线代直觉
将 Linear algebra explained in four pages,cs229 的笔记,深度学习花书第2章,程序员的数学3 - 线性代数 的笔记汇总在这里。糅合起来有点花时间,先分开记录。
Linear algebra explained in four pages
基础速读。
目录
- Introduction
- Definitions
a. Vector operations
b. Matrix operations
c. Matrix-vector product
d. Linear transformations
e. Fundamental vector spaces
f. Matrix inverse - Computational linear algebra
a. Solving systems of equations
b. Systems of equations as matrix equations - Computing the inverse of a matrix
a. Using row operations
b. Using elementary matrices
c. Using a computer - Other topics
a. Basis
b. Matrix representations of linear transformations
c. Dimension and bases for vector spaces
d. Row space, columns space, and rank of a matrix
e. Invertible matrix theorem
f. Determinants
g. Eigenvalues and eigenvectors
文件
Linear algebra explained in four pages
cs229 - Linear Algebra Review and Reference
主要看看 4. Matrix Calculus。
目录
- Basic Concepts and Notation
1.1 Basic Notation - Matrix Multiplication
2.1 Vector-Vector Products
2.2 Matrix-Vector Products
2.3 Matrix-Matrix Products - Operations and Properties
3.1 The Identity Matrix and Diagonal Matrices
3.2 The Transpose
3.3 Symmetric Matrices
3.4 The Trace
3.5 Norms
3.6 Linear Independence and Rank
3.7 The Inverse
3.8 Orthogonal Matrices
3.9 Range and Nullspace of a Matrix
3.10 The Determinant
3.11 Quadratic Forms and Positive Semidefinite Matrices
3.12 Eigenvalues and Eigenvectors
3.13 Eigenvalues and Eigenvectors of Symmetric Matrices - Matrix Calculus
4.1 The Gradient
4.2 The Hessian
4.3 Gradients and Hessians of Quadratic and Linear Functions
4.4 Least Squares
4.5 Gradients of the Determinant
4.6 Eigenvalues as Optimization
文件
Linear Algebra Review and Reference
深度学习 - 第2章 线性代数
记了一些零零碎碎的点。
标量、向量、矩阵和张量,矩阵和向量相乘,单位矩阵和逆矩阵,线性先关和生成子空间
tensor 张量
广播,broadcasting,C = A + b,向量 b 和矩阵 A 的每一行相加。
矩阵元素对应乘积的符号是 。
两个相同维数的向量 x 和 y 的点积 dot product 可看作矩阵乘积。两个向量的点积满足交换律:。因为两个向量点积的结果是标量、标量转置是自身。
逆矩阵主要是作为理论工具使用的,并不会在大多数软件应用程序中实际使用。这是因为逆矩阵在数字计算机上只能表现出有限的精度,有效使用向量的算法通常可以得到更精确的。
一组向量的生成子空间 span 是原始向量线性组合后所能抵达的点的集合。确定是否有解,相当于确定向量是否在列向量的生成子空间中。
范数
机器学习中经常使用范数 norm 的函数来衡量向量大小。形式上,范数定义如下:
其中 , 。
范数是将向量映射到非负值的函数。直观上来说,向量 x 的范数衡量从原点到点 x 的距离。
当 p=2 时,范数称为欧几里得范数 Euclidean norm。它表示从原点出发到向量 x 确定的点的欧几里得距离。范数在机器学习中出现的十分频繁,经常简化表示为,略去了下标2.
平方范数也经常用来衡量向量的大小,可以简单地通过点积计算。
平方范数在数学和计算上都比范数本身更方便。例如,平方范数对 x 中每个元素的导数只取决于对应的元素,而范数对每个元素的导数和整个向量相关。
