论文 Dynamic Routing Between Capsules
Introduction
The amazing success of convolutional neural networks was the start of the new push to create AI. Now Geoffrey Hinton, Sara Sabour and Nicholas Frosst, members of Google’s Brain Team Toronto, have published results that reveal what might be an even better architecture - a Capsule Net.

Translation: 平移。
Affine transformations: 仿射变换。是指在几何中,一个向量空间进行一次线性变换并接上一个平移,变换为另一个向量空间。Reflect, Scale, Rotate, Shear, Stretching.
CNN applies the same smallish group of neurons with the same structure across the entire image.
CNN is good at detecting features but less effective at exploring the spatial relationships among features (perspective, size, orientation).
The problem with CNN is that they throw away too much information. They recognize a face as a collection of two eyes, a mouth and a nose, but they don’t keep the relationships between the parts.
A capsule network is designed to build a parse tree of the scene that does keep the relationships between the different parts.
Capsules and Routing

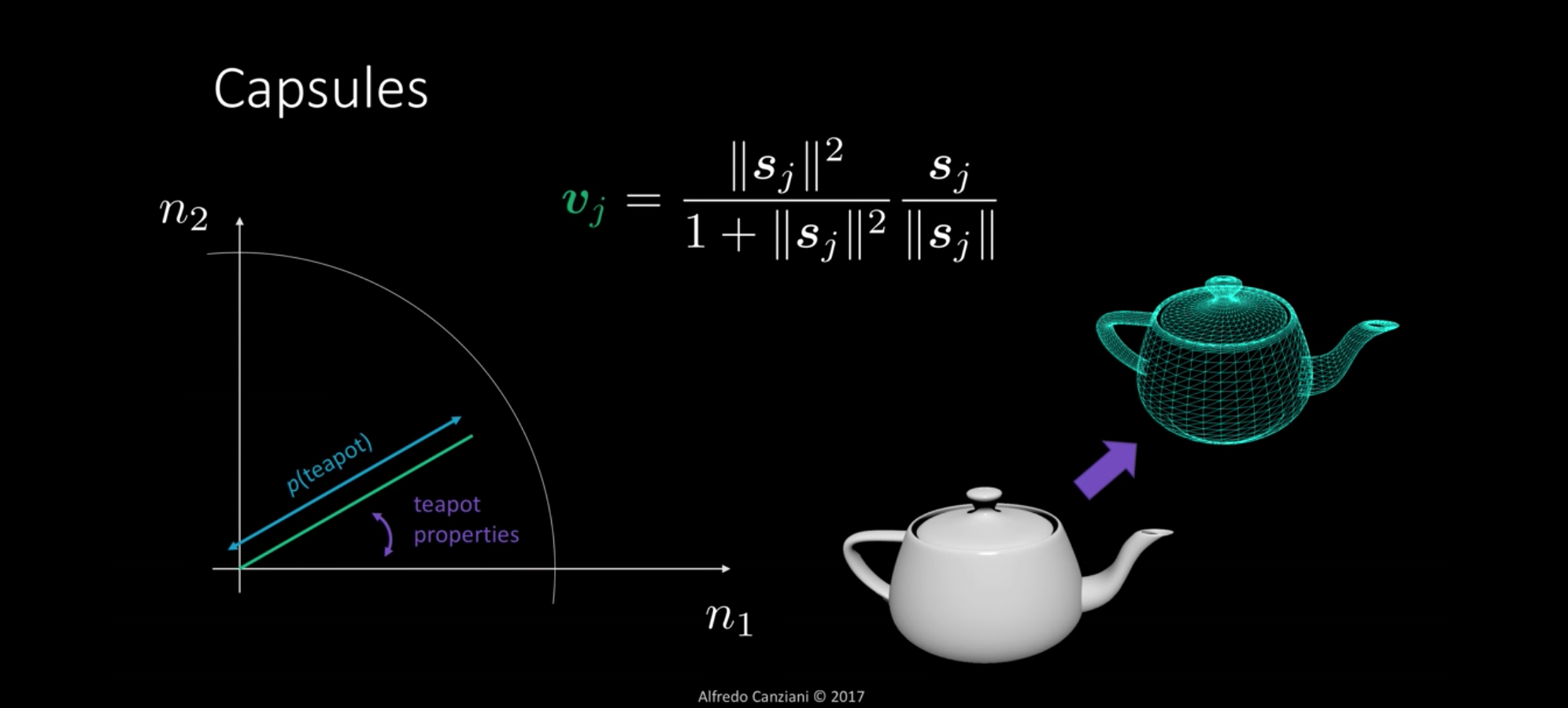
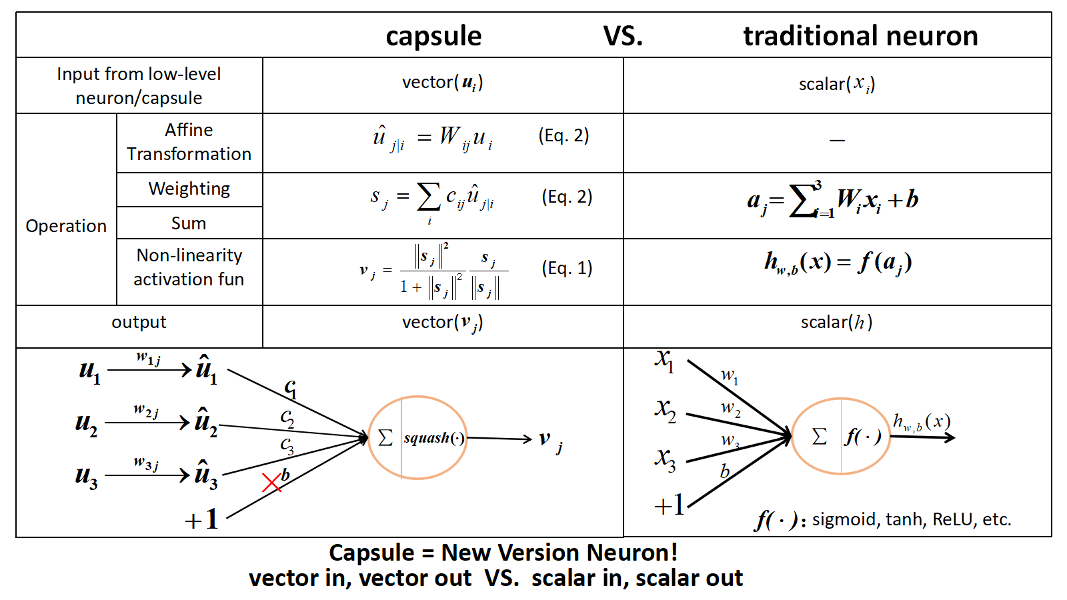
A capsule is a group of neurons that not only capture the likelihood but also the parameters of the specific feature.
Every capsule can be represented with a vector.
The angle of the vector represent the property of the specific item.
