Natural Language Processing 课程笔记
Coursera上Natural Language Processing课程的笔记。
Michael Collins, Columbia University
PS. 老师的PPT做得好有品位!简单、有效、节制美。声音也好听!
中间停了3个月,重新开始学习。
授课大纲为:
Topics covered include:
- Language modeling.
- Hidden Markov models, and tagging problems.
- Probabilistic context-free grammars, and the parsing problem.
- Statistical approaches to machine translation.
- Log-linear models, and their application to NLP problems.
- Unsupervised and semi-supervised learning in NLP.
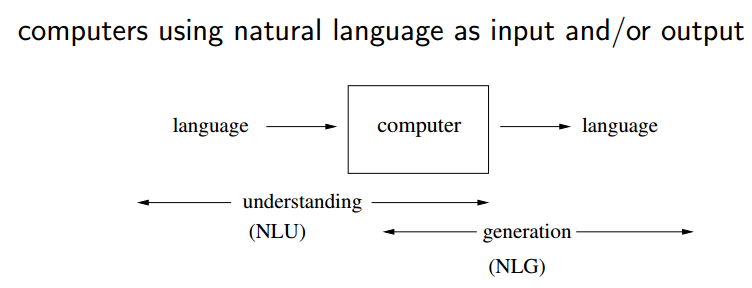
Introduction to Natural Language Processing
What is Natural Language Processing(NLP)?
Key Applications
- Machine Translation: e.g., Google Translation from Arabic
- Information Extraction:


- Text Summarization:

- Dialogue Systems

Basic NLP Problems
- Tagging

n是none,v是verb,等等。
na不是entity,sc是start company,cc是continued company,sl是start location,cl是continued location。 - Parsing
Why is NLP Hard?
[example from L.Lee]
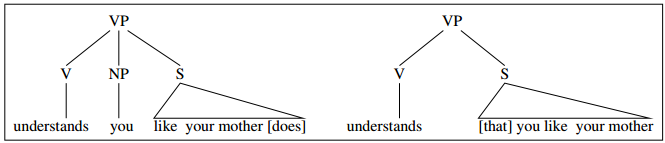
“At last, a computer that understands you like your mother”
Ambiguity
- (*) It understands you as well as your mother understands you
- It understands (that) you like your mother
- It understands you as well as it understands your mother
1 and 3: Does this mean well, or poorly?
Ambiguity at Many Levels
At the acoustic level (speech recognition):
- “…a computer that understands you like your mother”
- “…a computer that understands you lie cured mother”
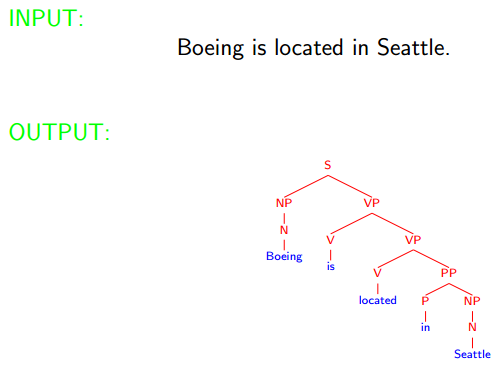
At the syntactic level:
Different structures lead to different interpretations.
At the semantic (meaning) level:
Two definitions of “mother”
- a woman who has given birth to a child
- a stringy slimy substance consisting of yeast cells and bacteria; is added to cider or wine to produce vinegar
This is an instance of word sense ambiguity
- They put money in the bank = buried in mud?
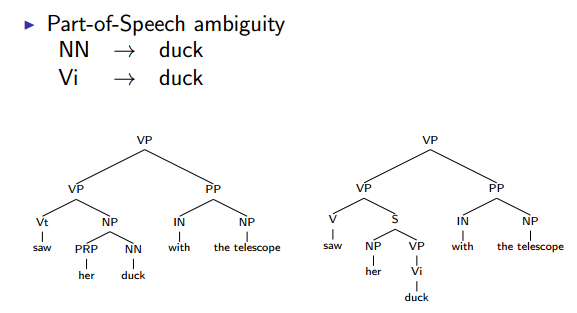
- I saw her duck with a telescope
At the discourse (multi-clause) level:
- Alice says they’ve built a computer that understands you like your mother
- But she … 有两种选择
… doesn’t know any details
… doesn’t understand me at all
This is an instance of anaphora, where she co-referees to some other discourse entity.
What will this course be about?
Course Coverage
- NLP sub-problems: part-of-speech tagging, parsing, word-sense disambiguation, etc.
- Machine learning techniques: probabilistic context-free grammars, hidden markov models, estimation/smoothing techniques, the EM algorithm, log-linear models, etc.
- Applications: information extraction, machine translation, natural language interfaces…
A Syllabus
- Language modeling, smoothed estimation
- Tagging, hidden Markov models
- Statistical parsing
- Machine translation
- Log-linear models, discriminative methods
- Semi-supervised and unsupervised learning for NLP
Prerequisites
- Basic linear algebra, probability, algorithms
- Programming skills 本课需要Python或Java
Books
Comprehensive notes for the course will be provided at
http://www.cs.columbia.edu/~mcollins
Additional useful background:
Jurafsky and Martin:
Speech and Language Processing (2nd Edition)
The Language Modeling Problem
Introduction to the language modeling problem