但是在很多情况下,平方范数也可能不受欢迎,因为它在原点附近增长得十分缓慢。在某些机器学习应用中,区分恰好是零的元素和非零但值很小的元素是很重要的。在这些情况下,我们转而使用在各个位置斜率相同,同时保持简单的数学形式的函数:范数。范数可以简化如下:
当机器学习问题中零和非零元素之间的差异非常重要时,通常会使用范数。每当 x 中某个元素从0增加,对应的范数也会增加。
有时候我们会统计向量中非零元素的个数来衡量向量的大小。有些作者将这种函数称为"范数",但是这个术语在数学意义是不对的。向量的非零元素的数目不是范数,因为对向量缩放倍不会改变该向量非零元素的数目。因此范数经常作为表示非零元素数目的替代函数。
另外一个经常在机器学习中出现的范数是,也成为最大范数 max norm。这个范数表示向量中具有最大幅值的元素的绝对值:
有时候我们可能也希望衡量矩阵的大小。在深度学习中,最常见的做法是使用 Frobenius 范数,即:
其类似于向量的范数。
两个向量的点积可以用范数表示,具体如下:
其中表示 x 和 y 之间的夹角。
特殊类型的矩阵和向量
对角矩阵 diagonal matrix 受到关注的原因是对角矩阵的乘法计算很高效。注意并非所有的对角矩阵都是方阵,长方形的矩阵也有可能是对角矩阵。
对称矩阵 symmetric matrix 矩阵是转置和自己相等的矩阵,。
正交矩阵 orthogonal matrix 指行向量和列向量是分别标准正交的方阵,即,这意味着。正交矩阵受到关注是因为求逆计算代价小。
特征分解
特征分解 eigendecomposition 是使用最广的矩阵分解之一,即我们将矩阵分解成一组特征向量和特征值。
方阵 A 的特征向量 eigenvector 是指与 A 相乘后相当于对该向量进行缩放的非零向量 v:
其中标量 称为这个特征向量对应的特征值 eigenvalue。
假设矩阵 A 有 n 个线性无关的特征向量对应着 n 个特征值。我们将特征向量连接成一个矩阵,使得每一列是一个特征向量 。将特征值连接成一个向量 。因此 A 的特征分解 eigendecomposition 可以记作:
不是每一个矩阵都可以分解为特征值和特征向量。但DL中通常只需要分解一类有简单分解的矩阵。具体来讲,每个实对称矩阵都可以分解成实特征向量和实特征值:
形状是 口 x [\] x 口。
其中是的特征向量组成的正交矩阵,是对角矩阵。特征值对应的特征向量是矩阵的第列,记做。
因为是正交矩阵,,我们可以将看作沿方向延展倍的空间。
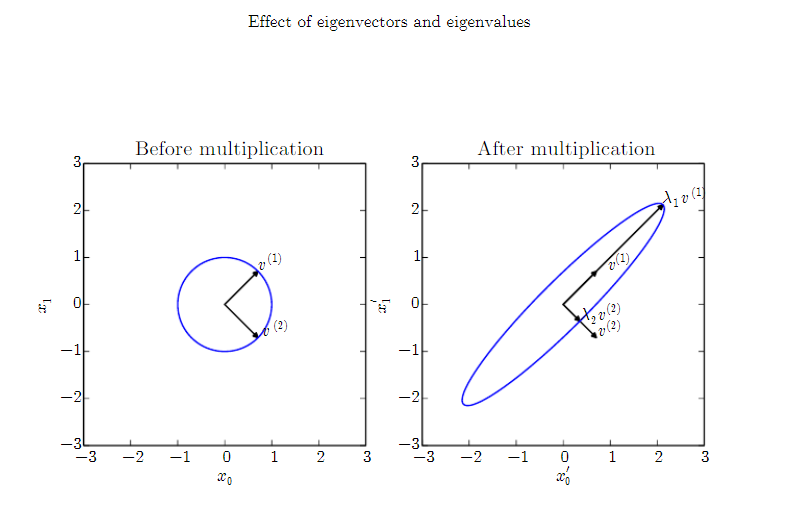
左:单位向量 u 的集合。右:Au 点的集合,A 有两个特征向量,有对应的特征值。
所有特征值都是正数的矩阵称为正定 positive definite;所有特征值都是非负数的矩阵称为半正定 positive semidefinite;所有特征值都是负数的矩阵称为负定 negative definite;所有特征值都是非正数的矩阵称为半负定 negative semidefinite。
半正定矩阵受到关注是因为它们保证 。
此外,正定矩阵还保证 。
奇异值分解
另一种分解矩阵的方法,奇异值分解 singular value decomposition, SVD ,是将矩阵分解为奇异向量 singular vector 和奇异值 singular value。
奇异值分解比特征分解应用更广。每个实数矩阵都有一个奇异值分解,但不一定都有特征分解。例如,非方阵的矩阵没有特征分解,此时只能使用奇异值分解。
矩阵被分解为三个矩阵的乘积:
假设是一个 mxn 的矩阵,那么是一个 mxm 的矩阵,是一个 mxn 的矩阵,是一个 nxn 矩阵。
这些矩阵都有特殊结构。矩阵和都定义为正交矩阵,而矩阵定义为对角矩阵。注意不一定是方阵。
D 对角线上的元素称为奇异值 singular value,U 和 V 的列分别称为左奇异向量和右奇异向量 left/right singular vector。
SVD 最有用的一个性质是拓展矩阵求逆到非方矩阵上。
Moore-Penrose 伪逆
矩阵 A 伪逆定义为:
计算伪逆的式计算法没有基于这个定义,而是使用下面的公式:
其中,矩阵 U、D 和 V 是矩阵 A 奇异值分解后得到的矩阵。对角矩阵 D 的伪逆是其非零元素取倒数之后再转置得到的。
当矩阵 A 的列数多于行数时,使用伪逆求解线性方程是众多可能被揭发中的一种。特别地,是方程所有可行解中欧几里得范数最小的一个。
当矩阵 A 的行数多于列数时,可能没有解。此时通过伪逆得到的 x 使得 Ax 和 y 的欧几里得距离 最小。
迹运算
迹运算返回的是矩阵对角元素的和:
作用是方便描述问题。
迹运算有一些特点:
行列式
行列式,记作 det(A),是一个将方阵 A 映射到实数的函数。
行列式等于矩阵特征值的乘积。
行列式的绝对值可以用来衡量矩阵参与矩阵乘法后空间扩大或者缩小了多少。如果行列式为0,那么空间至少沿着某一维完全收缩了,使其失去了所有的体积;如果行列式是1,那么这个转换保持空间体积不变。
程序员的数学3 - 线性代数
比喻用的比较好,直观。
用空间的语言表达向量、矩阵和行列式
向量:有向线段(带有方向的线段)、空间内的点。
矩阵:空间到空间的映射。
行列式:上面的映射对应的"体积扩大率"。
向量与空间
默认用列向量是因为常用 Ax 的形式。
线性空间,加法 + 数量乘法。
基底
维数 = 基向量的个数 = 坐标的分量数
矩阵和映射
矩阵就是映射!
矩阵的每一列就是原基底要达到的终点(新基底)

