论文 Low Resolution Face Recognition Using a Two-Branch Deep Convolutional Neural Network Architecture
Introduction
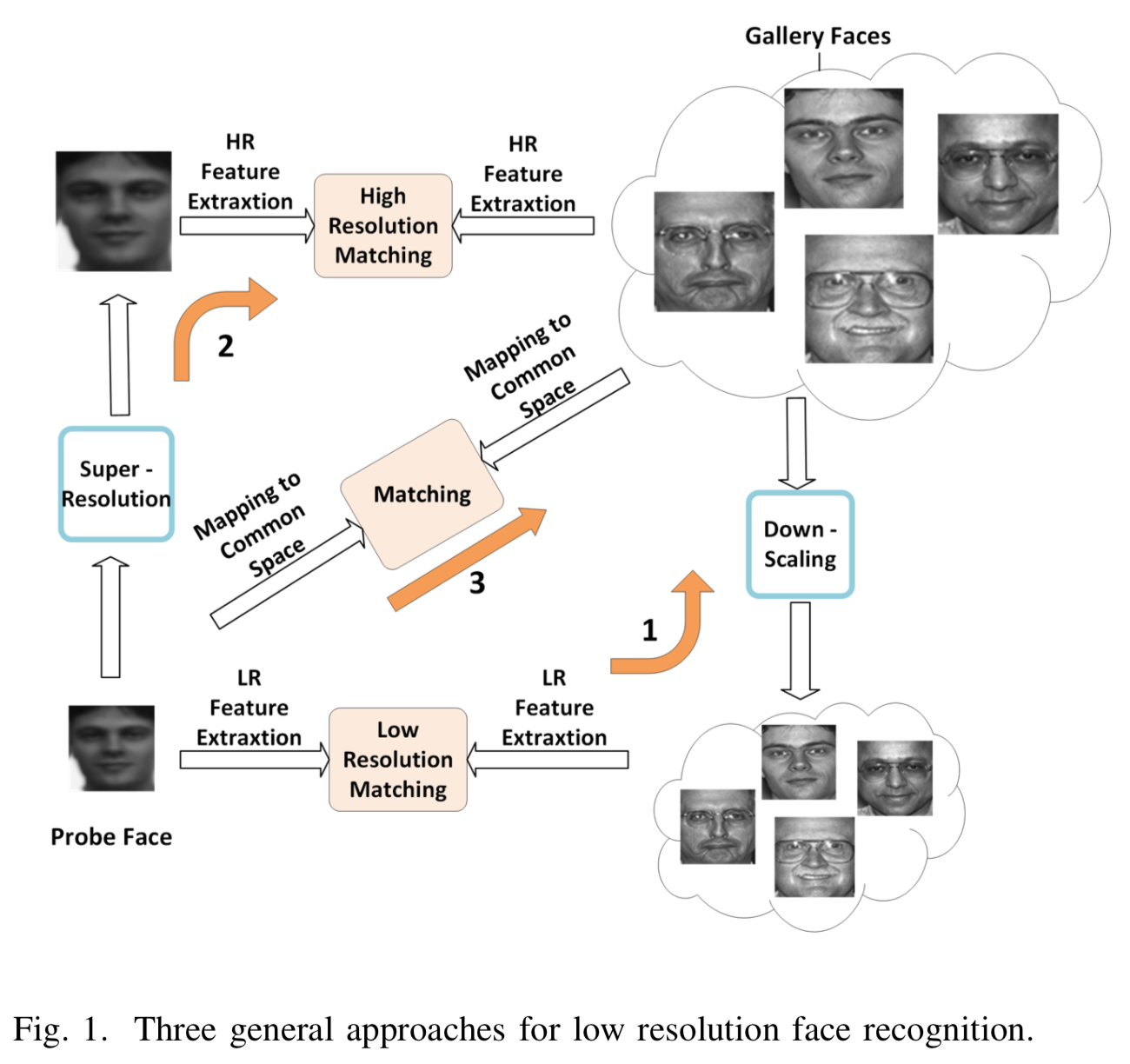
对于待识别人脸图像为低像素 LR probe image,训练数据为高像素 HR gallary image 的情况,常见的处理方式:
- 训练数据也 down-sampling 到低像素。丢失有用信息。
- 从低像素的目标人脸图像生成高像素数据用于识别。对应方法关注点往往在于生成图像的质量,而非人脸识别的性能。[10]-[13]
- 将 LR probe image 和 HR gallary image 同时转换到一个共同空间,使两者距离接近。[14]-[17] 这篇论文采取的方式。
