特征选择与稀疏学习
子集搜索与评价
feature 有相关的也有不相关的,挑挑。feature selection 是重要的 data preprocessing 过程。既可以避免维度灾难,也可以降低学习任务的难度。
特征选择算法 = 子集搜索机制 + 子集评价机制
两个问题:
- 如何根据评价结果获取下一个候选特征子集?子集搜索问题 subset search
贪心。前向一点点加,或后向一个个去。 - 如何评价候选特征子集的好坏?子集评价 subset evaluation
可计算信息增益,按此属性分类后信息增益了多少。
前向搜索+信息熵,很像决策树,事实上决策树也可以用于特征选择,树节点的划分属性所组成的集合就是选择出的特征子集。
三种类型
- filter 过滤式
- wrapper 包裹式
- embedding 嵌入式
filter 过滤式选择
过滤式方法先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关。这相当于先用特征选择过程对初始特征进行过滤,再用过滤后的特征来训练模型。
Relief (Relevant Features)
用”相关统计量”来度量特征的重要性。对于一个属性,对每个示例,距离上 猜中近邻 < 猜错近邻,这就说明这个属性此时有用,增加它的统计量分量。


定义猜中近邻和猜错近邻,如果到猜中近邻的在属性 j 上的距离比到猜错近邻在属性 j 上的距离小,就说明此属性 j 对区分同类与一类样本是有益的,就增加属性 j 所对应的统计量分量。
Relief 的时间开销随着采样次数以及原始特征数线性增长。
适用于二分类问题,扩展变体 Relief-F 可处理多分类问题。
wrapper 包裹式选择
包裹式特征选择直接把最终将要使用的学习器的性能作为特征子集的评价准则。换言之,包裹式特征选择的目的就是为给定学习器选择最有利于其性能、量身定做的特征子集。
好处,从最终学习器性能来看,包裹式比过滤式好,毕竟就是直接目标。
缺点,因为特征选择过程中需要多次训练学习器,所以计算开销大得多。
Las Vegas Wrapper
在拉斯维加斯方法 Las Vegas method 框架下使用随机策略来进行子集搜索,并以最终分类器的误差为特征子集评价准则。就是随机选了多个开始训练了,然后选择结果最好的。

embedding 嵌入式选择与 L1 正则化
特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了特征选择。
使用正则项,可以降低过拟合风险。
线性回归模型 + L2范数就是 ridge regression 岭回归,线性回归模型+ L1范数就是 LASSO (Least Absolute Shrinkage and Selection Operator)。