矩阵的乘积 = 映射的合成
矩阵的乘方 = 映射的迭代
零矩阵 = 所有的点都映射到原点的映射
单位矩阵 = 什么都不做的映射
对角矩阵 = 沿着坐标轴伸缩的映射,其中对角元素就是各轴伸缩的倍率
逆矩阵 = 逆映射 (显然对角矩阵的逆矩阵对角线上为1/a)
矩阵可以表示各种关系,例如:
高阶差分与高阶微分:

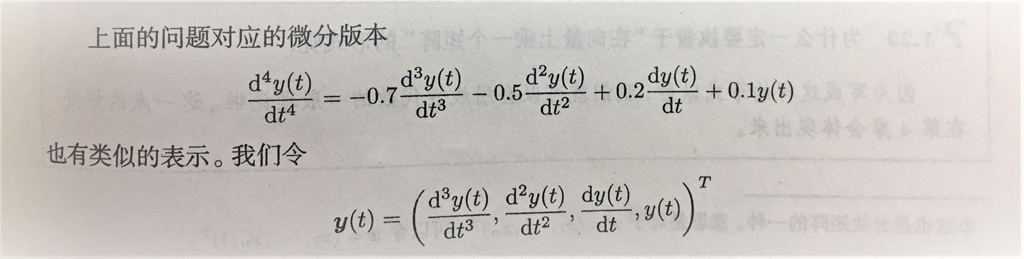

消除常数项:

坐标变换可以用乘以方阵 A 的形式来表示,这里的 A 存在逆矩阵。
基底变换公式和坐标变换公式:

时刻注意矩阵规模形状:
1 | # ### # # # ### ### |
行列式与扩大率
行列式 = 体积扩大率
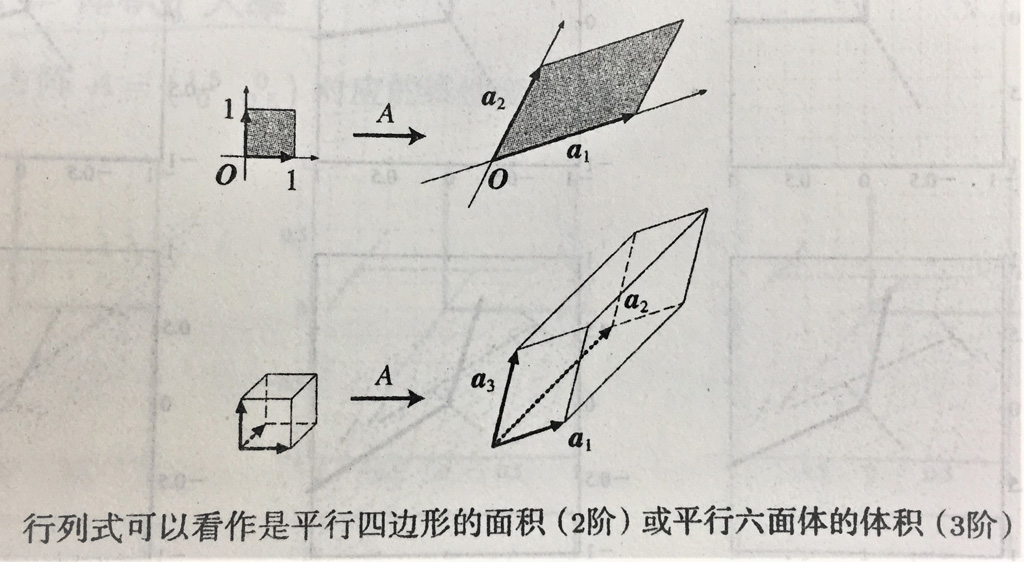
体积扩大率说法的作用:
- 微积分中,积分可以解释为由函数图像围成的面积。多重积分的换元法中,行列式起到了关键的作用。雅克比矩阵。