The length of the vector represent the probability of finding some specific entity in the input or in the previous layers. Range [0, 1].
Normalizing.
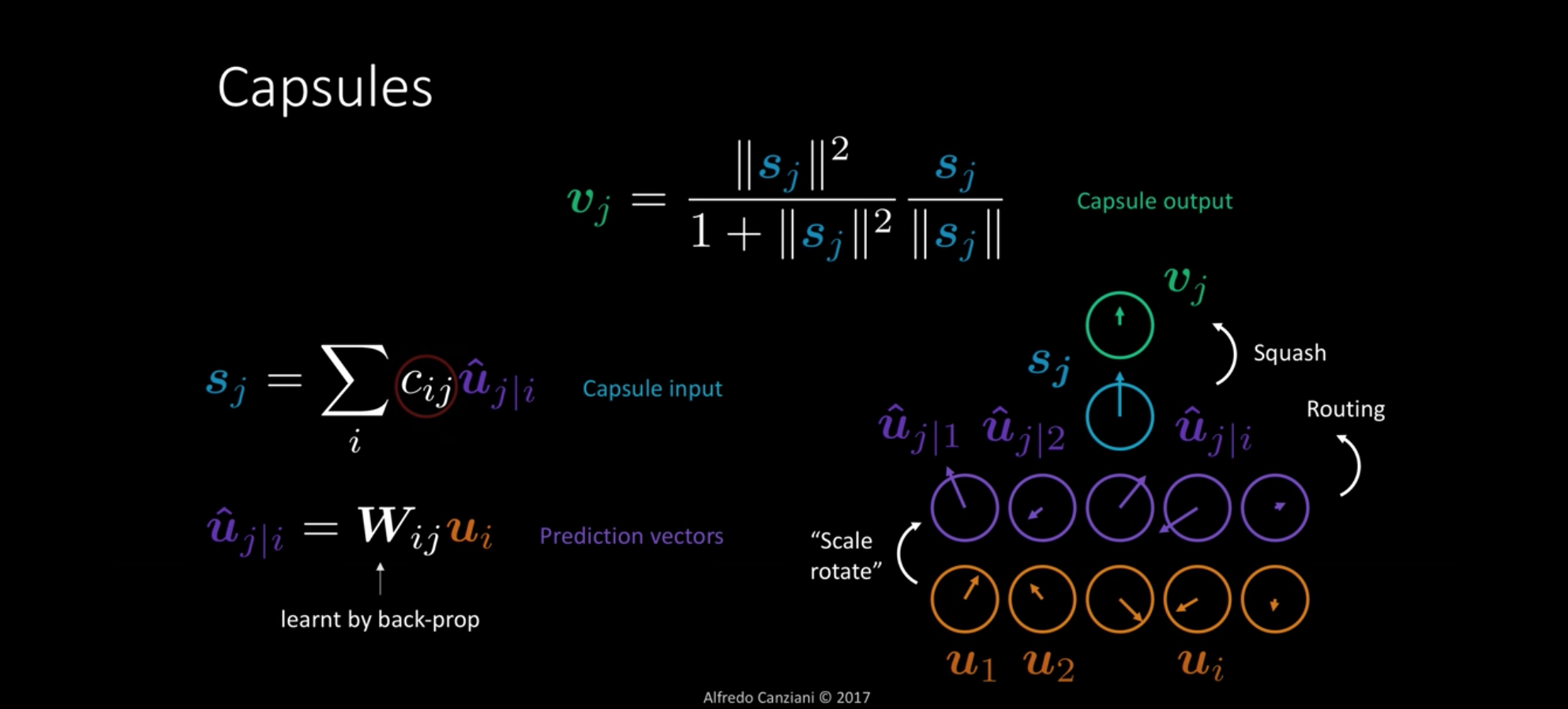
, capsule J. Capsule output.
, capsule input. A weighted average of those .
, prediction vectors which are generated from the capsules of the layer below.
S -> V, normalizing. Squash.
-> S, Routing. Basically averaging then out using those coefficients .
u -> , Scale rotate. learnt by back prop.
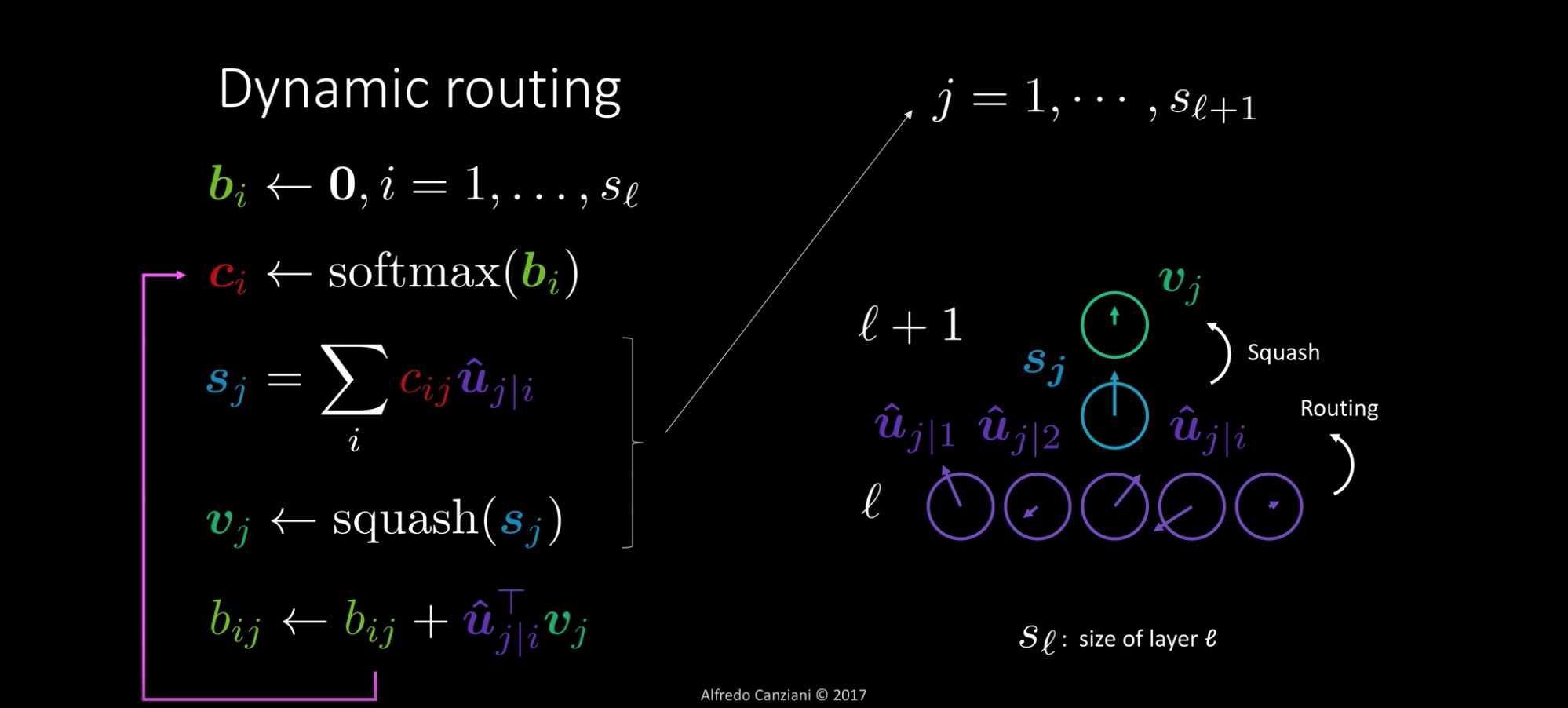
Name green layer L+1, purple layer L.
, coupling coefficient, how much lower layer capsules affect higher layer capsules.
, routing logists, is like the correlation between the capsules in the layer below and this one capsule in this layer. Routing-by-agreement. Dynamic.
