Feature Extraction 特征值生成

Numeric Feature
- Numeric feature preprocessing is different for tree and non-tree models:
a. Tree-based models doesn’t depend on scaling
b. Non-tree-based models hugely depend on scaling - Most often used preprocessings are:
a. MinMaxScaler - to [0,1]
b. StandardScaler - to mean==0, std==1
c. Rank - sets spaces between sorted values to be equal
d. np.log(1+x) and np.sqrt(1+x) - Feature generation is powered by:
a. Prior knowledge
b. Exploratory data analysis
1 | # scaling To [0, 1] |
Categorical and ordinal features
- Values in ordinal features are sorted in some meaningful order.
- Label encoding maps categories to numbers.
- Frequency encoding maps categories to their frequencies.
- Label and Frequency encodings are often used for treebased models.
- One-hot encoding is often used for non-tree-based models.
- Interactions of categorical features can help linear models and KNN.
Ordinal features
1 | # Label encoding - Alphabeical (sorted) [S,C,Q] -> [2,1,3] |
Categorical features
1 | # One-hot encoding |
Datetime
- Periodicity
Day number in week, month, season, year, second, minute, hour. - Time since
a. Row-independent moment
For example: since 00:00:00 UTC, 1 January 1970;
b. Row-dependent important moment
Number of days left until next holidays/ time passed after last holiday. - Difference between dates
datetime_feature_1 - datetime_feature_2
Coordinates
a. Interesting places from train/test data or additional data
b. Centers of clusters
c. Aggregated statistics
Feature Extraction from Texts
Text -> vector
- Bag of words

a. Very large vectors.
b. Meaning of each value in vector is known.
c. Ngrams can help to use local context
d. TFiDF can be of use as postprocessing - Embeddings (~word2vec)
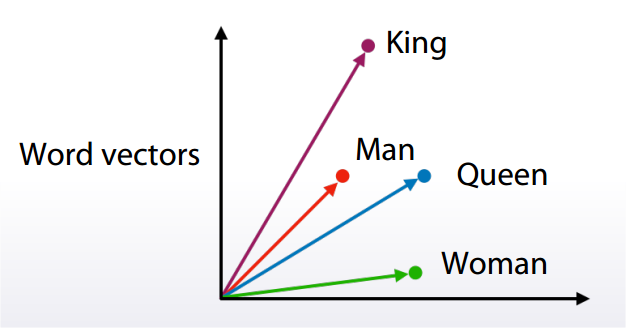
a. Relatively small vectors.
b. Values in vector can be interpreted only in some cases.
c. The words with similar meaning often have similar embeddings.
d. Pretrained models
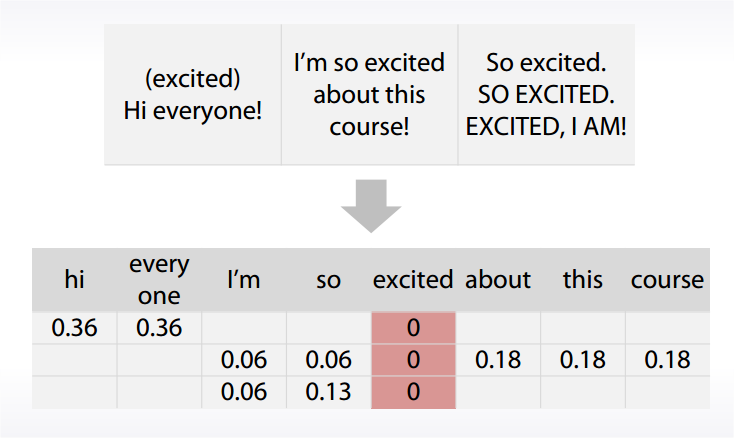
Bag of Words
Pipeline of applying BOW
- Preprocessing:
Lowercase, stemming, lemmatization, stopwords
stopwords:sklearn.feature_extraction.text.CountVectorizer: max_df

- Bag of words:
Ngrams can help to use local context:sklearn.feature_extraction.text.CountVectorizer: Ngram_range, analyzer

- Postprocessing: TFiDF
count words:sklearn.feature_extraction.text.CountVectorizer
TFiDF:sklearn.feature_extraction.text.TfidfVectorizer

tf-idf模型的主要思想是:如果词w在一篇文档d中出现的频率高,并且在其他文档中很少出现,则认为词w具有很好的区分能力,适合用来把文章d和其他文章区分开来。该模型主要包含了两个因素:
- 词w在文档d中的词频tf (Term Frequency),即词w在文档d中出现次数count(w, d)和文档d中总词数size(d)的比值:
tf(w,d) = count(w, d) / size(d) - 词w在整个文档集合中的逆向文档频率idf (Inverse Document Frequency),即文档总数n与词w所出现文件数docs(w, D)比值的对数:
idf = log(n / docs(w, D))
tf-idf模型根据tf和idf为每一个文档d和由关键词w[1]…w[k]组成的查询串q计算一个权值,用于表示查询串q与文档d的匹配度:
1 | tf-idf(q, d) |
Word2Vec
- Words: Word2vec, Glove, FastText, etc.
- Sentences: Doc2vec, etc.
There are pretrained models.
Feature Extraction from Images
Image -> Vector
- Descriptors
- Train network from scratch
- Finetuning
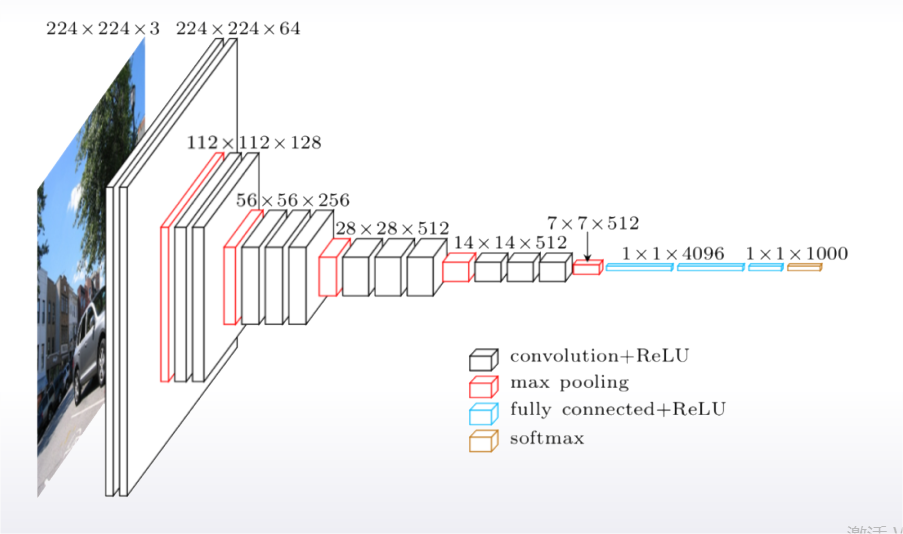
a. Features can be extracted from different layers.
b. Careful choosing of pretrained network can help.
c. Finetuning allows to refine pretrained models.
d. Data augmentation can improve the model.
Ref
[1] Coursera - How to Win a Data Competition
[2] https://coolshell.cn/articles/8422.html
[3] http://datascience.la/meetup-summary-winning-data-science-competitions/