- 概率论中,研究概率密度函数根据随机变量的变化而产生的变化时,用行列式,因为空间的延伸会带来密度的下降。
- 行列式可以用来检测是否产生了退化,压缩扁平化对应的行列式是0。
行列式的关键,多重线性特质、交替性。
一些性质:
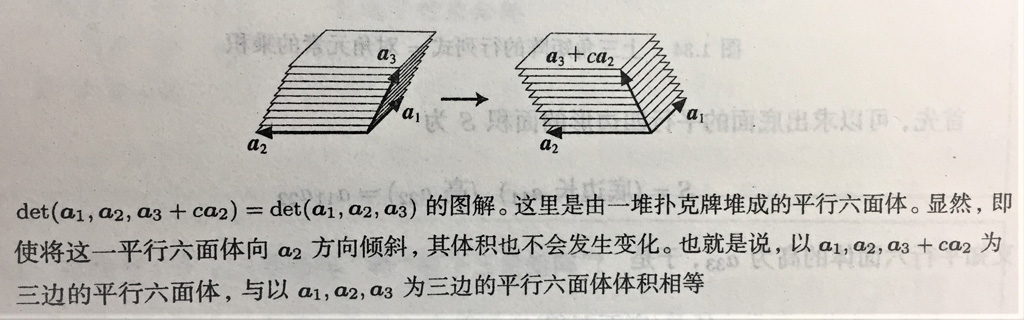
- 行列式中,把某一列乘以常数,加到另一列上,行列式值不变。
- 上三角矩阵(对角线下方都是0)可变化为对角矩阵,因此 上三角矩阵的行列式 = 对角元素的乘积
- 转置矩阵的行列式与原矩阵的行列式相等。
- 关键性质
多重线性
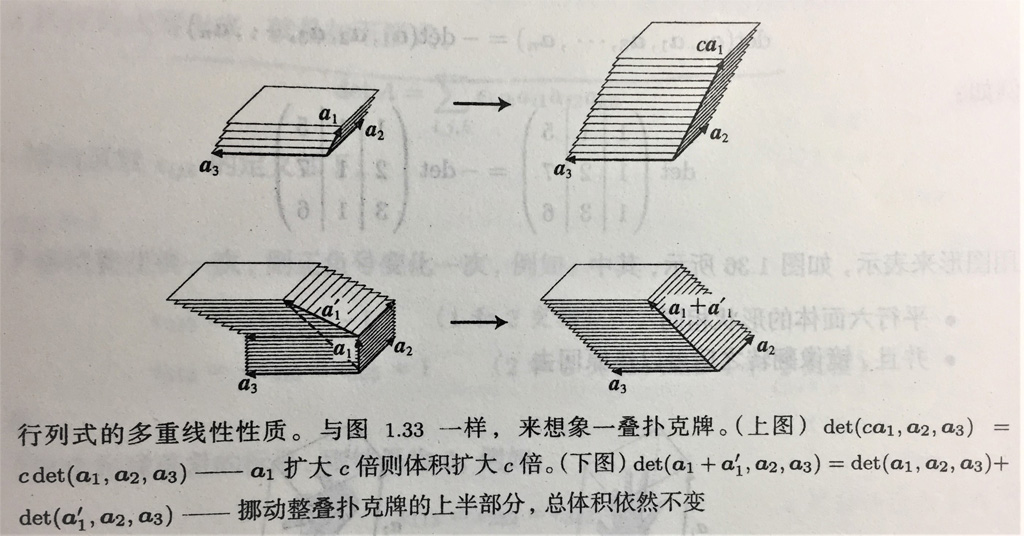
交替性。交换两行会改变行列式的正负。(有点类似左右手坐标系的变化)
秩、逆矩阵、线性方程组 —— 溯因推理
问题设定:逆问题
已知结果 y 去推测原因 x 的问题,成为逆命题。现实世界中的问题,一般还要考虑噪声。
良性问题(可逆矩阵)
GaUSS-Jordan 法解线性方程组