此论文的关键在于找到 nonlinear transformation from LR and HR to common space。 Two deep CNN。
由于包含一个 super-resolution CNN,同时还可以生成 LR 对应的 HR 图像。
Object Function 是 Distance of transformed low and high resolution images in the common space。
Dataset 是 FERET。
占用内存小。
Method
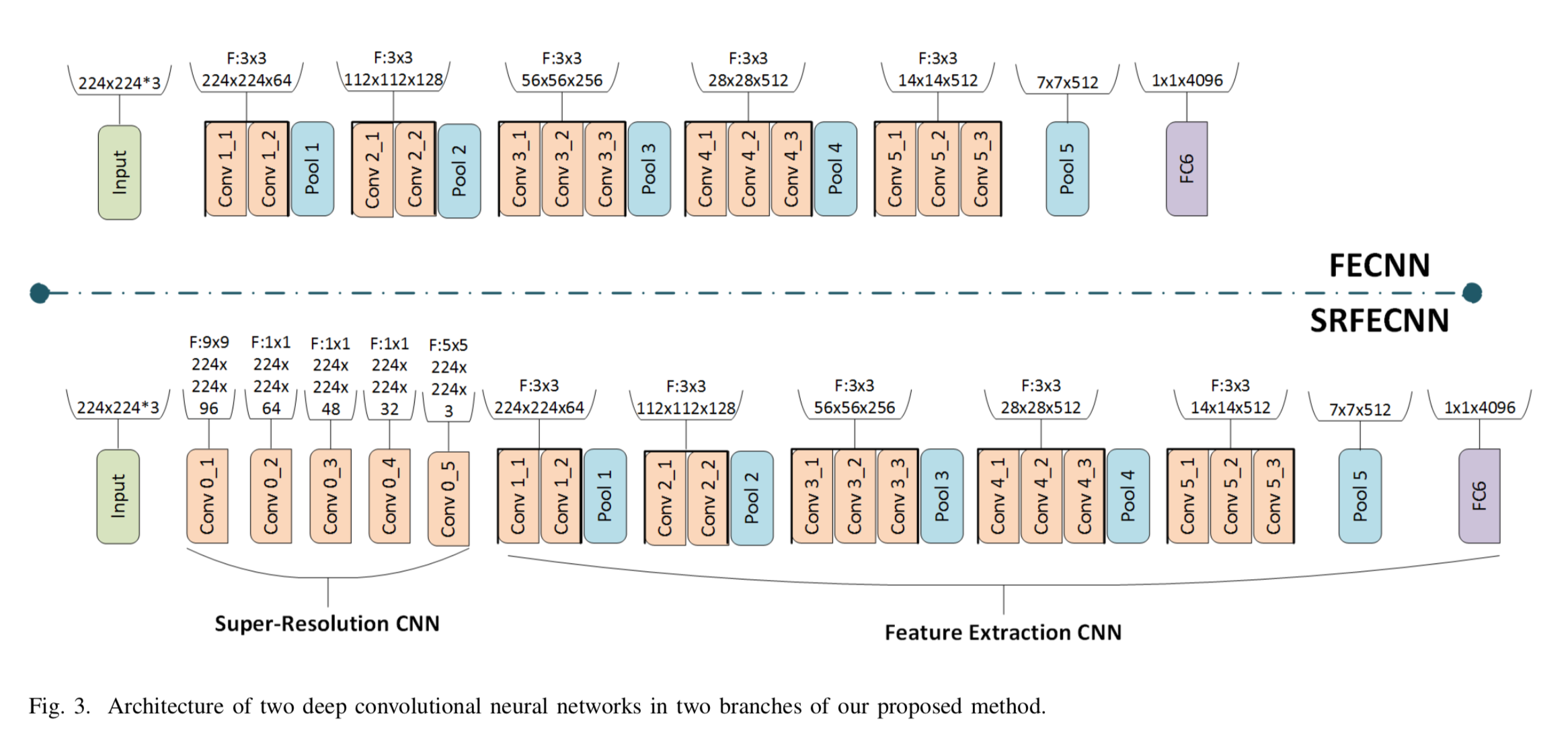
Training set: pairs of LR and HR of same person on different conditions.