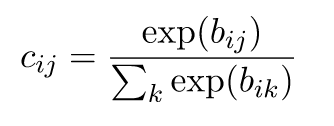
If we take an input of [1, 2, 3, 4, 1, 2, 3], the softmax of that is [0.024, 0.064, 0.175, 0.475, 0.024, 0.064, 0.175]. The output has most of its weight where the ‘4’ was in the original input. This is what the function is normally used for: to highlight the largest values and suppress values which are significantly below the maximum value.
The softmax is used in order to help to strengthen just the path from one capsule in the layer below to its own part, so it decides where to route itself through the network.
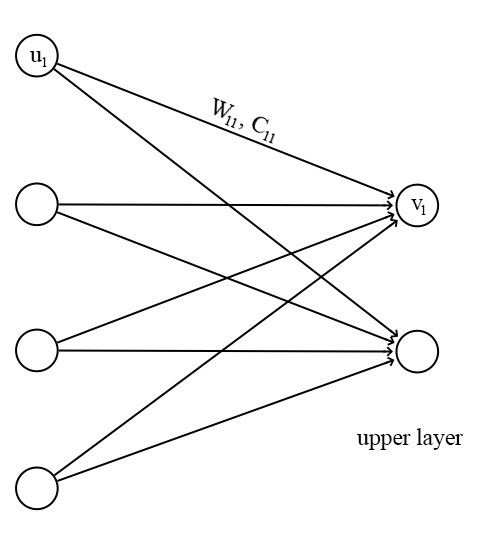
W trained by back propagation. C trained by dynamic routing.