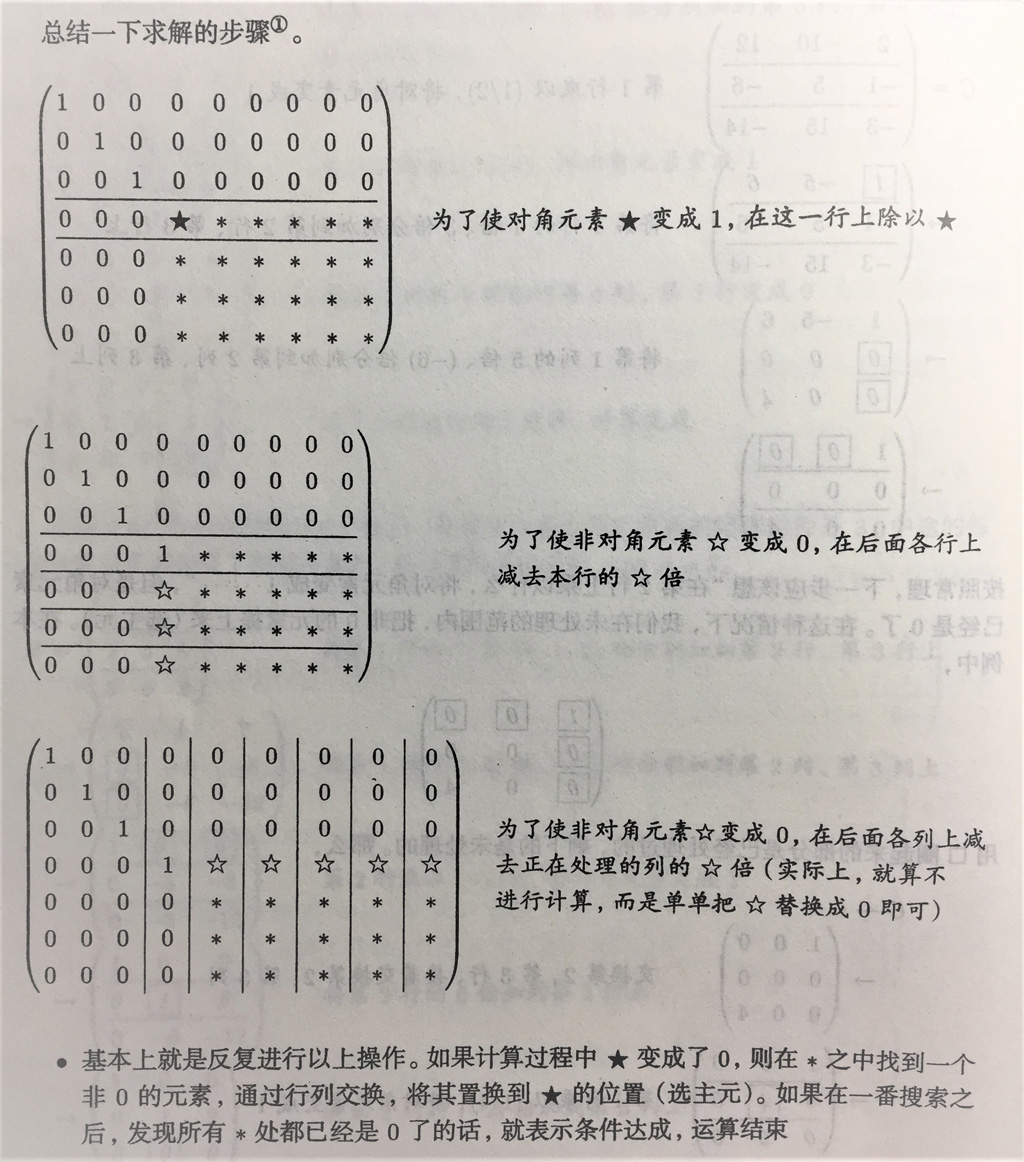
如果对角元素有0,就选主元。
恶性问题
恶性问题的示例:
- 线索不足的情况 (矮矩阵、核)
y 的维数 < x 的维数。
满足 Ax = 0 的 x 的集合称为 A 的核 kernel,记为 Ker A。 - 线索过剩的情况 (长矩阵、像)
y 的维数 > x 的维数。线索之间可能冲突。
在 A 的作用下,y = Ax 构成的集合,称为 A 的像 image,记为 Im A。
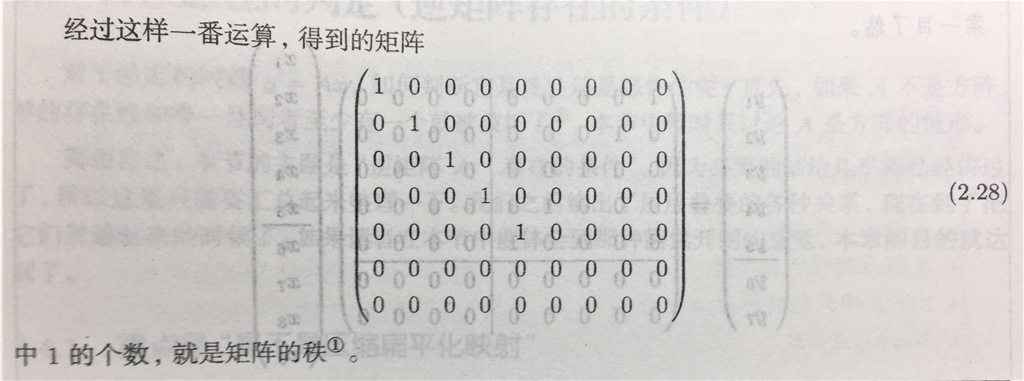
Im A 的维数 dim Im A 称为矩阵 A 的秩 rank,记为 rank A。 - 即使线索的个数正好 (奇异矩阵)
与线索不足情况类似,映射时有信息丢失。
线性方程组的解的存在性和唯一性:
- Ker A 仅包含原点o = 映射为单射
- Im A 与目标空间全体(值域)一致 = 映射为满射
A 为 mxn 矩阵,dim Ker A + dim Im A = n。
- rank A = n (秩与原空间(定义域)的维数相等) = A 是单射
- rank A = m (秩与目标空间(值域)的维数相等) = A 是满射
求秩的笔算法:
良性恶性的判定(逆矩阵存在的条件)
重点是"是不是压缩扁平化映射"。非压缩扁平化可以改写成 Ker A 中只包含原点 o,或者也可以说 Ker A 是0维的,与 rank A = n 等价。
可逆的条件:

