Linear Regression
将样本点拟合到一条(n维的)直线(超平面)上。线性方程。
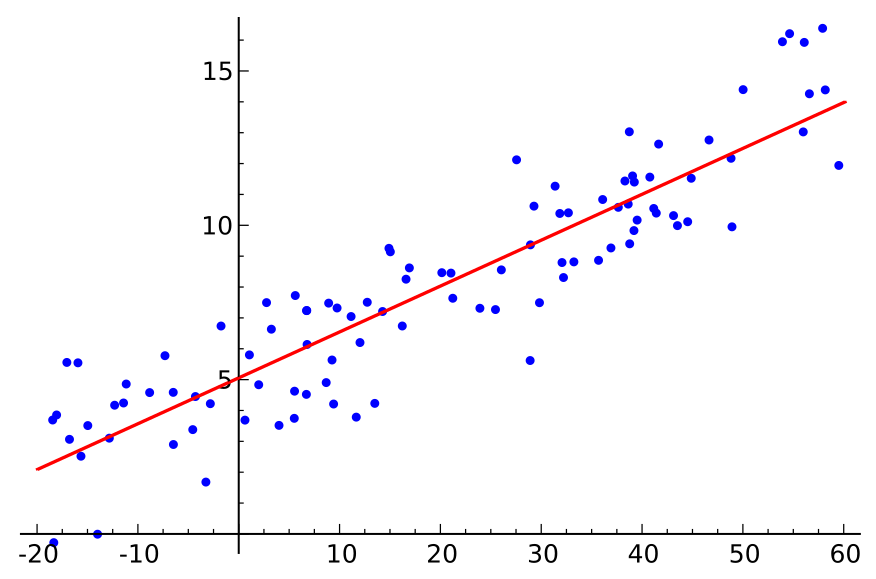
适用问题:回归任务
适用数据类型:
优点:简单易懂,易解释。加上正则项可以避免过拟合。有新数据时可以用SGD更新模型。
缺点:不适于非线性关系。
模型-知识表示:线性方程
模型-目标策略:最小化均方误差,最小二乘法
模型-损失函数:均方误差
模型-优化算法:直接求导;随机梯度下降;
标签:Linear Model,
线性回归是最被广泛应用的建模技术之一。顾名思义,就是用一组变量(或特征)的线性组合,来建立与结果的关系。即期望用一条**最佳的直线(被称为回归线)**来表示因变量(Y)和一个或多个自变量(X)之间的关系。
线性回归模型
模型表达
y(x,w)=w0+w1x1+…+wnxn
其中,x1,x2,…,xn表示自变量(集合);y是因变量;w为参数向量;wi表示对应自变量(特征)的权重。
通过每个特征前面的参数,可以直观看出哪些特征分量对结果的影响比较大。
写成向量形式,令x0=1,y(x,w)=hw(x):
hw(x)=i=0∑nwixi=wTx
其中 w=(w0,w1,…,wn),x=(1,x1,x2,…,xn)均为向量,wT为w的转置。
注意,这里假设了特征空间与输入空间x相同。
准确的讲,模型表达式要建立的是特征空间与结果之间的关系。在一些应用场景中,需要将输入空间映射到特征空间,然后建模。特征映射相关技术,包括特征哈希、特征学习、Kernel等。
参数学习准则
求参数w,使得hw(x)最佳。直观认为其与真实值y相差越小越好。
Cost Function,差的平方和:
J(w)=21i=1∑m(hw(x(i))−y(i))2
minwJ(w)
即
w^∗=argw^min(y−Xw^)T(y−Xw^)
参数学习 - 线性回归目标函数
两种经典方法:直接求导,梯度下降法
直接求导
直接求导,直接给出闭式解结果。它用X表示观测数据中的特征矩阵,结果表示成Y向量,目标函数仍是上述 cost function。那么w可直接用下面公式表示(求导为0时解得):
w=(XTX)−1XTY
梯度下降法 Gradient Descent
直接求导,求奇异点。但在互联网海量数据背景下计算效率较低,甚至无法完成。
而基于梯度法求解参数是一个不错的选择,原因主要有2点:
- 算法复杂度与样本规模(样本数m、特征维度n)呈线性关系;
- 如果目标函数是凸函数,批梯度法可保证能得到最优解,随机梯度法也能近似得到最优解。