Loss function
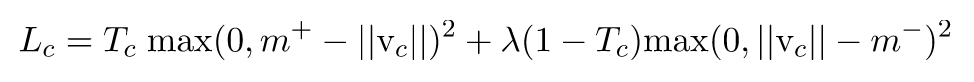
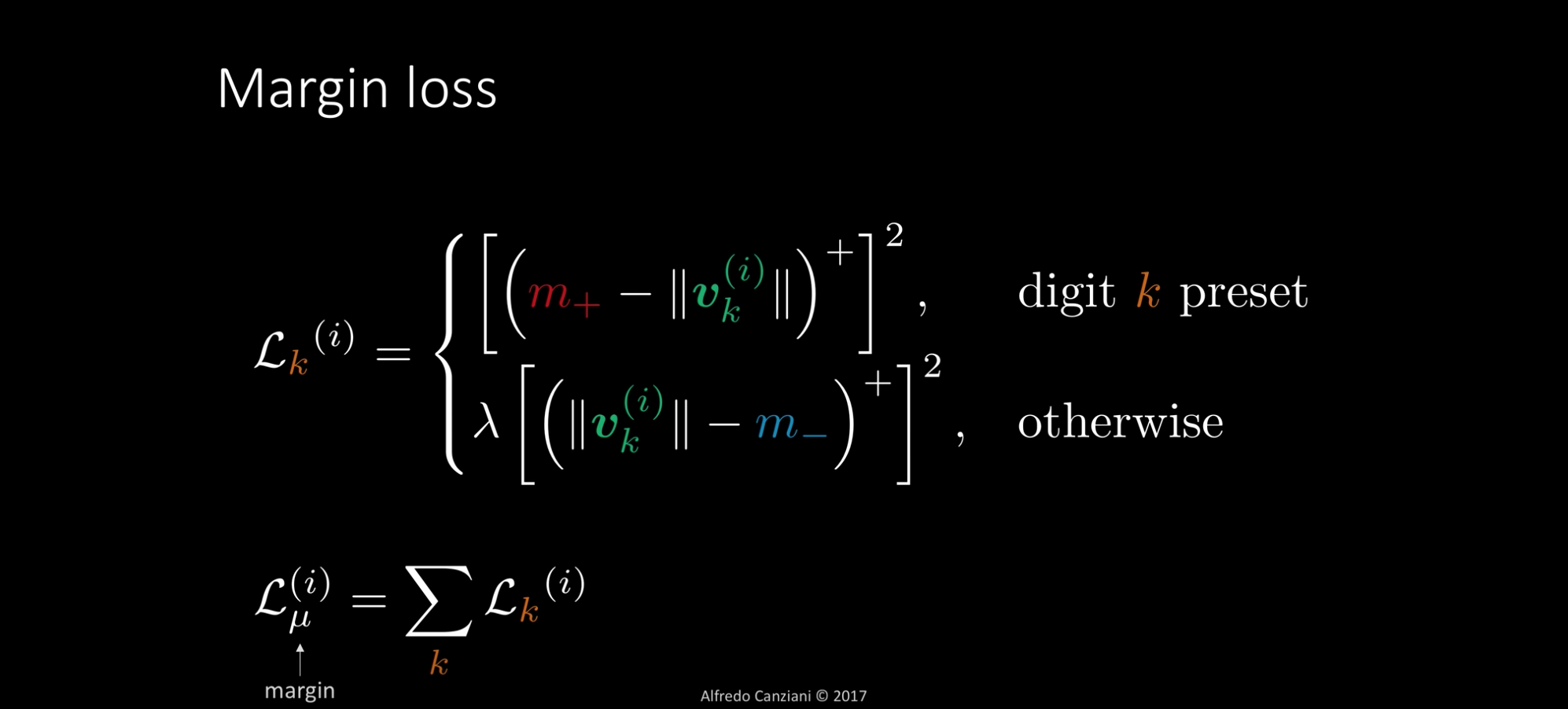
Margin loss in the output layer.
First row, the label of current sample is k. label正确时。
论文中,,并建议。
当,label为class k时,如果capsule k输出向量长度短于0.9,loss就大于0。反之,如果label不是k的其他class,如果capsule k的长度长于0.1,loss就大于0。
Architecture
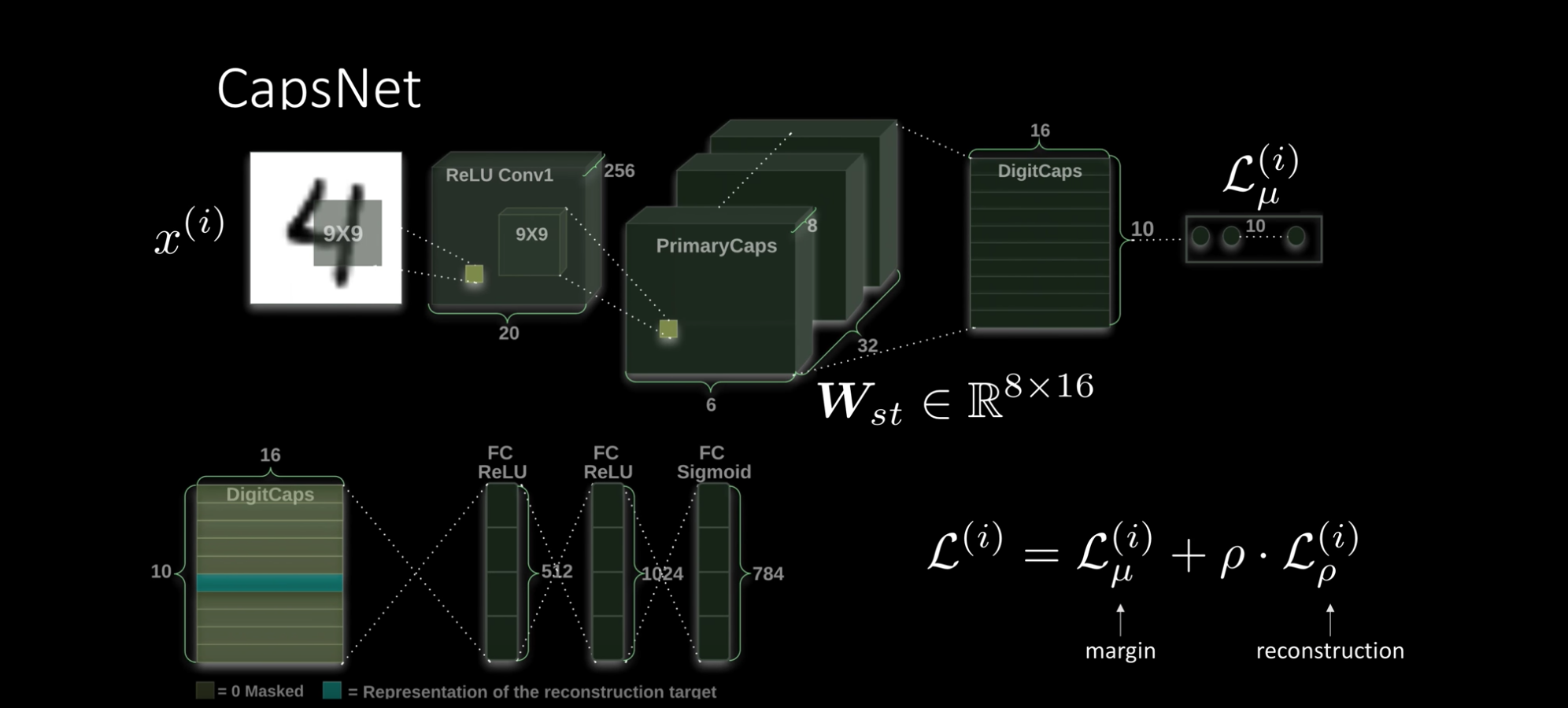
在MNIST dataset上实验。
首先采用两层Convolutional Layer对image内容进行特征提取,接着送进Primary Capsules,Primary Capsules再route给后一层的Digit Capsules,至此,这些Digit Capsules的输出已经可以由上面所述的Margin Loss进行训练,并根据capsule输出的向量长度进行预测了。