针对恶性问题的对策
- 对于没有解的情况,给出无解的回答。
根据定义 y 不属于 Im A 时。 - 对于有多个解的情况,给出所有的解。


如果只需要一个解,可以用最小二乘法,Ax 尽量接近 y。
关于前文出现的各种笔算,使用初等变换,初等行变换 + 列交换。
现实中的恶性问题(接近奇异的矩阵)
问题来自噪声被矩阵映射夸张放大了。
可以使用 提克洛夫规范化 Tikhonov regularization。
计算机上的计算 —— LU 分解
千万不要小看数值计算。计算机上,数值的精度只有有限位,还要尽量减少运算量和内存消耗。
LU 分解
给定矩阵 A,将 A 表示成下三角矩阵 L 和上三角矩阵 U 的乘积,称为 LU 分解。
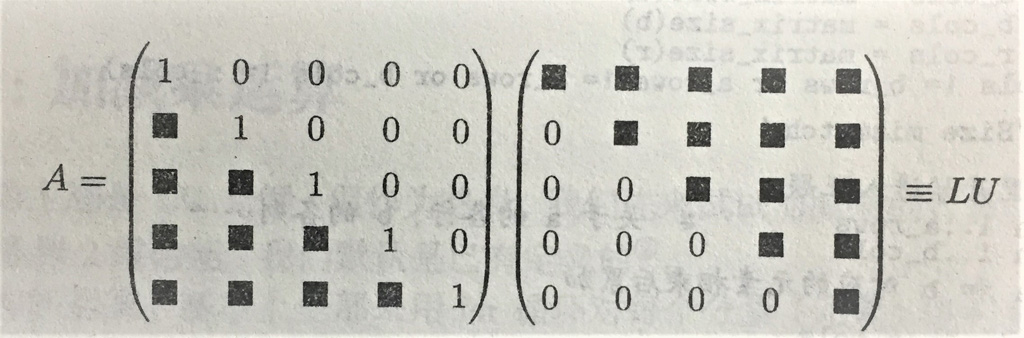
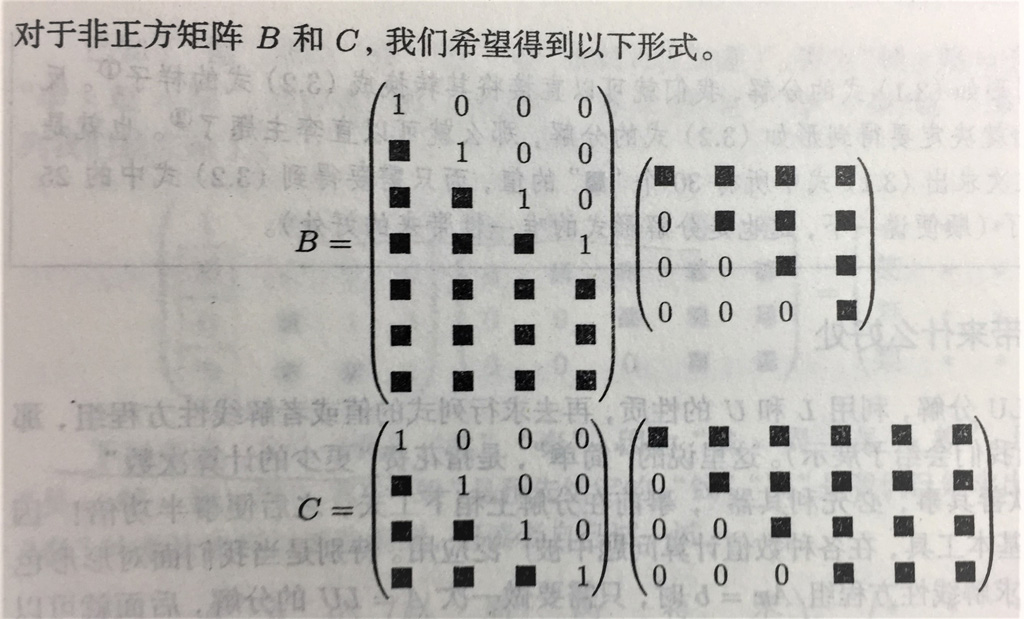
好处是:完成 LU 分解后,利用 L 和 U 的性质,再去求行列式或者解线性方程组,可以用更少的计算次数。
按照第1行、第1列、第2行、第2列的顺序,根据前面求出来的值,就可以顺藤摸瓜得到后面的。
利用 LU 分解求行列式的值
det A = det(LU) = (det L)(det U)
而下三角矩阵和上三角矩阵的行列式就是对角元素的乘积,det L = 1,所以
det A = (U 的对角元素的乘积)
利用 LU 分解求解线性方程组
运算量比较小,尤其是当需要解很多 A 相同而 y 不同的方程组 Ax = y 时,优势很大。
完成 LU 分解后,解方程组变成了两个步骤,这两个步骤都很好解:
- 求出满足 Lz = y 的 z。
- 求出满足 Ux = z 的 x。
利用 LU 分解求逆矩阵
没必要求 了,因为很多时候需要的只是对于给定的向量 y,求 的值。在这种情况下可以直接去解方程 Ax = y。从运算量和精度控制(避免累计误差)的角度来讲,后者都是更好的。
特征值、对角化、Jordan 标准型 —— 判断是否有失控的危险
问题的提出:稳定性
某个算法的结果会不会趋向正负无穷。

核心思想是:把前一次的状态 x(t-1) 移动到现在的状态 x(t) 的映射 f,(在某个基底之下)可以用矩阵 A 来表示,此时我们可以寻找其他更好的基底,对 x 进行坐标变换。然后,为了选出好的基底,就要用到特征向量。
离散时间系统
对角矩阵的情况
例子:


可以看出,只要系数矩阵是对角矩阵,就可以比较轻松地看出是否会失控了。


可对角化的情况
三种理解的角度:
变量替换
一般流程:
- 选定某矩阵 P,用其的逆将 x(t) 变成另一组变量 。
- 把关于 x(t) 的差分方程 x(t) = Ax(t-1) 改写成关于 y(t) 的方程。
- 新的方程的系数矩阵如果是对角矩阵,那么就容易求解了。
- 把新解出的 y(t) 还原成 x(t)。大功告成。
即:
令为对角矩阵,则可求出
然后再根据和可以求得 x:
关键就是选择合适的 P。
把 P 分解成列向量考虑:
两边同时左乘 P:
即 的形式。
数和向量分别称为 特征值 和 特征向量。后文讲如何求。
坐标变换
p 是理想基底,单纯沿坐标轴方向伸缩 λ。

