C++ Primer, 5th Edition 笔记4
终于补全了3的博文( TДT)可以开4了。
歹势啦。一本书拖了6个月还没整理完。
高级主题
标准库特殊设施
tuple类型
turple是类似pair的模板。每个确定的tuple类型的成员数目是固定的,但一个tuple类型的成员数目可以与另一个tuple类型不同。
当希望将一些数据组合成单一对象,但又不想麻烦地定义一个新数据结构来表示这些数据时,tuple很有用。
可以将tuple看作一个“快速而随意”的数据结构。

定义和初始化tuple
可以使用默认构造函数,或显式直接初始化,或使用make_tuple。
1 | tuple<size_t, size_t, size_t> threeD; // 三个成员都设置为0 |
访问tuple的成员需要使用一个名为get的标准库函数模板,从0开始计数。
1 | auto book = get<0>(item); // 返回item的第一个成员 |
查询tuple成员的数量和类型。
1 | typedef decltype(item) trans; // trans是item的类型 |
关系和相等运算符。比较的两侧必须具有相同数量的成员,且每对成员间的比较是合法的。
1 | tuple<string, string> duo("1", "2"); |
由于tuple定义了<和==运算符,可以将tuple序列传递给算法,并且可以在无序容器中将tuple作为关键字类型。
使用tuple返回多个值
tuple的一个常见用途是从一个函数返回多个值。
1 | // matches有三个成员:一家书店的索引和两个指向书店vector中元素的迭代器 |
使用函数返回的tuple
1 | void reportResults(istream& in, ostream& os, const vector<vector<Sales_data>>& files) |
bitset类型
参看之前整理的STL中的bitset类型。
正则表达式
介绍如何使用C++正则表达式库(RE库),是新标准库的一部分,定义在regex中。


使用正则表达式库
一个例子:查找违反规则“i除非在c之后,否则必须在e之前”的单词,程序输出是freind。
1 | // 查找不在字符c之后的字符串ei |
可以指定一些标志来控制regex对象的处理过程。

例子:识别不分大小写的文件扩展名。
1 | // 一个或多个字母或数字字符后接一个'.'再接"cpp"或"cxx"或"cc" |
一个正则表达式的语法是否正确是在运行时解析的。有错误时会抛出一个regex_error类型的异常。

避免创建不必要的正则表达式,正则表达式的编译是一个非常慢的操作。
正则表达式RE库类型必须与输入序列类型匹配。

匹配与Regex迭代器类型
sregex_iterator可以遍历匹配结果。如前所述,每种不同输入序列类型都有对应的特殊regex迭代器类型。

例子,扩展之前程序。假定名为file的string保存了我们要搜索的输入文件的全部内容。
1 | // 查找前一个字符不是c的字符串ei |

使用子表达式
正则表达式语法通常用括号表示子表达式。
1 | // r有两个子表达式:第一个是点之前表示文件名的部分,第二个表示文件扩展名 |
可以改写上上例,使之只打印文件名。
1 | if (regex_search(filename, results, r)) |
子表达式的常见用途是验证必须匹配特定格式的数据。

例子:匹配美国电话号码。
(\\()?表示区号部分可选的左括号。(\\d{3})表示区号。(\\))?表示区号部分可选的右括号。([-. ])?表示可选的分隔符。(\\d{3})表示号码的下三位数字。([-. ])?表示可选的分隔符。(\\d{4})表示号码的最后四位数字。
例子:读取一个文件,并用此模式查找与完整的电话号码模式匹配的数据,然后调用一个valid函数检查号码格式是否合法:
1 | string phone = "(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ])?(\\d{4})"; |
使用regex_replace
在输入序列中查找并替换一个正则表达式时,用regex_replace。
用一个符号$后跟子表达式的索引号来表示一个特定的子表达式。

例子:替换一个大文件中的电话号码。
将
morgan (111) 111-1111 111-111-1111
drew (111)111.1111
lee (111) 111-1111 1111111111 111.111-1111
转换为:
morgan 111.111.1111 111.111.1111
