A Few Useful Things to Know about Machine Learning 笔记
Pedro Domingos所写的关于Machine Learning中的black art的论文,总结了12点要注意避免的陷阱、重点关注的问题和一些常见问题的解答。
Introduction
Machine learning systems automatically learn programs from data. 被广泛应用在Web search, spam filters, recommender systems, ad placement, credit scoring, fraud detection, stock trading, drug design等许多领域。
本论文以classification为例,但在machine learning各领域都是通用的。
A Classifier is a system that inputs (typically) a vector of discrete and/or continuous feature values and outputs a single discrete value, the class.
例如:
A spam filter classifies email messages into “spam” or “not spam”, and its input may be a Boolean vector , where if the th word in the dictionary appears in the email and other wise.
A learner inputs a training set of examples , where is an observed input and is the corresponding output, and outputs a classifier. The test of the learner is whether this classifier produces the correct output for future examples .
Learning = Representation + Evaluation + Optimization
这许多算法都由这三个元素组成:
- Representation.
Choosing a representation for a learner is tantamount to choosing the set of classifiers that it can possibly learn. If a classifier is not in the hypothesis space, it cannot be learned. - Evaluation.
An evaluation function (also called objective function or scoring function) is needed to distinguish good classifiers from bad ones. - Optimization.
A method to search among the classifiers in the language for the highest-scoring one. The choice of optimization technique is key to the efficiency of the learner, and also helps determine the classifier produced if the evaluation function has more than one optimum.
The three components of learning algorithms
- Representation
Instances
K-nearest neighbor
Support vector machines
Hyperplanes
Naive Bayes
Logistic regression
Decision trees
Sets of rules
Propositional rules
Logic programs
Neural networks
Graphical models
Bayesian networks
Conditional random fields
- Evaluation
Accuracy/Error rate
Precision and recall
Squared error
Likelihood
Posterior probability
Information gain
K-L divergence
Cost/Utility
Margin
- Optimization
Combinatorial optimization
Greedy search
Beam search
Branch-and-bound
Continuous optimization
Unconstrained
Gradient descent
Conjugate gradient
Quasi-Newton methods
Constrained
Linear programming
Quadratic programming
它们之间的组合还是有倾向性的。
It’s Generalization that Counts
Machine Learning的本质目的就是generalize beyond the examples in the training set。不要用test data去污染调试中的classifier。
留出test data可能导致训练数据不够,此时可以用cross-validation的方法来缓和:把training data随机分成(比如)10组,每次留出1组作为test data,用剩下9组training。最后把各项参数的结果平均一下。
Data Alone is not Enough
归纳法和演绎法一样是知识杠杆,从很少的输入知识得到很多的输出知识,并且需要的输入知识更少。
选择Representation的时候就要想,哪种知识用这种方式表达更熨帖。
For example, if we have a lot of knowledge about what makes examples similar in our domain, instance-based methods may be a good choice. If we have knowldege about probabilistic dependencies, graphical models are a good fit. And if we have knowledge about what kinds of preconditions are required by each class, “IF … THEN …” rules may be the best option.
The most useful learners in this regard are those that don’t just have assumptions hard-wired into them, but allow us to state them explicitly, vary them widely, and incorporate them automatically into the learning.
Overfitting Has Many Faces
有时overfitting表现的不是很明显,可以用将generalization error分解成bias and variance的方法测试出来。
Bias is a learner’s tendency to consistently learn the same wrong thing.
Variance is the tendency to learn random things irrespective of the real signal.
用扔飞镖做比喻是这样:
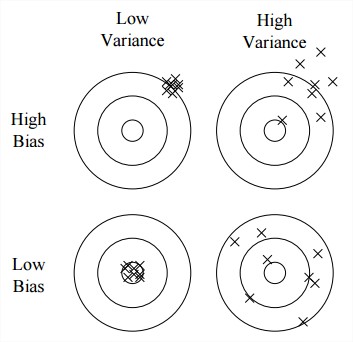
例子:
A linear learner has high bias, because when the frontier between two classes is not a hyperplane the learner is unable to induce it.
Decision trees don’t have this problem because they can represent any Bollean function, but on the other hand they can suffer from high variance: decision trees learned on different training sets generated by the same phenomenon are often very different, when in fact they should be the same.
Beam search has lower bias than greedy search, but higher variance, because it tries more hypotheses.
对抗Overfitting的一些方法:
- Cross-validation.
