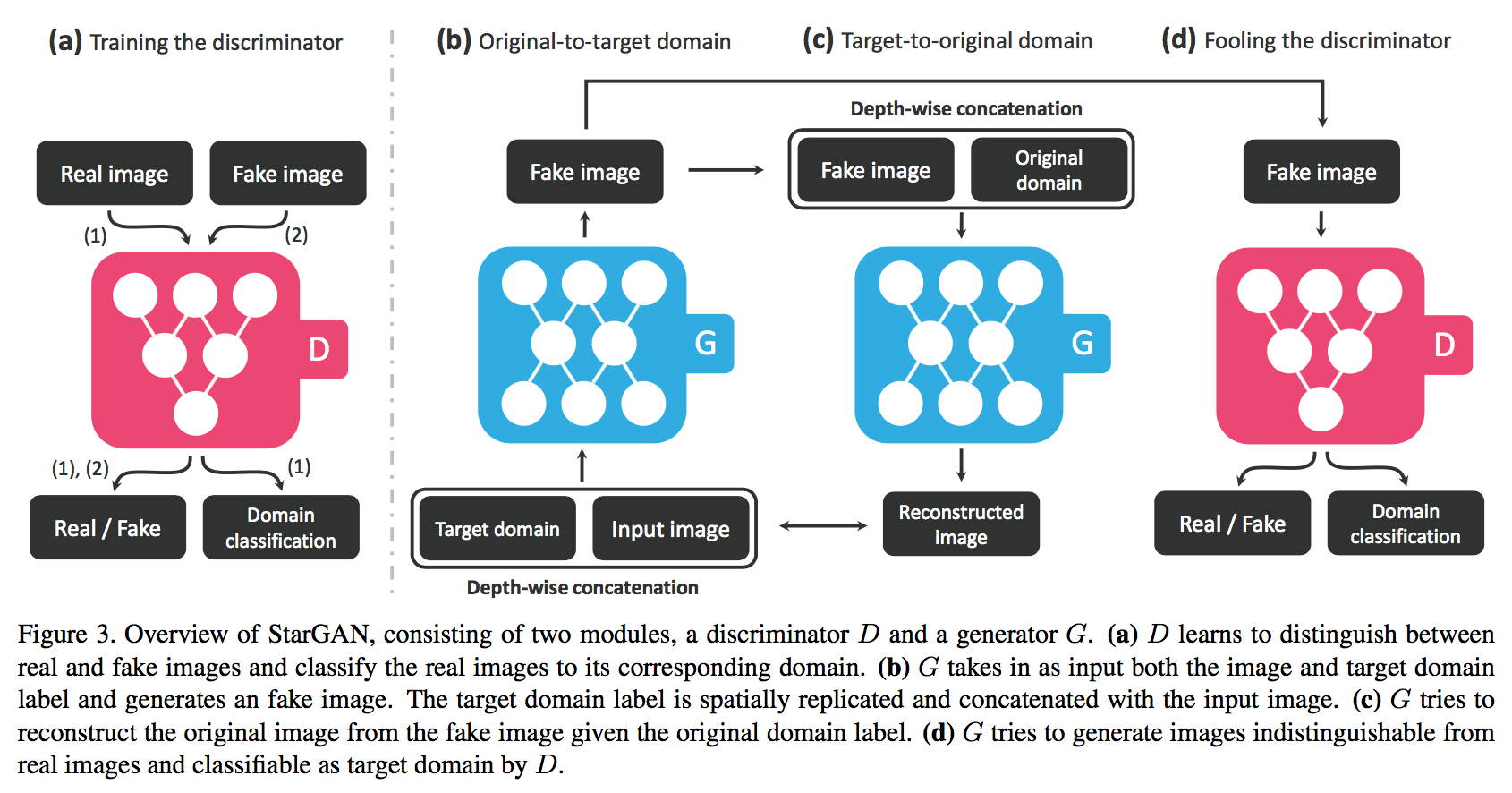
Adversarial Loss
图片真不真。
To make the generated images indistinguishable from real images.
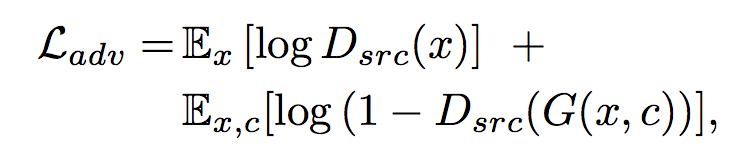
generates an image conditioned on both the input image and the target domain label .
tries to distinguish between real and fake images.
is a probability distribution over sources given by .
The generator tries to minimize this objective, while the discriminator tries to maximize it.
Domain Classification Loss
标签对不对。
- A domain classification loss of real images used to optimize D.
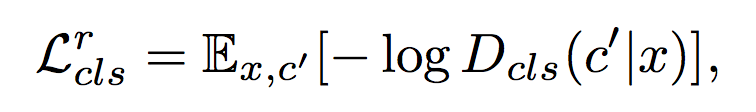
D_{cls}(c’|x) represents a probability distribution over domain labels computed by . By minimizing this objective, learns to classify a real image to its corresponding original domain c’.