drew 111.111.1111
lee 111.111.1111 111.111.1111 111.111.1111
1 | int main() |
标准库定义了用来在替换过程中控制匹配或格式的标志。这些标志可以传递给函数regex_search或regex_match或是类smatch的format成员。

1 | // 只生成电话号码:使用新的格式字符串 |
此版本的程序生成:
111.111.1111 111.111.1111
111.111.1111
111.111.1111 111.111.1111 111.111.1111
随机数
从C++11开始,头文件random中定义了随机数库,包括随机数引擎类和随机数分布类。
| 随机数库的组成 | |
|---|---|
| 引擎 | 类型,生成随机unsigned整数序列 |
| 分布 | 类型,使用引擎返回服从特定概率分布的随机数 |
C++程序不应该使用库函数rand,而应使用default_random_engine类和恰当的分布类对象。
随机数引擎和分布
随机数引擎是函数对象类,其()运算符返回一个随机unsigned整数。
标准库定义了多个随机数引擎类,区别在于性能和随机性质量不同。每个编译器都会指定其中一个作为default_random_engine类型。

直接用引擎生成的输出的值范围通常与我们的需要不符。需要使用分布类型的对象。
1 | // 生成0到9之间(包含)均匀分布的随机数 |
随机数发生器是分布对象和引擎对象的组合。
注意一个给定的随机数发生器一直会生成相同的随机数序列。一个函数如果定义了局部的随机数发生器,应该将其(包括引擎和分布对象)定义为static的。否则,每次调用函数都会生成相同的序列。
1 | // 返回一个vector,包含100个均匀分布的随机数 |
可以设置随机数发生器种子。在创建引擎对象时提供种子,或者调用引擎的seed成员。
1 | default_random_engine e1(123); |
time返回以秒计的时间,这种方式只适用于生成种子的间隔为秒级或者更长的应用。
1 | default_random_engine e1(time(0)); // 稍微随机些的种子 |
其他随机数分布
C++11标准库定义了20种分布类型,这里未列举。

生成随机浮点数用uniform_real_distribution。如uniform_real_distribution<double> u(0,1);。
使用分布的默认结果类型uniform_real_distribution<> u(0,1);//默认生成double值。
生成非均匀分布的随机数normal_distribution<> n(4,1.5);//均值4,标准差1.5。
总返回一个bool值,返回true的概率是一个常数,默认是0.5.bernoulli_distribution b;
注意引擎和分布要在循环外定义,不然每次创建一个新引擎,会生成相同的值。
IO库再探
P666 不喜欢IO库,以后再说。
用于大型程序的工具
异常处理、命名空间、多重继承正好分别处理这些需求:
- 在独立开发的子系统之间协同处理错误的能力。
- 使用各种库(可能包含独立开发的库)进行协同开发的能力。
- 对比较复杂的应用概念建模的能力。
异常处理
异常处理机制允许程序中独立开发的部分能够在运行时就出现的问题进行通信并作出相应的处理。
抛出异常
在C++中,通过抛出throw一条表达式来引发raise一个异常。被抛出的表达式类型以及当前的调用链共同决定了哪段处理代码handler将被用来处理该异常。被选中的处理代码是在当前调用链中与抛出对象类型匹配的最近的处理代码。
当执行一个throw时,跟在throw后面的语句将不再被执行。程序的控制权从throw转移到与之匹配的catch模块。这意味着:沿着调用链的函数可能会提早退出;一旦程序开始执行异常处理代码,则沿着调用链创建的对象将被销毁。
栈展开stack unwinding过程沿着嵌套函数的调用链不断查找,直到找到了与异常匹配的catch字句为止;也可能一直没找到匹配的catch,则退出主函数后查找过程终止。
假设找到了一个匹配的catch子句,则程序进入该子句并执行其中的代码。当执行完这个catch子句后,找到与try块关联的最后一个catch子句之后的点,并从这里继续执行。如果没有找到匹配的catch子句,程序将退出。
在栈展开的过程中,运行类类型的局部对象的析构函数。因为这些析构函数是自动执行的,所以它们不应该抛出异常。一旦在栈展开的过程中析构函数抛出了异常,并且析构函数自身没能捕获到该异常,则程序将被终止。
