Linear Model 线性模型
Linear Model (The model is specified as a linear combination of features.) 。
注:下述这些都属于linear model。
- Linear Regression
- Support Vector Machine (linear Kernel)
- Perceptron with linear activation function
- Naive Bayes Model based on its constraints
- Linear Discriminant Analysis (Fisher’s Discriminant Analysis)
- Logistic Regression (only when we are using this model for maximum likelihood estimation)
Linear Regression 线性回归
Logistic Regression 对数几率回归
Generalized Linear Model 广义线性模型
Generalized Linear Model 广义线性模型
Linear Discriminant Analysis 线性判别分析
Linear Discriminant Analysis 线性判别分析
多分类学习
利用二分类学习器来解决多分类问题的策略。
考虑 N 个类别 C1, C2, …, CN,多分类学习的基本思路是拆解法,即将多分类任务拆为若干个二分类任务求解。
关键是如何对多分类任务进行拆分,有如何将这些预测结果进行集成。
拆分策略:
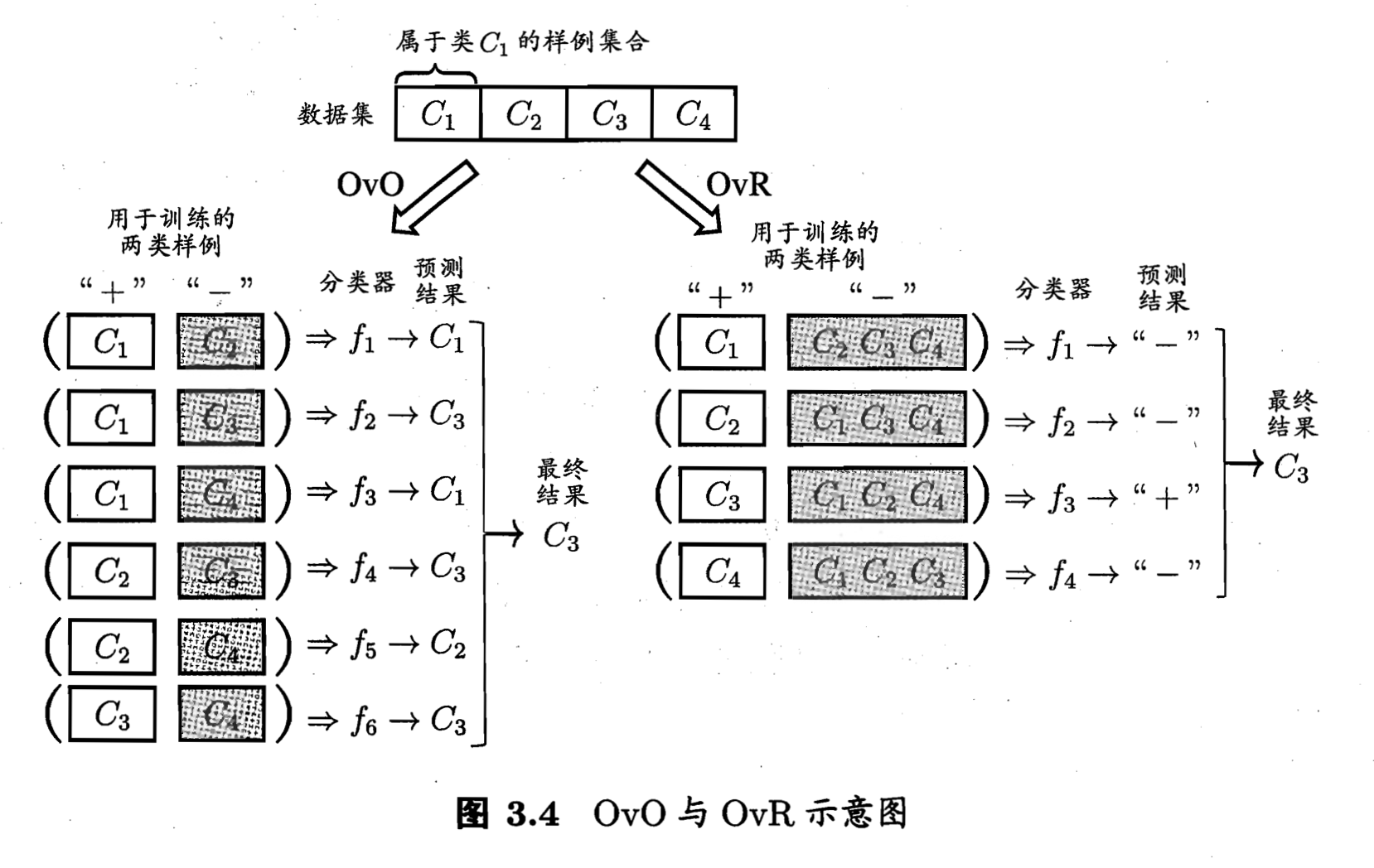
- One vs. One 一对一。
将 N 个类别两两配对,从而产生个二分类任务。训练时使用这两类的样本数据,测试时新数据提交给所有分类器,投票选最可能的结果。
存储开销和测试时间开销大。训练时间开销小。 - One vs. Rest 一对其余