Gradient descent: 此处θ即w。
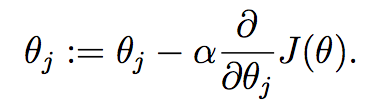
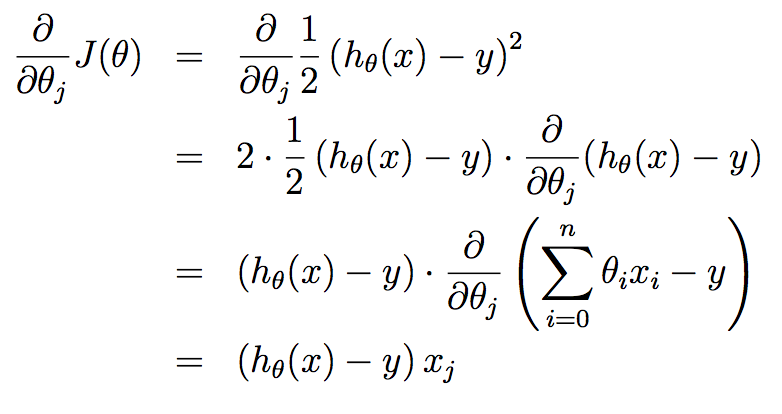
Least mean squares update rule:
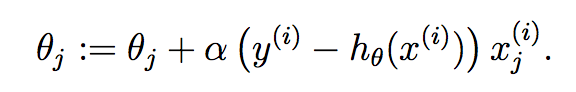
Batch gradient descent:
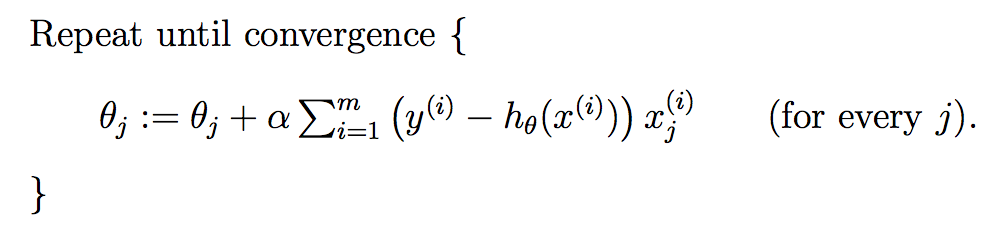
Stochastic gradient descent:
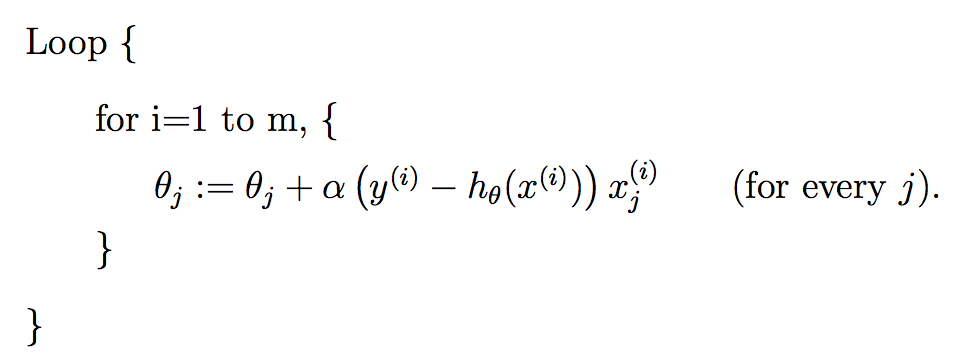
直接求导与梯度下降法求解异同
- 相同点
本质相同:两种求解方法都是在给定已知数据(自变量x,因变量y)的前提下对因变量y算出一个估值函数(x与y关联表达式),然后对给定的新输入x通过估值函数得出y。
目标相同:都是在已知数据的框架下,使得估算值与真实值的之差的平方和尽可能小。
- 不同点
实现方法与结果不同:直接求导直接通过建立等价关系找到全局最小,非迭代法。而梯度下降法作为迭代法的一种,先给定一个参数向量初始值,然后向目标函数下降最快的方向调整(即梯度方向),在若干次迭代之后找到全局最小。
相比直接求导,随机梯度下降法的一个缺点是:在接近极值时收敛速度变慢,并且该方法对初始值的选取比较敏感。
概率解释 - 回归模型目标函数
一般地,机器学习中不同的模型会有相应的目标函数。而回归模型(尤其是线性回归类)的目标函数通常用平方损失函数作为优化的目标函数(即真实值与预测值之差的平方和)。为什么要选用误差平方和作为目标函数呢?答案可以从概率论中的中心极限定理、高斯分布等知识中找到。
中心极限定理
目标函数的概率解释需要用到中心极限定理。中心极限定理本身就是研究独立随机变量和的极限分布为正态分布的问题。
中心极限定理公式表示:
设n个随机变量X1,X2,…,Xn相互独立,均具有相同的数学期望与方差,即E(Xi)=μ,D(Xi)=σ2。令Yn为随机变量之和,有
Yn=X1+X2+…+Xn
Zn=√D(Yn)Yn−E(Yn)=√nσYn−nμ→N(0,1)
称随机变量Zn为n个随机变量X1,X2,…,Xm的规范和。
中心极限定理定义:
设从均值为μ、方差为σ^2(有限)的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值的抽样分布[n1Yn]近似服从于均值为μ、方差为σ^2的正态分布。
高斯分布
假设预测值与真实值之间的误差为ϵ(i),即