Networks Architecture
VGGnet: 13 CONV + 3 FC
- HR images -> common space: FECNN(feature extraction onvolutional neural network). 224x224 image -> 4096 feature vector. VGGnet - 2 FC
- LR images -> common space: SRFECNN = SRnet(super-resolution net) + FECNN. 224x224 -> 4096 feature vector
由于去掉两层 FC,比 VGGnet parameter 少,可以放进内存。

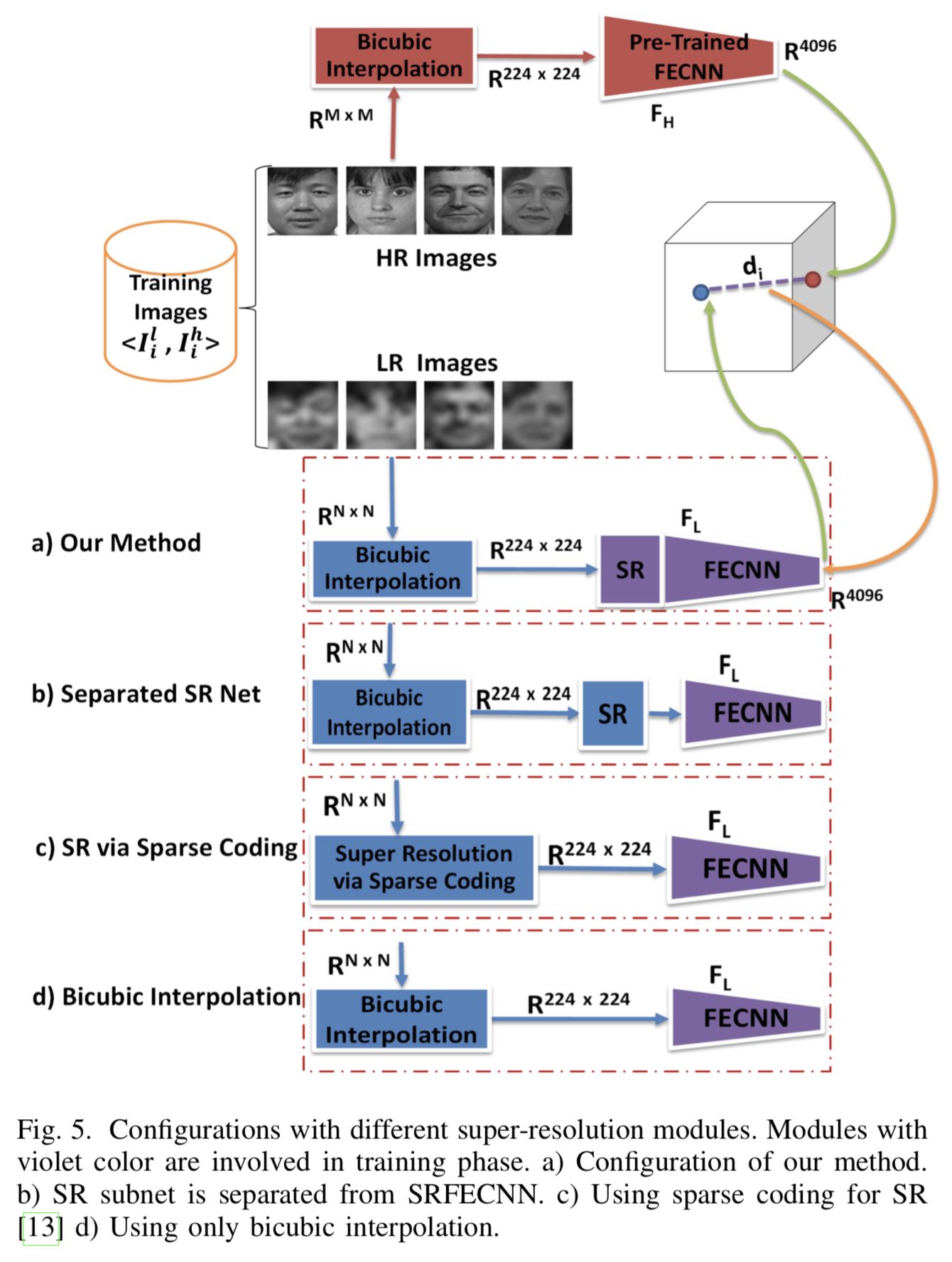
Common Subspace Learning
3 steps:
- Use trained VGGnet on face dataset and then dropped the last two FC. 因为这两层是为 classification task 特别起作用的。称为 pre-trained FECNN。
- Train the SRnet of the bottom branch with a dataset of high and low resolution face image pairs.
- Merge SRnet and FECNN and a training dataset that contains pairs of LR and HR of same persons was fed into the brached.
HR 所在上层固定,只训练 LR 所在下层的 FECNN 和 SRnet。
Distance between LR and HR images of the same subjects is the error, backpropagated into the bottom branch net (both FECNN and SRnet).
Reconstruct Input Image
SRnet 输出。SRnet 的主要作用看上去是让极低分辨率的图片不至于表现太坏。
生成图片的效果并不是很好,为 better recognition performance 做出了牺牲。

Datasets