We assume that the input image and domain label pair (x, c’) is given by the training data. - A domain classification loss of fake images used to optimize G.
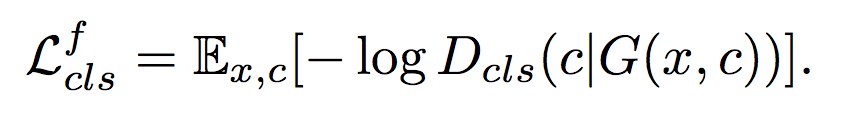
tries to minimize this objective to generate images that can be classified as the target domain .
Reconstruction Loss
保证只更改domain-related part。
有前两个loss,G is trained to generate images that are realistic and classified to its correct target domain.
然而,这两个不能保证translated images preserve the content of its input images while changing only the domain-related part of the inputs.
Apply a cycle consistency loss to the generator,
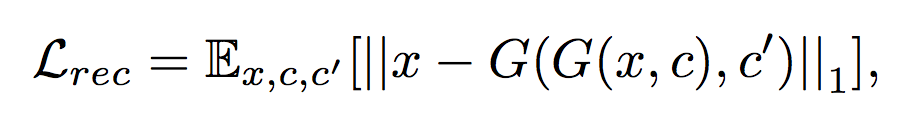
takes in the translated image and the original domain label c’ as input and tries to reconstruct the original image .
Adopt L1 norm as reconstruction loss.
Full Objective
The objective functions to optimize and is:
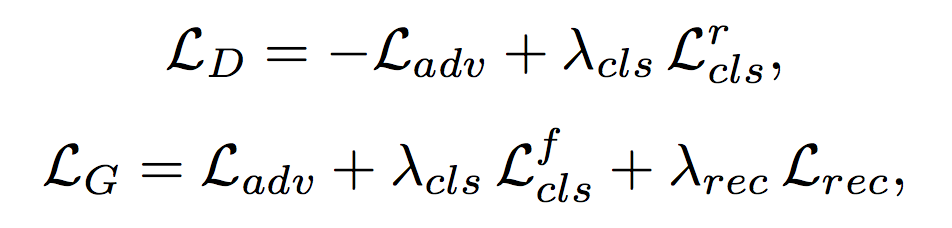
是hyper-parameter来调节各loss的比例。作者用和。
Training with Multiple Datasets
An issue when learning from multiple datasets, however, is that the label information is only partially known to each dataset. A有的B没有,B有的A没有。

Mask Vector
allows StarGAN to ignore unspecified labels and focus on the explicitly known label provided by a particular dataset.
, n-dimensional one-hot vector, n is the number of datasets.
, unified version of the label as a vector, c^~ = [c_1, …, c_n, m]. refers to concatenation, represents a vector for the labels of the i-th dataset. For the remaining n-1 unknown labels we simply assign zero values.
Training Strategy
作为generator的input。
Implementation
Improved GAN Training
To stabilize the training process and generate higher quality images, 改用Wasserstein GAN objective with gradient penalty.
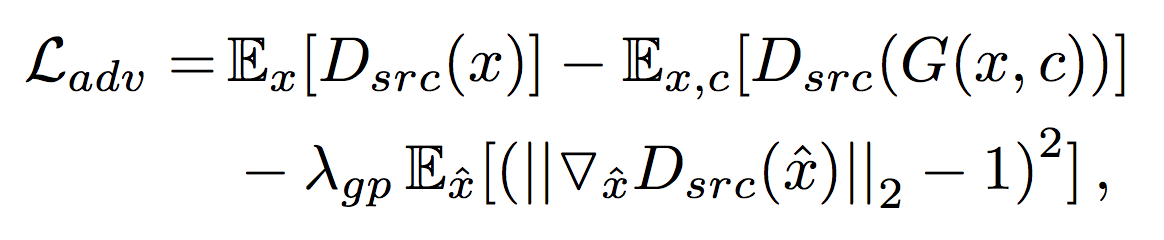
Where is sampled uniformly along a straight line between a pair of real and a generated images . We use for all experiments.