将结果在原来的默认基底还原。
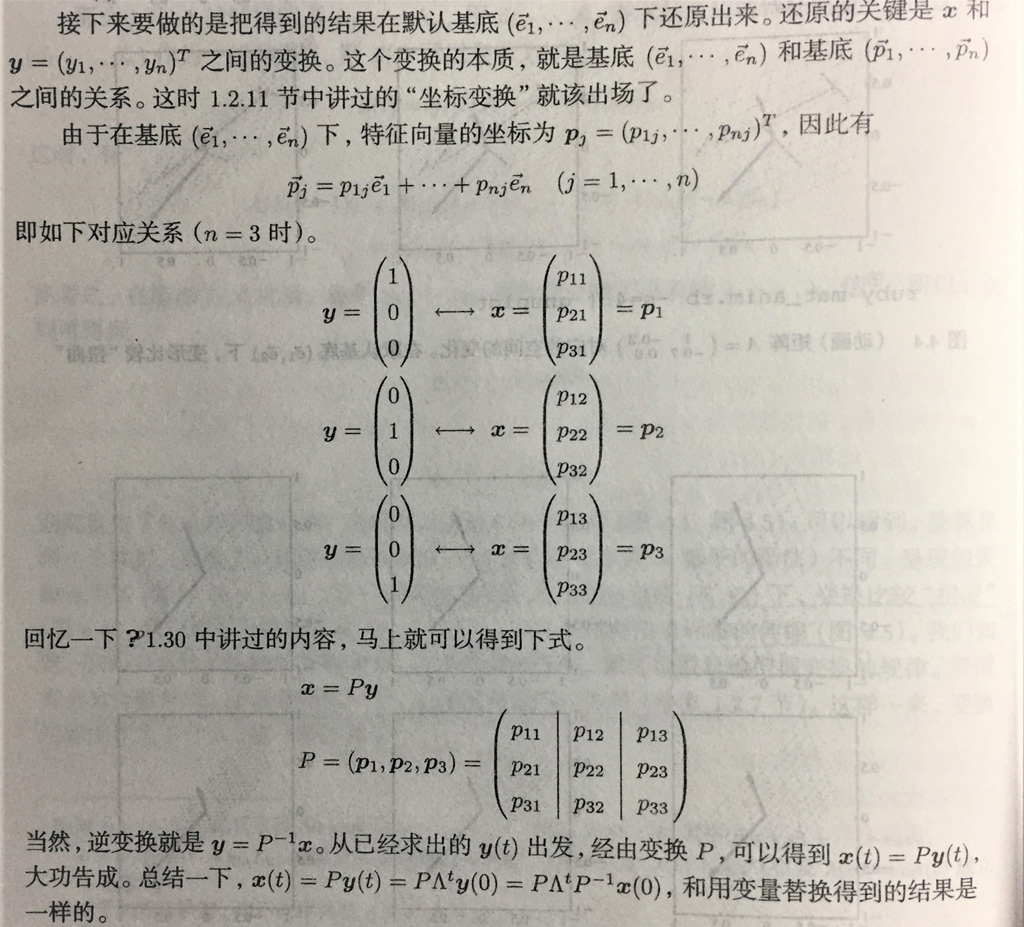
乘方计算
由于 ,求即可。找出合适的可逆矩阵 P,使为对角矩阵,而,则可求。于是。
结论:关键取决于特征值的绝对值
原 x(t) 是否会越跑越远和变换后的 是否会越跑越远是一码事。
在可对角化的前提下,可以得出结论:
- 之中只要有一个大于1,那么就有失控的危险。
- 若,则没有失控的危险。
特征值、特征向量
一般而言,对于方阵 A,满足 ,的数 和向量 分别称为特征值和特征向量。
几何学意义:特征向量乘 A 之后,除了长度会有伸缩变化,方向不发生改变。这里的长度变化倍率,就是特征值。
特征值、特征向量的性质:

行列式 = 特征值的乘积,detA = λ1 … λn
不相等的特征值对应的特征向量线性无关。
用特征方程解特征值:
,所以括号里的内容有退化,则,是为特征方程。
根据定义求特征向量:
求出特征值后,代入Ap = λp,求解。
连续时间系统
讨论形如的微分方程,目标是判断其对应的系统是否有失控的危险。
一般而言,对于常数 a,方程的解为形如的指数函数。所以是否失控取决于 a。
对角矩阵的情况:

可对角化的情况:转换为对角矩阵。

结论:特征值(的实部)的符号是关键

离散时间系统和连续时间系统判定条件不一样的原因是,两种系统中 A 的意义不同。
不可对角化的情况 - Jordan 标准型
只是在边界条件和可以对角化的不一样。

与对角矩阵接近。于是可以把方阵 A 化为 Jordan 标准型。
Jordan 标准型由 Jordan 块组成,Jordan 块满足以下条件。
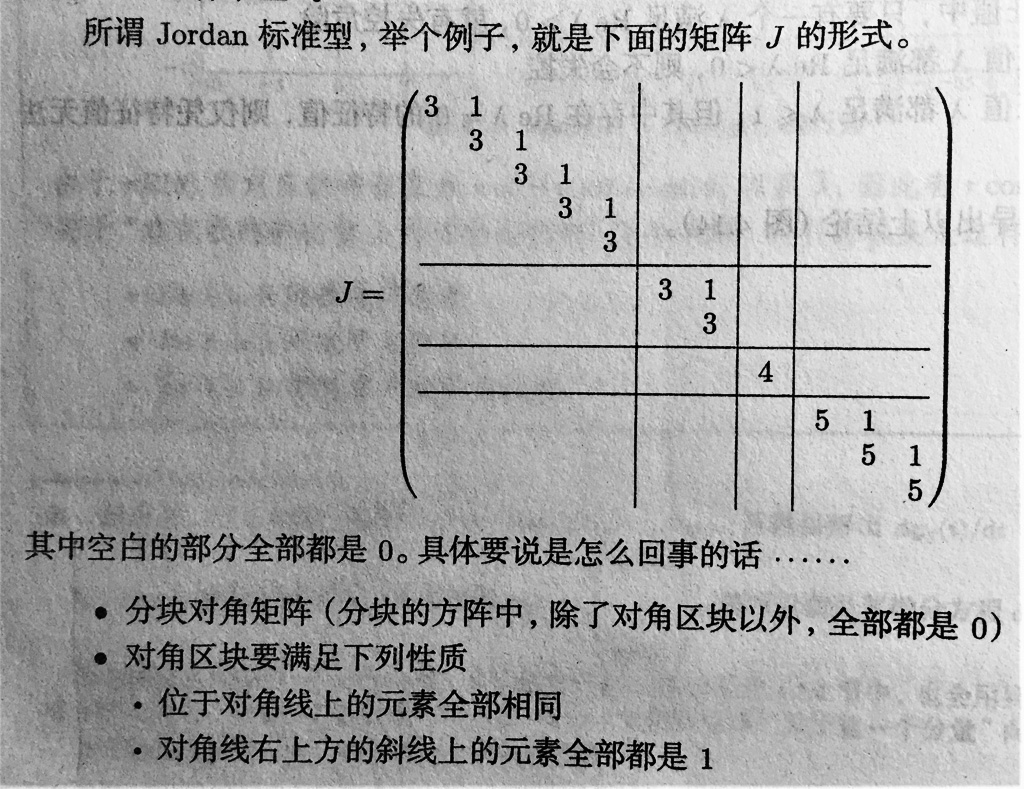
Jordan 标准型的好处是:(分块对角矩阵,只需考虑每个区块即可)
- 可以看出特征值、特征向量的样子。
对角元素就是特征值 λ。
对角线上有几个相同的 λ,对应的特征值 λ就是几重根。
对角元素是 λ 的 Jordan 块有几个,对应的线性无关的特征向量就有几个。 - 可以进行乘方的具体计算。
Z为分块内去掉对角线的部分,其乘方有上移作用。
例如 B = 7I + Z,。
离散时间系统失控判定



其实,对于一般的方阵 A,离散时间判断失控与否,通常只需要考察特征值 λ 即可。

连续时间系统失控判定
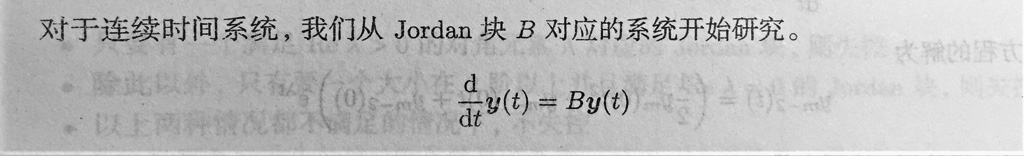

逐步带回后得到式子:

对于一般方阵 A,连续时间判断失控与否,一般也是主要考察特征值 λ。


化 Jordan 标准型的方法(略)
计算机上的计算 —— 特征值算法
概要
根据$P^{-1}AP = $(对角矩阵或上三角矩阵),右侧的对角元素就是要求的特征值。
5 x 5 以上的矩阵的特征值不存在通用的求解步骤,只能通过反复进行相似变换,逐渐将矩阵向着对角矩阵或上三角矩阵的方向靠近。
Jacobi 方法
速度劣势,精度较佳。适合 10 x 10 以内的矩阵。实现容易一些。、
对于给定的矩阵 A,选择不同的 p,q,θ,通过平面旋转反复进行如下相似变换,直到矩阵变成接近对角化的形式为止。。(旋转矩阵是正交矩阵,转置矩阵等于逆矩阵)
QR 方法
幂法:对某初始向量v,反复左乘 A,其会渐渐靠近 A 的绝对值最大的特征值对应的特征向量 x1 的方向。
QR分解:A = QR,Q 是 A 的列向量的 Gram-Schmidt 标准正交化,R 是在 A 的列向量的标准正交基下的坐标表示。
用幂法求所有特征值:选择 n 个适当的线性无关的初始向量 v1, v2, …, vn,对其反复左乘 A,然后把所有结果进行 Gram-Schmidt 标准正交化,那么最终结果就会接近 A 的特征向量所张成的标准正交基。
用 QR 方法求解矩阵特征值的基本流程如下:
- 对需要求解特征值的矩阵进行 QR 分解。A0 = Q0R0
- 对分解出来的结果进行逆向相乘。A1 = R0Q0
- 对相乘得到的矩阵进行 QR 分解。A1 = Q1R1
- 对分解出来的结果进行逆向相乘。A2 = R1Q1
- … 重复
反复进行后,A 会接近一个上三角矩阵,其对角元素正是 A0 的特征值。
原因:注意到
后略
Ref:
[1] Linear algebra explained in four pages
[2] cs229
[3] 深度学习
[4] 程序员的数学3 - 线性代数