当我们抛出一条表达式时,该表达式的静态编译时类型决定了异常对象exception object的类型。注意。如果一条throw表达式解引用一个基类指针,而该指针实际指向的是派生类对象,则抛出的对象将被切掉一部分,只有基类部分被抛出。
抛出指针要求在任何对应的处理代码存在的地方,指针所指向的对象都必须存在。
捕获异常
catch子句的异常声明的类型决定了处理代码所能捕获的异常类型。这个类型必须是完全类型,可以是左值引用,但不能是右值引用。
异常声明的静态类型将决定catch语句所能执行的操作。如果catch的参数是基类类型,则catch无法使用派生类特有的任何成员。
通常情况下,如果catch接受的异常与某个继承体系有关,则最好将该catch的参数定义成引用类型。
查找匹配的catch语句的过程中,第一个与异常匹配的catch语句将被选中,所以越是专门的catch越是应该置于整个catch列表的前端,同理继承链最底层的类的catch也应该放在前面。
有时一个单独的catch语句不能完整地处理某个异常。执行了某些校正工作之后,单签的catch可以重新抛出rethrowing将异常传递给另外一个catch语句。throw;。空的throw语句只能出现在catch语句或catch语句直接或间接调用的函数之内,如果在处理代码之外的区域遇到了空throw语句,编译器将调用terminate。
catch(...)可以捕获所有异常的语句,常与重新抛出语句一起使用。
函数try语句块与构造函数
要想处理构造函数初始值抛出的异常,必须将构造函数写成函数try语句块。
1 | template <typename T> |
可以处理构造函数体抛出的异常,也能处理成员初始化列表抛出的异常。
noexcept异常说明
知道函数不会抛出异常有助于简化调用该函数的代码。如果编译器确认函数不会抛出异常,就能执行某些特殊的优化操作。
关键字noexcept紧跟在函数的参数列表后面。还可以有一个可选的实参,该实参必须能转换为bool类型。和可以作为运算符表示给定的表达式是否会抛出异常。
1 | void recoup(int) noexcept; // 不会抛出异常 |
noexcept说明要么出现在该函数的所有声明语句和定义语句中,要么一次也不出现。该说明应该在函数的尾置返回类型之前。也可以在函数指针的声明和定义中指定noexcept。不能再typedef或类型别名中出现noexcept。在成员函数中,noexcept说明符需要跟在const及引用限定符之后,而在final、override或虚函数的=0之前。
编译器不能也不必在编译时验证异常说明。
异常说明与指针、虚函数和拷贝控制。
函数指针及该指针所指的函数必须具有一致的异常说明。不抛出的找不抛出的,可能抛出的谁都行。
1 | // recoupt和pf1都承诺不会抛出异常 |
如果一个虚函数承诺了它不会抛出异常,则后续派生出来的虚函数也必须做出相同的承诺。与之相反,如果基类的虚函数允许抛出异常,则派生类的对应函数既可以允许抛出异常,也可以不允许抛出异常。
1 | class Base { |
当编译器合成拷贝控制成员时,同时也生成一个异常说明。如果对所有成员和基类的所有操作都承诺了不会抛出异常,则合成的成员时noexcept的;否则就是noexcept(false)的。
异常类层次
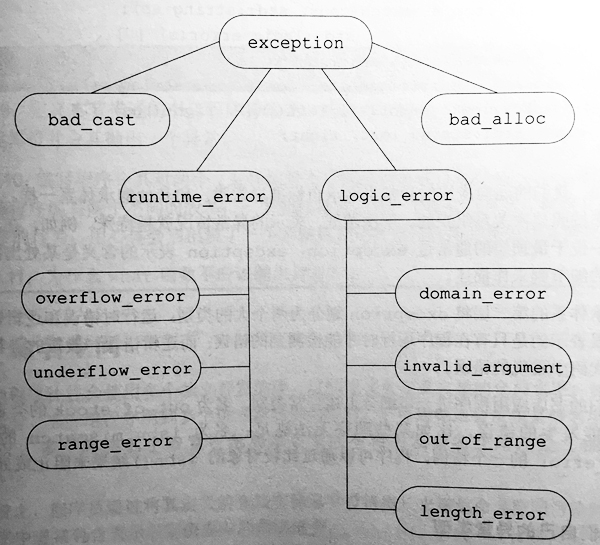
定义我们自己的异常类。
1 | class out_of_stock : public std::runtime_error |
使用时:
1 | // 如果参与加法的两个对象并非同一书籍,则抛出一个异常 |
命名空间
命名空间定义
1 | namespace cplusplus_primer { |
每个命名空间都是一个作用域。内部直接访问,外部要用::。
cplusplus_primer::World w = cpluspluc_primer::W("hello");
命名空间可以是不连续的。定义多个类型不相关的命名空间应该使用单独的文件分别表示每个类型。
注意我们不把#include放在命名空间内部,如果这么做了,隐含的意思是把头文件中所有的名字定义成该命名空间的成员。
模板特例化必须定义在原始模板所属的命名空间中。
1 | // 我们必须将模板特例化声明成std的成员 |
全局命名空间中的成员可以这样调用::member_name。
命名空间可以嵌套。A::B::member_name。
C++11添加了一种内联命名空间,可以直接被外层命名空间使用。定义内联命名空间的方式是在关键字namespace前添加关键字inline,在命名空间第一次定义的地方必须写上。
当应用程序的代码在第一次发布和另一次发布之间发生了改变时,常常会用到内联命名空间。比如早期版本都不内联,当前版本都内联,这样默认就用当前版本的。