L1范数比 L2范数更易于获得 sparse 稀疏的解,即它求得的 w 会有更少的非零分量。


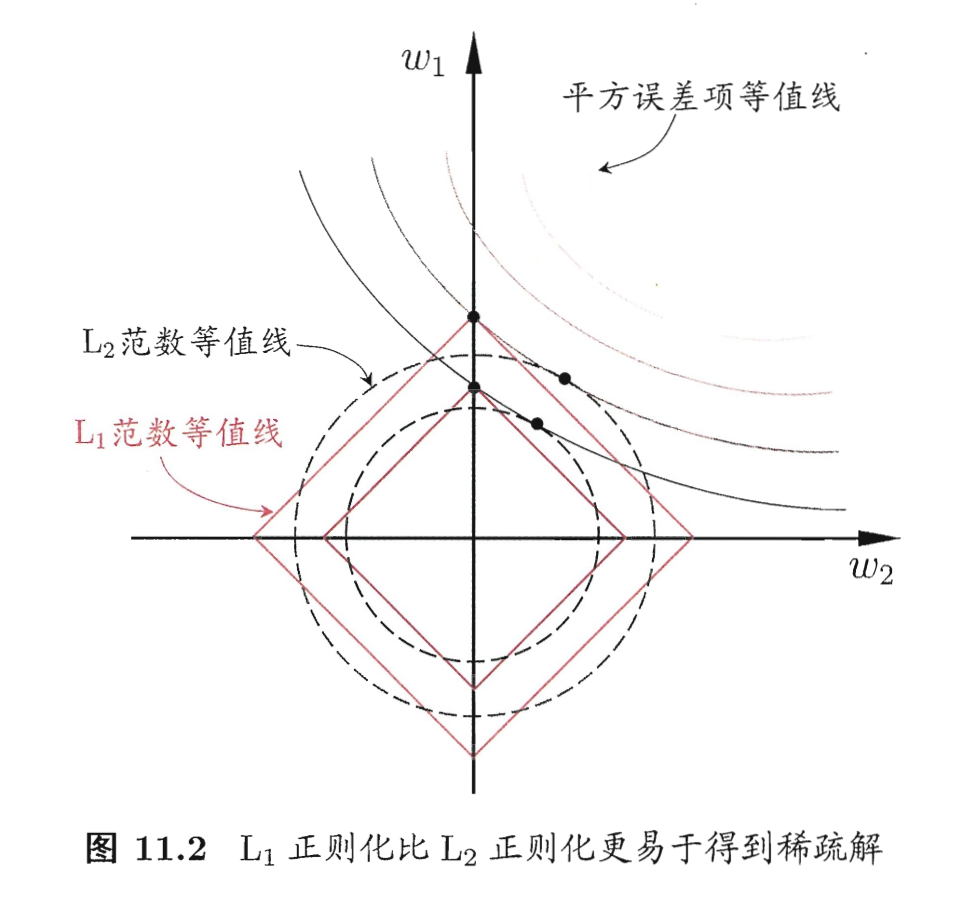
由于 L1范数稀疏的特性,相当于初始的 d 个特征中仅有对应着 w 的非零向量的特征才会出现在最终模型中,于是求解 L1范数正则化的结果是得到了仅采用一部分初始特征的模型。
求解: ?
近端梯度下降 Proximal Gradient Descent。


稀疏表示与字典学习
把数据集 D 考虑成一个矩阵,每行对应一个样本,每列对应一个特征。
特征选择所考虑的问题是特征具有稀疏性,即许多列与当前学习任务无关。去掉后,学习任务的难度可能会有所降低,涉及的计算和存储开销会减少,学的模型的可解释性也会提高。
另一种稀疏性:D 所对应的矩阵中存在很多零元素,但这些零元素并不是以整列、整行的形式存在的。

于是,当给定数据集 D 是稠密的,即普通非稀疏数据,能否将其转化为 sparse representation 稀疏表示,以享受稀疏性带来的好处呢?
dictionary learning 字典学习 ?
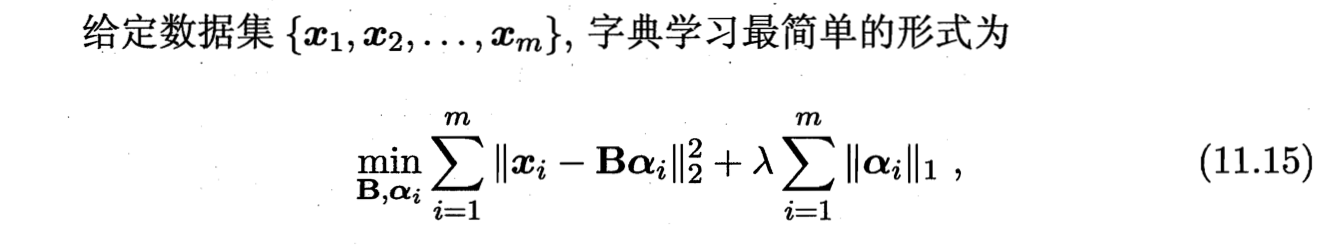

优化方式:
变量交替优化。

用户通过控制词汇量 k 的大小来控制字典的规模,从而影响到稀疏程度。
压缩感知 ?
基于部分信息来恢复全部信息。
matrix completion 矩阵补全



Ref
[1] 机器学习 - 周志华