每次将一个类的样例作为正例、所有其他类的样例作为反例来训练 N 个分类器。测试时如果仅有一个分类器预测为正类,就选它;如果有多个分类器预测为正类,则通常考虑各个分类器的预测置信度,选择置信度最大的类别。
存储开销和测试时间开销小。训练时间开销大。 - Many vs. Many 多对多
每次将若干个类作为正类,若干个其他类作为反类。OvO 和 OvR 都是 MvM 的特例。
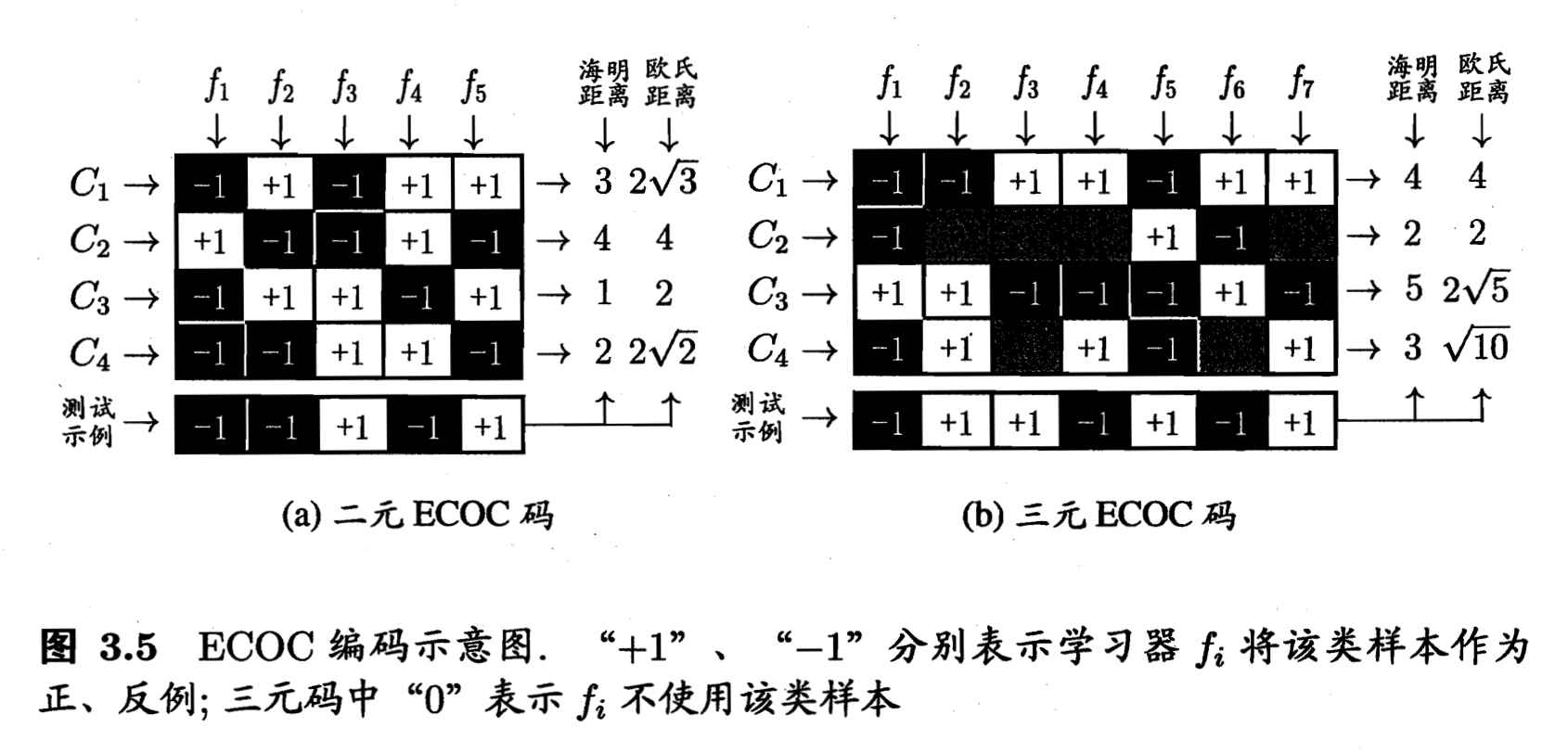
常用 MvM 技术:纠错输出码 Error Correcting Output
两步:- 编码:对 N 个类别做 M 次划分,每次划分将一部分类别划分正类,一部分划为反类,形成一个二分类训练集;这样一共产生 M 个训练集,训练 M 个分类器。类别划分通过 code matrix 指定,分二元码(正反)和三元码(正反停)。ECOC 编码越长,则所需训练的分类器越多。
- 解码:M 个分类器分别对测试样本进行预测,这些预测标记组成一个编码,这个预测吗与各个类别各自的编码比较,返回其中距离最小的类别。
类别不平衡问题
例如有998个反例,2个正例,很容易训练处一个永远预测反例的学习器。
类别不平衡 class-imbalance 是指分类任务中不同类别的训练样例数差别很大的情况。
方法:再缩放。
以线性模型做例子,阈值0.5相当于预期正例的可能性与反例的可能性相同。因此,当正反例比例不同时,预测几率高于观测几率就应该判定为正例,即,乘到左边变为>1的形式。
- 欠采样法 undersampling。去除一些反例使得正反例数目相近。时间开销小,可能丢信息。EasyEnsemble 算法利用集成学习机制,将反例划分为若干个集合供不同学习器使用,这样对每个学习器来看都进行了欠采样单全局未丢失信心。
- 过采样 oversampling。增加一些正例。直接重复采样会过拟合。SMOTE 算法通过对训练集里的正例进行差值来产生额外的正例。
- 阈值移动 threshold-moving。用原始数据训练,但预测时使用上式。
库
scikit-learn
Vowpal Wabbit
Ref
[1] 机器学习 - 周志华