未命名命名空间是指关键字namespace后紧跟花括号括起来的一系列声明语句。未命名命名空间中定义的变量拥有静态生命周期:它们在第一次使用前创建,直到程序结束才销毁。和其他命名空间不同,未命名的命名空间仅在特定的文件内部有效,其作用范围不会横跨多个不同的文件。应当用未命名的命名空间取代文件中的静态声明。
使用命名空间成员
命名空间别名用来为命名空间名字设定一个短一些的同义词。一个命名空间可以有好几个同义词或别名,所有别名都与命名空间原来的名字等价。
1 | namespace Qlib = cplusplus_primer::QueryLib; |
using声明如using std::vector;一次只引入命名空间的一个成员。可以出现在全局作用域、局部作用域、命名空间作用域以及类的作用域中。只是简单地令名字在局部作用域内有效。
using指示如using namespace std;使得某个特定命名空间中所有的名字都可见。可以出现在全局作用域、局部作用域和命名空间作用域中,但是不能出现在类的作用域中。令整个命名空间的所有内容变得有效。
如果我们提供了一个对std等命名空间的using指示而未做任何特殊控制的话,将重新引入由于使用了多个库而造成的名字冲突问题。
1 | namespace blip { |
命名空间本身的实现文件中可以使用using指示。
类、命名空间与作用域
名字查找还是从内到外。
当我们给函数传递一个类类型的对象/引用/指针时,除了在常规的作用域查找外还会查找实参类所属的命名空间。
std::move和std::forward最好带上限定语,因为很容易冲突,带上可以确保我们用的是标准库的版本。
友元声明与实参相关的查找有个诡异的现象:
1 | namespace A { |
重载与命名空间
using声明语句声明的是一个名字,而非一个特定的函数。using NS::print;。符合该名字的所有版本都被引入到当前作用域中。一个using声明引入的函数将重载该声明语句所属作用域中已有的其他同名函数。
using指示将命名空间的成员提升到外层作用域中,如果命名空间的某个函数与该命名空间所属作用域的函数同名,则命名空间的函数将被添加到重载集合中。与using声明不同的是,对于using指示来说,引入一个与已有函数形参列表完全相同的函数并不会产生错误,此时只要在调用时明确是命名空间中的函数版本还是当前作用域的版本即可。
多重继承与虚继承
多重继承是指从多个直接基类中产生派生类的能力。
多重继承
多重继承的派生类从每个基类中继承状态。派生类构造函数初始化所有基类。
最好还是每个类为自己定义构造函数吧。
类型转换与多个基类
小心这种二义性错误:
1 | void print(const Bear&); |
多重继承下的类作用域
当一个类拥有多个基类时,有可能出现派生类从两个或更多基类中继承了同名成员的情况。此时,不加前缀限定符直接使用该名字将引发二义性。
要想避免潜在的二义性,最好的办法是在派生类中为该函数定义一个新版本。
1 | double Panda::max_weight() const |
虚继承
如果派生类通过它的几个直接基类分别继承了同一个间接基类,需要使用虚继承,这样不论虚基类在继承体系中出现了多少次,在派生类中都只包含唯一一个共享的虚基类子对象。
虚派生只影响从指定了虚基类的派生类中进一步派生出的类,它不会影响派生类本身。所以不太直观。
1 | // 关键字public和virtual顺序随意 |
构造函数与虚继承
在虚派生中,虚基类是由最低层的派生类初始化的。
也就是说继承体系上此类后的的每个类在初始化的时候都要写对虚基类的初始化,编译器自会选择最低层的那个。
虚基类总是先于非虚基类构造,与它们在继承体系中的次序和位置无关。
特殊工具与技术
控制内存分配
重载new和delete
使用new表达式时,实际执行了三步操作:
1 | // new表达式 |
- new表达式调用一个名为
operator new(或者operator new[])的标准库函数。该函数分配一块足够大的、原始的、未命名的内存空间以便存储特定类型的对象(或者对象的数组)。 - 编译器运行相应的构造函数以构造这些对象,并为其传入初始值。
- 对象被分配了空间并构造完成,返回一个指向该对象的指针。
使用delete表达式时,实际执行了两步操作:
1 | // delete表达式 |
- 对sp所指的对象或者arr所指的数组中的元素执行对应的析构函数。
- 编译器调用名为
operator delete(或者operator delete[])的标准库函数释放内存空间。
如果应用程序希望控制内存分配的过程,则它们需要定义自己的operator new函数和operator delete函数。