y(i)=wTx(i)+ϵ(i)
此处误差可以假设服从标准高斯分布,因为:
回归模型的最终目标是建立自变量x与结果y之间的关系(通过函数表达式),希望通过x能较准确的表示结果y。
而在实际应用场景中,很难甚至不可能把导致y结果的所有变量(特征)都找出来,并放到回归模型中。那么模型中存在的x通常认为是影响结果y最主要的变量集合(又称因子, 在ML中叫做特征集)。根据中心极限定理,把那些对结果影响比较小的变量(假设独立同分布)之和认为服从正态分布是合理的。
即
p(ϵ(i))=√2πσ1exp(−2σ2(ϵ(i))2)
那么,x和y的条件概率可以表示为:
p(y(i)∣x(i);w)=√2πσ1exp(−2σ2(y(i)−wTx(i))2)
极大似然估计与损失函数极小化等价
模型的最终目标是希望在全部样本上预测最准,也就是概率积最大,这个概率积就是似然函数。优化的目标的函数即为似然函数,根据上式,表示如下:
wmaxL(w)=i=1∏m√2πσ1exp(−2σ2(y(i)−wTx(i))2)
对 L(x)取对数,得到:
wmaxl(w)=−m⋅log√2πσ−2σ21i=1∑m(y(i)−wTx(i))2
由于n,σ是常数,所以上式等价为:
wmin21i=1∑m(y(i)−wTx(i))2
我们可以发现,经过最大似然估计推导出来的待优化的目标函数与平方损失函数是等价的。因此,可以得出结论:
线性回归 误差平方损失极小化与极大似然估计等价。其实在概率模型中,目标函数的原函数(或对偶函数)极小化(或极大化)与极大似然估计等价,这是一个带有普遍性的结论。
为什么是条件概率?
因为我们希望预测值与真实值更接近,这就意味着希望求出来的参数w,在给定输入x的情况下,得到的预测值等于真实值的可能性越大越好。而w,x均是前提条件,因此用条件概率p(y∣x;w)表示。即p(y∣x;w)越大,越能说明估计的越准确。(当然也不能一味地只优化该条件概率,还要考虑拟合过度以及模型的泛化能力问题)
Ref
[1] What is the linear model in machine learning? - Quora
[2] How to Learn a Machine Learning Algorithm
[3] Linear regression - Wikipedia
[4] 机器学习 - 周志华
[5] http://www.52caml.com/head_first_ml/ml-chapter1-regression-family/#线性回归(Linear_Regression)
[6] cs229