用capsule net还可以进行重建。Reconstruction regularizer。因为digit capsules的输出是向量,所以可以带有许多这个数字的特性(例如方向、角度、位置),所以在训练时可以新增一个regularization项,将当前sample的label class对应的capsule取出,并送进连续三层的fully-connected layers重建出原本的image。
Loss function中的reconstruction是fully-connected layer输出与原image的L2 loss,为了避免过度影响到digit capsules本身的loss,乘了0.0005的系数。
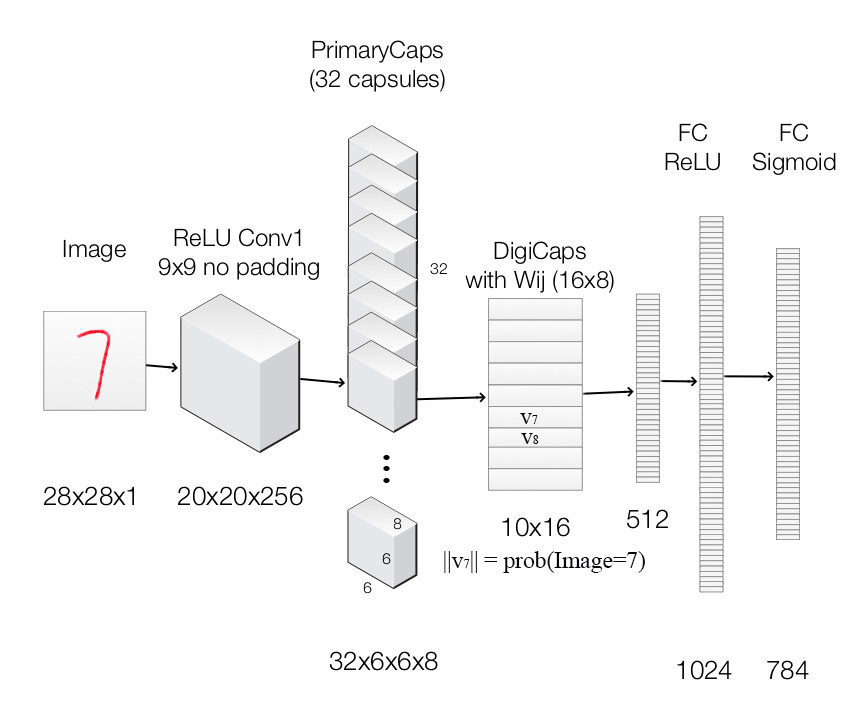
Image is feed into the ReLU Conv1 which is a standard convolution layer. It applies 256 9x9 kernels to generate an output with 256 channels (feature maps). With stride 1 and no padding, the spatial dimension is reduced to 20x20. ( 28-9+1=20).