当自定义了全局的operator new函数和operator delete函数后,我们就担负起了控制动态内存分配的职责。这两个函数必须是正确的:因为它们是程序整个处理过程中至关重要的一部分。
可以定义在全局作用域中或定义为成员函数。当编译器发现一条new表达式或delete表达式后,将在程序中查找可供调用的operator函数。如果被分配(释放)的对象是类类型,则编译器首先在类及其基类的作用域中查找。此时如果该类含有operator new成员或operator delete成员,则相应的表达式将调用这些成员。否则,编译器在全局作用域查找匹配的函数。此时如果编译器找到了用户自定义的版本,则使用该版本执行new表达式或delete表达式;如果没找到,则使用标准库定义的版本。
可以用作用域运算符如::new只在全局作用域中查找匹配的operator new函数。
标准库定义了operator new函数和operator delete函数的8个重载版本。其中前4个版本可能抛出bad_alloc异常,后4个版本不会抛出异常:
1 | // 这些版本可能抛出异常 |
自定义的版本必须位于全局作用域或者类作用域中。当定义成类的成员时,它们是隐式静态的。因为operator new用在对象构造之前而operator delete用在对象销毁之后,所以这两个成员new和delete必须是静态的,而且它们不能操纵类的任何数据成员。
可以在重载中使用定义在C语言<cstdlib>头文件中的malloc和free函数。
1 | void *operator new(size_t size) |
定位new表达式
对于operator new分配的内存空间来说,应该使用new的定位new(placement new)形式构造对象。
1 | new (place_address) type |
其中place_address必须是一个指针,同时在initializers中提供一个(可能为空的)以逗号分隔的初始值列表,该初始值列表将用于构造新分配的对象。
当仅通过一个地址值调用时,定位new,使用operator new(size_t, void*)这个函数简单地返回指针实参,然后由new表达式负责在指定的地址初始化对象以完成整个工作。事实上,定位new允许我们在一个特定的、预先分配的内存地址上构造对象。
当只传入一个指针类型的实参时,定位new表达式构造对象但是不分配内存。
很多时候定位new与allocator的construct成员非常相似,但它们之间有一个重要的区别。我们传给construct的指针必须指向同一个allocator对象分配的空间,但是传给定位new的指针无须指向operator new分配的内存。传给定位new表达式的指针甚至不需要指向动态内存。
可以显式调用析构函数。调用析构函数会销毁对象,但是不会释放内存。
1 | string *sp = new string("a value"); // 分配并初始化一个string对象 |
运行时类型识别
运行时类型识别(run-time type identification, RTTI)的功能由两个运算符实现:
typeid运算符,用于返回表达式的类型。dynamic_cast运算符,用于将基类的指针或引用安全地转换成派生类的指针或引用。
这两个运算符特别适用于以下情况:我们想使用基类对象的指针或引用执行某个派生类操作并且该操作不是虚函数。
使用RTTI必须要加倍小心。在可能的情况下,最好定义虚函数而非直接接管类型管理的重任。
dynamic_cast运算符
dynamic_cast的使用形式如下:
1 | dynamic_cast<type*>(e) // e必须是一个有效的指针 |
如果dynamic_cast的转换目标是指针类型并且失败了,则结果为0;如果转换目标是引用类型并且失败了,则将抛出一个bad_cast异常。
我们可以对一个空指针执行dynamic_cast,结果是所需类型的空指针。
在条件部分执行dynamic_cast操作可以确保类型转换和结果检查在同一条表达式中完成。
1 | if (Derived* dp = dynamic_cast<Derived*>(bp)) |
对于引用类型的dynamic_cast,失败时抛出名为std::bad_cast的异常,定义在标准库头文件<typeinfo>中。
1 | void f(const Base& b) |
typeid运算符
typeid(e),其中e可以是任意表达式或类型的名字。typeid操作的结果是一个常量对象的引用,该对象的类型是标准库类型type_info或者type_info的公有派生类型。type_info类定义在typeinfo头文件中。