Network Architecture
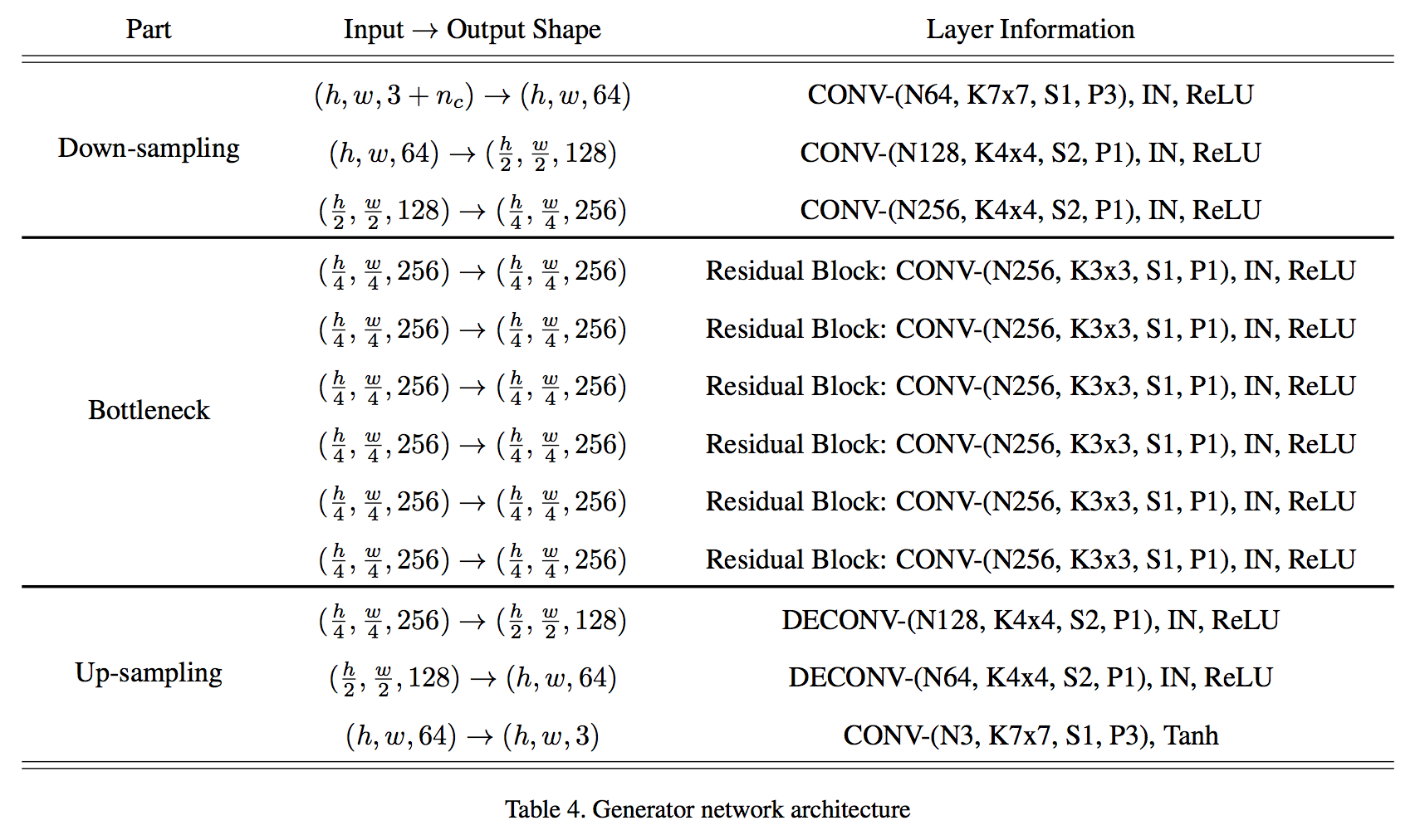
Generator network: two convolution layers with the stride size of two for downsampling, six residual blocks, and two transposed convolution layers with the stride size of two for upsampling. Instance normalization.
Discriminator network: PatchGANs, no normalization.

Experiments



Baseline Models
- DIAT uses an adversarial loss to learn the mapping from to , where x and y are face images in two different domains X and Y , respectively. This method has a regularization term on the mapping as ||x − F (G(x))||_1 to preserve identity features of the source image, where F is a feature extractor pretrained on a face recognition task.
- CycleGAN also uses an adversarial loss to learn the map- ping between two different domains X and Y . This method regularizes the mapping via cycle consistency losses, ||x−(G_{YX}(G_{XY}(x)))||_1 and ||y−(G_{XY}(G_{YX}(y)))||_1. This method requires two generators and discriminators for each pair of two different domains.
- IcGAN combines an encoder with a cGAN model. cGAN learns the mapping $G : {z, c} \rightarrow x $that generates an image conditioned on both the random noise and the conditional representation c. In addition, IcGAN learns the inverse mappings and . This allows to synthesize images conditioned on arbitrary conditional representation.
Datasets
- CelebA. 202,599 face images of celebrities, each annotated with 40 binary attributes. We crop the initial 178 × 218 size images to 178 × 178, then resize them as 128 × 128. We randomly select 2,000 images as test set and use all remaining images for training data. We construct seven domains using the following attributes: hair color (black, blond, brown), gender (male/female), and age (young/old).
- RaFD. 4,824 images collected from 67 participants. Each participant makes eight facial expressions in three different gaze directions, which are captured from three different angles. We crop the images to 256 × 256, where the faces are centered, and then resize them to 128 × 128.
Training
Adam
and .
For data augmentation we flip the images horizontally with a probability of 0.5.
One generator update after five discriminator updates as in Reconstruction Loss.
The batch size is set to 16 for all experiments.
For experiments on CelebA, we train all models with a learning rate of 0.0001 for the first 10 epochs and linearly decay the learn- ing rate to 0 over the next 10 epochs. To compensate for the lack of data, when training with RaFD we train all models for 100 epochs with a learning rate of 0.0001 and apply the same decaying strategy over the next 100 epochs.


Ref:
[1] https://arxiv.org/abs/1711.09020
[2] https://github.com/yunjey/StarGAN