It is then feed into PrimaryCapsules which is a modified convolution layer supporting capsules. It generates a 8-D vector instead of a scalar. PrimaryCapsules used 8x32 kernels to generate 32 8-D capsules. (i.e. 8 output neurons are grouped together to form a capsule) PrimaryCapsules uses 9x9 kernels with stride 2 and no padding to reduce the spatial dimension from 20x20 to 6x6 ([(20 - 9) / 2] + 1 = 6). In PrimaryCapsules, we have 32x6x6 capsules.
It is then feed into DigiCaps which apply a transformation matrix with shape 16x8 to convert the 8-D capsule to a 16-D capsule for each class j (from 1 to 10).
Because there are 10 classes, the shape of DigiCaps is 10x16 (10 16-D vector.)

Results
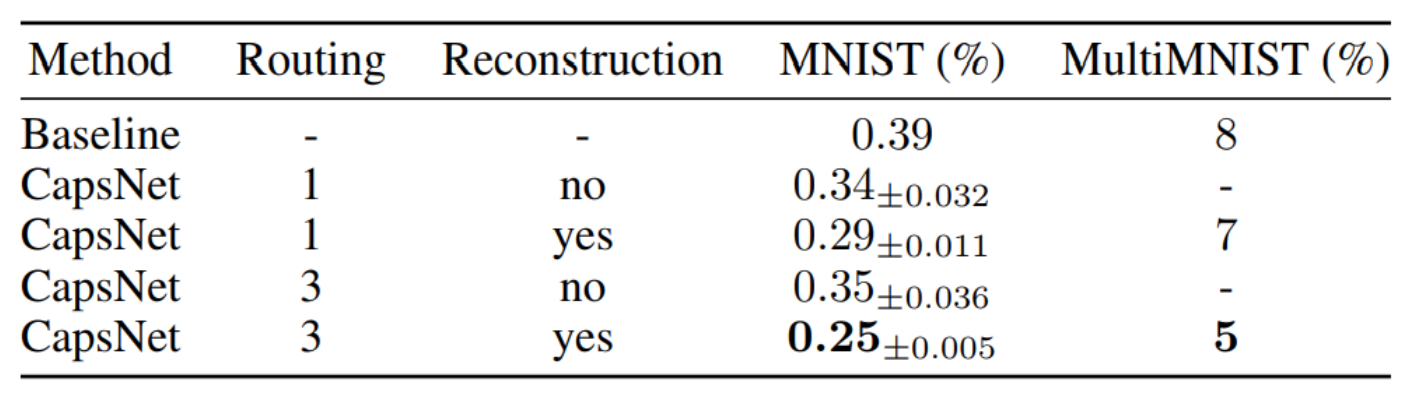
Routing是前面训练时的iteration r值。
baseline是3层CNN,分别255,255,125个channel,与两层fully-connected layer,分别328,192个node。
作者的结论是:
- 使用CapsNet得到了相当低的test error,这过往需要较深的CNN model才能达到。
- 这证明了routing与reconstruction regularizer的重要性。