通常使用typeid比较两条表达式的类型是否相同,或者比较一条表达式的类型是否与指定类型相同。
当typeid作用于指针(而非指针所指的对象)时,返回的结果是该指针的静态编译时类型。
1 | Derived* dp = new Derived; |
使用RTTI
示例:继承层次中类的相等比较。
1 | // 类声明 |
type_info类
type_info类必须定义在typeinfo头文件中,提供以下操作。
| type_info的操作 | |
|---|---|
t1 == t2 |
如果type_info对象t1和t2表示同一种类型,返回true;否则返回false |
t1 != t2 |
如果type_info对象t1和t2表示不同的类型,返回true;否则返回false |
t.name() |
返回一个C风格字符串,表示类型名字的可打印形式。类型名字的生成方式因系统而异 |
t1.before(t2) |
返回一个bool值,表示t1是否位于t2之前。before所采用的的顺序关系时依赖于编译器的 |
type_info类没有默认构造函数,并且它的拷贝和移动构造函数以及赋值运算符都被定义为删除的。创建type_info对象的唯一途径是使用typeid运算符。
name()返回值的唯一要求是,类型不同则返回的字符串必须有区别。
枚举类型
枚举属于字面值常量类型。枚举值不一定唯一。
C++包含两种枚举:限定作用域的和不限定作用域的。
- 限定作用域的枚举类型(scoped enumeration)。C++11后。
枚举成员的名字遵循常规的作用域规则,并且在枚举类型的作用域外是不可访问的。
enum class EnumName {Enum1, Enum2, Enum3}; - 不限定作用域的枚举类型(unscoped enumeration)。
枚举成员的作用域与枚举类型本身的作用域相同。
enum EnumName {Enum1, Enum2, Enum3};
可以没有名字。
enum {Enum1 = 5, Enum2 = 1, Enum3 = 1};
要想初始化enum对象或者为enum对象赋值,必须使用该类型的一个枚举成员或者该类型的另一个对象。EnumName en = EnumName::Enum2;
不限定作用域的枚举类型的对象或枚举成员可以自动地转换为整形,限定作用域的枚举类型不可以。
C++11中可以指定enum是某种整数类型。指定类型可以确保在一种实现环境中编译通过的程序所生成的代码在其他实现环境中生成的代码一致。
1 | enum intValues : unsigned long long |
C++11中可以提前声明enum。enum的前置声明必须指定其成员大小。
1 | enum intValues : unsigned long long; // 不限定作用域的,必须指定成员类型 |
类成员指针
成员指针是指可以指向类的非静态成员的指针。一般情况下,指针指向一个对象,但是成员指针指示的是类的成员,而非类的对象。
成员指针的类型囊括了类的类型以及成员的类型。当初始化一个这样的指针时,我们令其指向类的某个成员,但是不指定该成员所属的对象;直到使用成员指针时,才提供成员所属的对象。
示例:
1 | class Screen |
数据成员指针
需要指明所属的类。
1 | // pdata可以指向一个常量(非常量)Screen对象的string成员 |
与成员访问运算符.和->类似,也有两种成员指针访问运算符:.*和->*,这两个运算符使得我们可以解引用指针并获得该对象的成员:
从概念上来说,这些运算符执行两步操作:它们首先解引用成员指针以得到所需的成员;然后像成员访问运算符一样,通过对象.*或指针->*获取成员。
1 | Screen myScreen, *pScreen = &myScreen; |
为Screen类添加一个静态成员,令其返回指向contents成员的指针。从右向左阅读函数的返回类型,可知data返回的是一个指向Screen类的const string成员的指针。
1 | class Screen |
pdata指向Screen类的成员而非实际数据。要想使用pdata,必须把它绑定到Screen类型的对象上:
1 | // 获得myScreen对象的contents成员 |
成员函数指针
指向类的成员函数的指针。类似于任何其他函数指针,指向成员函数的指针也需要指定目标函数的返回类型和形参列表。如果成员函数是const成员或者引用成员,则必须将const限定符或引用限定符包含进来。
1 | // pmf是一个指针,它可以指向Screen的某个常量成员函数 |
和普通函数指针不同,成员函数和指向该成员的指针之间不存在自动转换规则。