- Adding a regularization term to the evaluation function: penalize classifiers with more structure, thereby favoring smaller ones with less room to overfit.
- Perform a statistical significance test like chi-square before adding new structure, to decide whether the distribution of the class really is different with and without this structure.
Intuition Fails in High Dimensions
除了overfitting,Machine Learning领域最大的问题就是the curse of dimensionality了。
- Generalizing correctly becomes exponentially harder as the dimensionality (number of features) of the examples grows, because a fixed-size training set covers a dwindling fraction of the input space.
- More seriously, the similarity-based reasoning that machine learning algorithms depend on (explicitly or implicitly) breaks down in high dimensions.
- 我们在三维空间培养出的直觉在高维空间时往往是错的。
Theoretical Guarantees Are Not What They Seem
The main role of theoretical guarantees in machine learning is not as a criterion for practical decisions, but as a source of understanding and driving force for algorithm design.
Feature Engineering is the Key
从原始数据中选择feature是Machine Learning项目中花费最多精力的地方,不过也是很有趣的,除技术外还需要intuituion, creativity和black art。
收集数据、整合、清理和预处理很花时间,调试feature也消耗很多精力,算法实际跑的时间其实很短。
Feature engineering is domain-specific, while learners can be largely general-purpose.
More Data Beats a Cleverer Algorithm
After all, machine learning is all about letting data do the heavy lifting.
Machine Learning中缺的东西:time, memory, training data。过去最缺data,现在最缺time,数据太多,没时间处理。所以我们事实上还是倾向于设计聪明简单的算法。
这些不同的聪明算法往往结果也很相似。All learners essentially work by grouping nearby examples into the same class; the key difference is in the meaning of “nearby”.
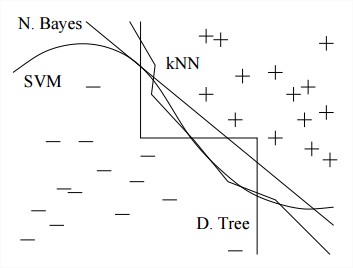
所以先试试那些简单的算法,比如Naive Bayes在Logistic Regression之前,K-Nearest neighbor在Support Vector Machines之前。
Learners可以分成两大类:
- Fixed-size learners whose representation has a fixed size, like linear classifiers.
- Variable-size learners whose representation can grow with the data, like decision trees.
要把Machine Learning techniques和Domain-specific knowledge结合起来,这需要人的智慧。
Learn Many Models, Not Just One
同一个问题用多种learner学习,然后整合在一起,效果会好很多。并且目前的趋势是,这个集合(Model ensembles)越大效果越好。
一些技术:
- bagging. Simplest, generate random variations of the training set by resampling, learn a classifier on each, and combine the results by voting. This works because it greatly reduces variance while only slightly increasing bias.
- boosting. Training examples have weights, and these are varied so that each new classifier focuses on the examples the previous ones tended to get wrong.
- stacking. The outputs of individual classifiers become the inputs of a “higher-level” learner that figures out how best to combine them.
Model Ensembles和Bayesian Model Averaging(BMA)不应被混淆。
BMA is the theoretically optimal approach to learning. In BMA, predictions on new examples are made by averaging the individual predictions of all classifiers in the hypothesis space, weighted by how well the calssifiers explain the training data and how much we believe in them a priori.
它们的不同之处:
Ensembles change the hypothesis space, and can take a wide variety of forms.
BMA assigns weights to the hypotheses in the original space according to a fixed formula.
Simplicity Does Not Imply Accuracy
Simpler hypotheses should be preferred because simplicity is a virtue in its own right, not because of a hypothetical connection with accuracy.
所以parameter的数量,hypotheses的复杂度,hypothesis space的大小并不能预示模型的准确性如何。
Representable Does Not Imply Learnable
某learner能表示某function并不代表这个function可以用此法learn到。所以还是要选择合适的learner。
Correlation Does Not Imply Causation
相关性不代表有因果关系,GRE里常常强调的啦。
之前提到的learner基本上都只能说明相关性而已。有相关性只暗示了也许有因果关系,值得继续调查。
Machine Learning时基本只有观察数据observational data,没有实验数据experimental data,如果能拿到实验数据就尽量拿到。
Conclusion
可以继续学习The Master Algorithm这本书,对Machine Learning的非技术性介绍。
一门在线课程:https://www.coursera.org/course/machlearning
可以找到很多相关视频:http://videolectures.net
一个常用的Machine Learning Toolkit是Weka。
Happy learning!