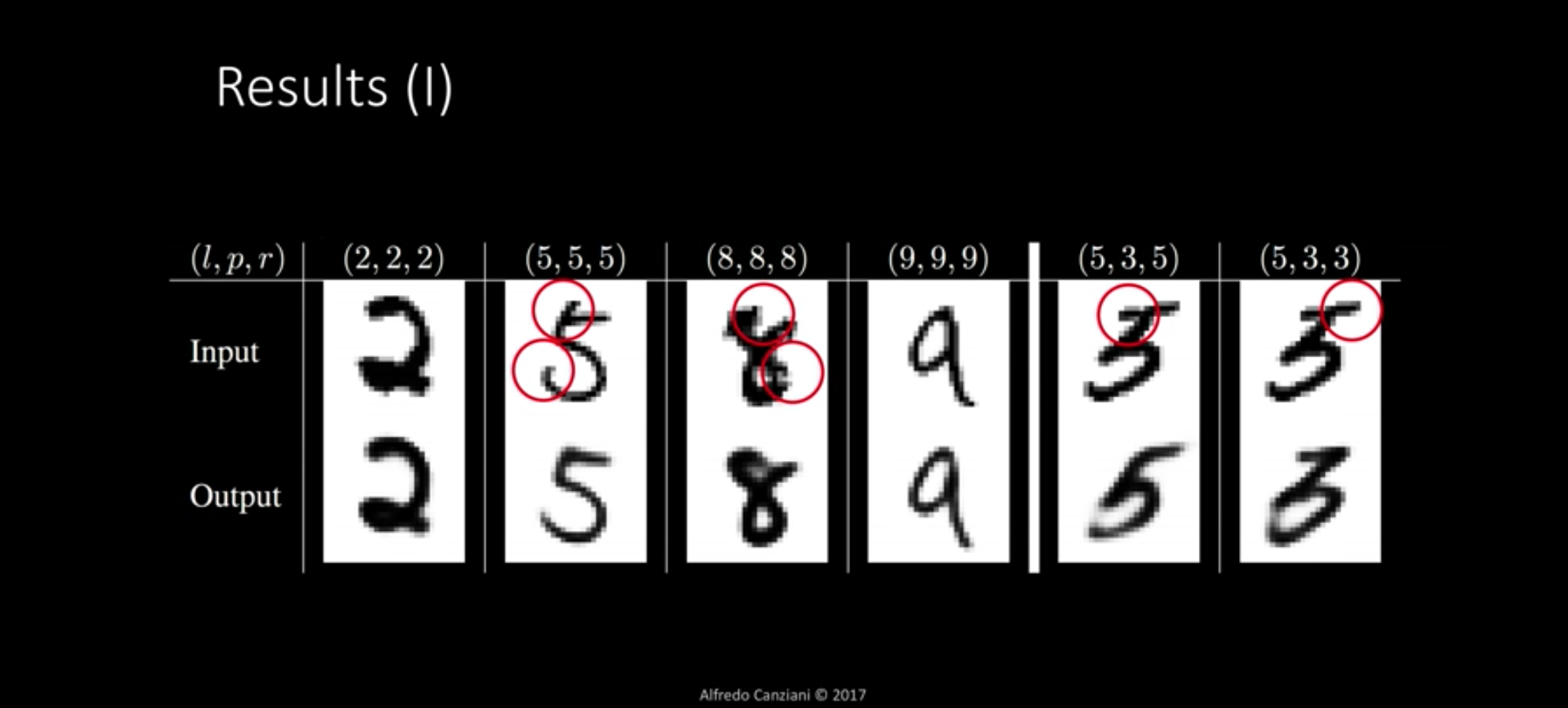
Label, prediction, reconstruction
最右边的两个sample是预测错误的例子。
此外,也可以把digit capsule的输出向量进行一些修改再reconstruction。

Dynamic Routing其实可以视为一种attention机制。上层的capsule只会接受有相关性的下层capsule输入,这可以帮助CapsNet处理严重重叠的数字。

L为label,R为Reconstruction Class。CapsNet在预测时会固定取长度最长的两个digit capsules,并使用其输出向量进行重建。
在accuracy/error rate上,CapsNet并没有太大进展,但其输出向量有更好解释型,也能携带更多资讯,并透过reconstruction regularizer可以简单视觉化预测时的错误原因。Routing-by-agreement本身等于自带attention。
Reconstruction Regularizer会倾向考虑整张图像中的所有东西。
Ref:
[1] https:/www.youtube.com/watch?v=EATWLTyLfmc
[2] Capsule Nets - The New AI
[3] 一起讀 Dynamic Routing Between Capsules | Learning by Hacking
[4] “Understanding Dynamic Routing between Capsules (Capsule Networks)”
[5] GitHub - naturomics/CapsNet-Tensorflow: A Tensorflow implementation of CapsNet(Capsules Net) in Hinton’s paper Dynamic Routing Between Capsules
[6] https:/github.com/jhui/machine_learning/tree/master/capsnet-keras
[7] 1710.09829 Dynamic Routing Between Capsules