1 | // pmf指向一个Screen成员,该成员不接受任何实参且返回类型是char |
使用.*或者->*运算符作用于指向成员函数的指针,以调用类的成员函数:
注意括号必不可少。
1 | Screen myScreen, *pScreen = &myScreen; |
可以使用类型别名或typedef,易读一些。
1 | // Action是一种可以指向Screen成员函数的指针,它接受两个pos实参,返回一个char |
也可以将指向成员函数的指针作为某个函数的返回类型或形参类型。指向成员的指针形参也可以拥有默认形参。
1 | // action接受一个Screen的引用,和一个指向Screen成员函数的指针 |
用途:对于普通函数指针和指向成员函数的指针来说,一种常见的用法是将其存入一个函数表当中。如果一个类含有几个相同类型的成员,则这样一张表可以帮助我们从这些成员中选择一个。
示例:Screen类含有几个负责移动光标的成员函数。参数与返回值都相同。此时可以再定义一个move函数,使其可以调用其中任意一个函数并执行对应的操作。
1 | class Screen |
将成员函数用作可调用对象
要想通过一个指向成员函数的指针进行函数调用,必须首先利用.*运算符或->*运算符将该指针绑定到特定的对象上。因此与普通的函数指针不同,成员指针不是一个可调用对象,这样的指针不支持函数调用运算符。
从指向成员函数的指针获取可调用对象的一种方法是使用标准库function。必须提供成员的调用形式。
例如:这是告诉function,string类里的empty是一个接受string参数并返回bool值的函数。
1 | function<bool (const string&)> fcn = &string::empty; |
从指向成员函数的指针获取可调用对象的第二种方法是使用标准库功能mem_fn来让编译器负责推断成员的类型。也定义在<functional>头文件中,和function不同的是,mem_fn可以根据成员指针的类型推断可调用对象的类型,无需用户显式指定。
1 | find_if(svec.begin(), svec.end(), mem_fn(&string::empty)); |
mem_fn生成的可调用对象可以通过对象调用,也可以通过指针调用:
1 | auto f = mem_fn(&string::empty); // f接受一个string或者一个string* |
也可使用bind生成一个可调用对象。
1 | // 选择范围中的每个string,并将其bind到empty的第一个隐式实参上 |
嵌套类
nested class是独立的,与外层类基本没什么关系。特别是,外层类的对象和嵌套类的对象是相互独立的。在嵌套类的对象中不包含任何外层类定义的成员;类似的,在外层类的对象中也不包含任何嵌套类定义的成员。
嵌套类的名字在外层作用域中是可见的,在外层类作用域之外不可见。
外层类对嵌套类的成员没有特殊的访问权限,同样,嵌套类对外层类的成员也没有特殊的访问权限。
嵌套类在其外层类中定义了一个类型成员。和其他成员类似,该类型的访问权限由外层类决定。位于外层类public部分的嵌套类实际上定义了一种可以随处访问的类型;位于外层类protected部分的嵌套类定义的类型只能被外层类及其友元和派生类访问;位于外层类private部分的嵌套类定义的类型只能被外层类的成员和友元访问。
在嵌套类在其外层类之外完成真正的定义之前,它都是一个不完全类型。
返回类型不在类的作用域中。
1 | class TextQuery |
union:一种节省空间的类
联合union是一种特殊的类。可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。当我们给union的某个成员赋值之后,该union的其他成员就变成未定义的状态了。分配给一个union对象的存储空间至少要能容纳它的最大的数据成员。和其它类一样,一个union定义了一个新类型。
union不能含有引用类型的成员。在C++11中,含有构造函数或析构函数的类类型也可以作为union的成员类型。union可以为其成员指定public、protected、private等保护标记。默认情况下,union的成员都是公有的。
union可以定义包括构造函数和析构函数在内的成员函数。但是由于union既不能继承自其他类,也不能作为基类使用,所以在union中不能含有虚函数。
1 | // Token类型的对象只有一个成员,该成员的类型可能是下列类型中的任意一种 |
为union的一个数据成员赋值会令其他数据成员变成未定义的状态,因此,使用union时,必须清楚地知道当前存储在union中的值到底是什么类型。如果用错了,不是吓唬你,可能会崩溃的!
