#include <algorithm> #include <iostream> void neg_before_pos(int* A, int n) { // puts negative elements before positive (and zeros, if any) in an array // input: array A[0..n-1] of real numbers // output: array A[0..n-1] in which all its negative elements precede nonnegative if (!A || n < 2) return; int i(0), j(n-1); while (i <= j) { if (A[i] < 0) {++i;} // shrink the unknown section from the left else{ std::swap(A[i], A[j]); --j; } } } int main() { neg_before_pos(NULL, 0); int A[7] = {5,-5,1,0,0,-2,-3}; neg_before_pos(A, 7); for (int i = 0; i < 7; ++i) { std::cout << A[i] << " "; } system("Pause"); }
#include <algorithm> #include <iostream> void dutch_flag(char* A, int n) { // sorts an array with values in a three-element set // input: an array A[0..n-1] of characters from {R,W,B} // output: array A[0..n-1] in which all its R elements precede all its W elements that precede all its B elements if (!A || n < 2) return; int r(0), w(0), b(n-1); while (w <= b) { if (A[w] == 'R') { std::swap(A[r], A[w]); ++r; ++w; }else if (A[w] == 'W') { ++w; }else { std::swap(A[w], A[b]); --b; } } } int main() { dutch_flag(NULL,0); char A[7] = {'B','W','B','R','W','R','W'}; dutch_flag(A,7); for (int i = 0; i < 7; ++i) { std::cout << A[i] << " "; } system("Pause"); }
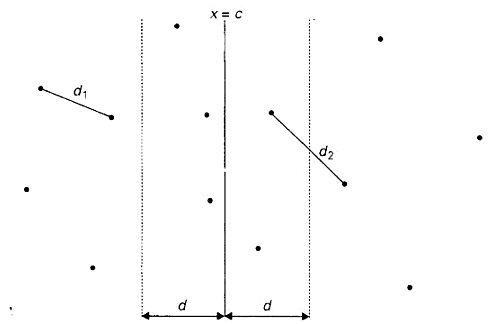
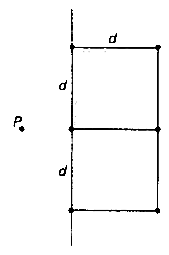
#include <vector> #include <iterator> #include <iostream> #include <algorithm> using namespace std; // structure of point struct Point { float m_x; float m_y; Point (float x, float y) : m_x(x), m_y(y){} void print_point() { std::cout << "(" << m_x << "," << m_y << ")"; } }; // calculate pow of distance of two points float distance(Point* a, Point* b) { if (!a || !b) return FLT_MAX; return pow((a->m_x - b->m_x), 2.0f) + pow((a->m_y - b->m_y), 2.0f); } // when points are less than four use brute force way float brute_force_nearest_pair(std::vector<Point*>::iterator start, std::vector<Point*>::iterator end, std::pair<Point*, Point*>& nearest) { if (end - start < 1) return FLT_MAX; float md(FLT_MAX); for (auto i = start; i <= end-1; ++i) { for (auto j = i+1; j <= end; ++j) { float d(distance(*i, *j)); if (d < md) { md = d; nearest.first = *i; nearest.second = *j; } } } return md; } // divide and conquer way to find nearest pair of points float find_nearest_pair(std::vector<Point*>::iterator start, std::vector<Point*>::iterator end, std::pair<Point*, Point*>& nearest) { // less than 4, brute force if (end - start <= 3) {return brute_force_nearest_pair(start, end, nearest);} // find mid number of points std::vector<Point*>::iterator mid(start); advance(mid, (end - start)/2); // divide into two parts std::pair<Point*, Point*> n1, n2; float d1(find_nearest_pair(start, mid-1, n1)); float d2(find_nearest_pair(mid, end, n2)); // get min of both parts: d float d(min(d1, d2)); // record nearest and min distance nearest = d1 > d2 ? n2 : n1; float md(d); // find all points in S2 which is close to mid point with distance less than d std::vector<Point*> close_to_mid_points_in_s2; for (auto i = mid; i <= end; ++i) { if ((*i)->m_x - (*mid)->m_x <= d) { close_to_mid_points_in_s2.push_back(*i); } } // for all points p in S1 find if there are points in close S2 collection that have distances with p less than d for (auto i = start; i <= mid-1; ++i) { if ((*mid)->m_x - (*i)->m_x <= d) { for (auto j = close_to_mid_points_in_s2.begin(); j < close_to_mid_points_in_s2.end(); ++j) { float temp(distance(*i, *j)); if ( temp < md) { // update mid distance and nearest points pair md = temp; nearest.first = *i; nearest.second = *j; } } } } // return final mid distance return md; } int main() { std::vector<Point*> points; Point a(0,1), b(0,11), c(0,3), d(0,10), e(0,6); points.push_back(&a); points.push_back(&b); points.push_back(&c); points.push_back(&d); points.push_back(&e); // sort points collection according to value of coordinate y. sort(points.begin(), points.end(), [](Point* a, Point* b){return a->m_y < b->m_y;}); std::pair<Point*, Point*> nearest; float dist = find_nearest_pair(points.begin(), points.end()-1, nearest); std::cout << "distance: " << sqrt(dist) << std::endl; std::cout << "points: "; nearest.first->print_point(); std::cout << ", "; nearest.second->print_point(); std::cout << std::endl; system("Pause"); }