匿名union一旦定义,编译器就自动为该union创建一个未命名的对象:
1 | union { // 匿名union |
匿名union不能包含受保护的成员或私有成员,也不能定义成员函数。
可以使用类管理union成员。
1 | class Token |
局部类
类可以定义在某个函数的内部,成为局部类local class。局部类定义的类型只在定义它的作用域内可见。
局部类的所有成员(包括函数在内)都必须完整定义在类的内部。因此,局部类的作用与嵌套类相比相差很远。
局部类中不允许声明静态数据成员,因为根本没法定义。
局部类对其外层作用域中名字的访问权限受到很多限制:局部类只能访问外层作用域定义的类型名、静态变量以及枚举成员。如果局部类定义在某个函数内部,则该函数的普通局部变量不能被该局部类使用。
1 | int a, val; |
固有的不可移植的特性
为了支持低层编程,C++定义了一些固有的不可移植nonportable的特性。所谓不可移植的特性是指因机器而异的特性,当我们将含有不可移植特性的程序从一台机器转移到另一台机器上时,通常需要重新编写该程序。
位域
类可以将其(非静态)数据成员定义成位域(bit-field),在一个位域中含有一定数量的二进制位。当一个程序需要向其他程序或硬件设备传递二进制数据时,通常会用到位域。
位域在内存中的布局是机器相关的。
位域的类型必须是整型或枚举类型。
通常情况下最好将位域设为无符号类型,存储在带符号类型中的位域的行为将因具体实现而定。
位域的声明形式是在成员名字之后紧跟一个冒号以及一个常量表达式,该表达式用于指定成员所占的二进制位数。
取地址运算符&不能作用于位域,因此任何指针都无法指向类的位域。
1 | typedef unsigned int Bit; |
volatile限定符
volatile的确切含义与机器有关,只能通过阅读编译器文档来理解。要想让使用了volatile的程序在移植到新机器或新编译器后仍然有效,通常需要对该程序进行某些改变。
直接处理硬件的程序常常包含这样的数据元素,它们的值由程序直接控制之外的过程控制。例如,程序可能包含一个由系统时钟定时更新的变量。当对象的值可能在程序的控制或检测之外被改变时,应该将该对象声明为volatile。关键字volatile告诉编译器不应对这样的对象进行优化。
使用方式和const很像。
只有volatile的成员函数才能被volatile的对象调用。
1 | volatile int display_register; // 该int值可能发生改变 |
合成的拷贝对volatile对象无效,需要自己定义拷贝和赋值操作,不过这其实没什么意义。
链接指示:extern "C"
C使用链接指示(linkage directive)指出任意非C函数所用的语言。
要想把C代码和其他语言(包括C语言)编写的代码放在一起使用,要求我们必须有权访问该语言的编译器,并且这个编译器与当前的C编译器是兼容的。
如extern "Ada",extern "FORTRAN"等。
声明一个非C++的函数:
链接指示可以有两种形式:单个的或复合的。链接指示不能出现在类定义或函数定义的内部。同样的链接指示必须在函数的每个声明中都出现。
例子:cstring头文件的某些C函数是如何声明的:
1 | // 可能出现在C++头文件<cstring>中的链接指示 |
链接指示与头文件:
可以这样一次性建立多个链接。
1 | // 复合语句链接指示 |
指向extern "C"函数的指针:
编写函数所用的语言是函数类型的一部分。因此,对于使用链接指示定义的函数来说,它的每个声明都必须使用相同的链接指示。而且,指向其他语言编写的函数的指针必须与函数本身使用相同的链接指示:
1 | // pf指向一个C函数,该函数接受一个int返回void |
指向C函数的指针与指向C++函数的指针是不一样的类型。
链接指示对整个声明都有效:
例如:这条声明语句指出f1是一个不返回任何值的C函数。它有一个类型是函数指针的形参,其中的函数接受一个int形参返回为空。这个链接指示不仅对f1有效,对函数指针同样有效。当我们调用f1时,必须传给它一个C函数的名字或者指向C函数的指针。
1 | // f1是一个C函数,它的形参是一个指向C函数的指针 |
因为链接指示同时作用于声明语句中的所有函数,所以如果希望给C++函数传入一个指向C函数的指针,则必须使用类型别名。
1 | // FC是一个指向C函数的指针 |
导出C++函数到其他语言:
1 | // calc函数可以被C程序调用 |
不过要注意,可被多种语言共享的函数的返回类型或形参类型受到很多限制,比如C根本就不懂类。
有时需要在C和C++中编译同一个源文件,可以利用__cplusplus。
1 |
|
重载函数与链接指示:
C语言不支持函数重载。因此如果在一组重载函数中有一个是C函数,则其余的必定都是C++函数:
1 | class SmallInt {}; |
≖‿≖✧
开心!新年第一天,完成任务一项!ᕙ(⇀‸↼ )ᕗ