Why on earth would we want to do this?
- Speech recognition was the original motivation. (Related problems are optical character recognition, handwriting recognition.)
比如识别有两种可能,recognize speech和wreck a nice beach。如果有language model,我们就知道哪个的可能性大一些。 - The estimation techniques developed for this problem will be VERY useful for other problems in NLP.
A Naive Method

最简单的一个方法,统计每句出现次数,求概率。
Markov Processes
Markov Processes
Trigram models的实现基于Markov Processes。
- Consider a sequence of random variables . Each random variable can take any value in a finite set . For now we assume the length is fixed (e.g., ).
- Our goal: model
First-Order Markov Processes
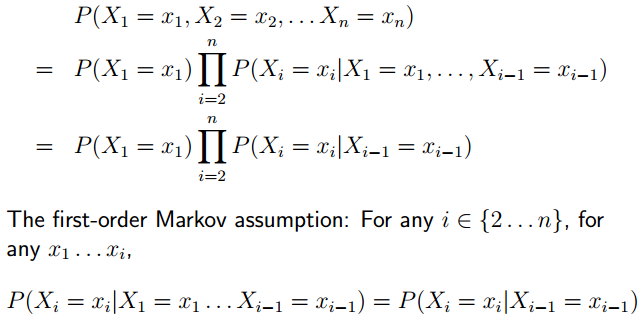
第一步是exact的,例如:。
第二步是markov assumption。
Second-Order Markov Processes
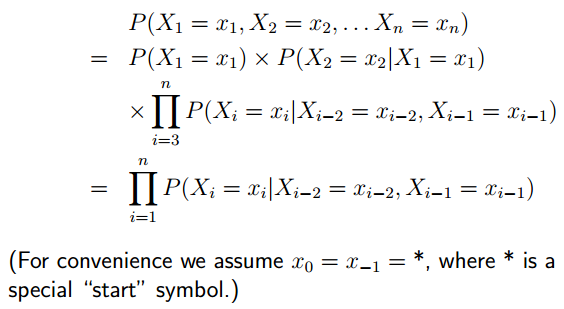
Modeling Variable Length Sequences

Trigram Language Models
很好用又易于实现。
Trigram Language Models

An Example

The Trigram Estimation Problem

它的问题是Sparse Data Problems,parameters太多。

Evaluating language models: perplexity
Perplexity

Some Intuition about Perplexity

Perplexity有点像所有这些词中有效的词有多少。从而可以看出这个model好不好,值越小越好。
Typical Values of Perplexity

Some History: “Syntactic Structures”
Parameter Estimation in Language Models
Linear Interpolation
The Bias-Variance Trade-Off

Linear Interpolation
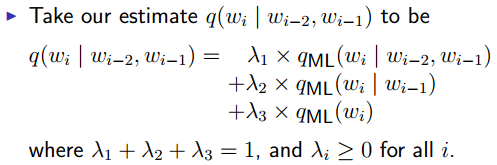
证明:

How to estimate the values?

Allowing the 's to vary

不同情况下用不同。
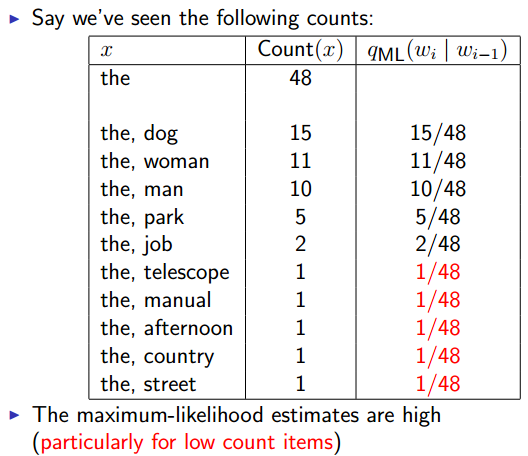
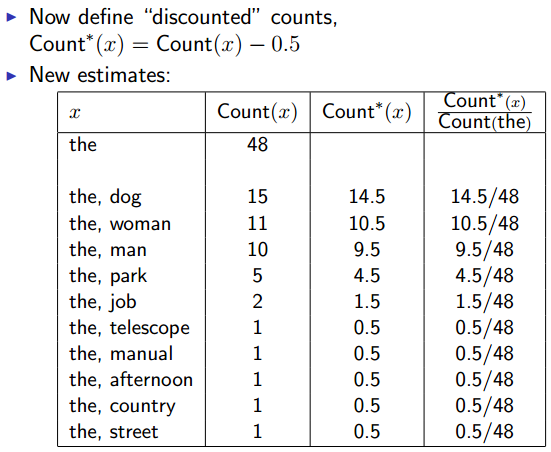
Discounting Methods
Discounting Methods
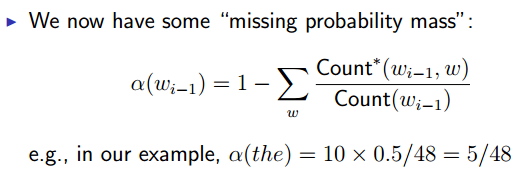
Katz Back-Off Models (Bigrams)

Katz Back-Off Models (Trigrams)

Summary

Tagging Problems, and Hidden Markov Models
The Tagging Problem
Part-of-Speech Tagging

主要问题还是ambiguity。
Named Entity Recognition

Named Entity Extraction as Tagging
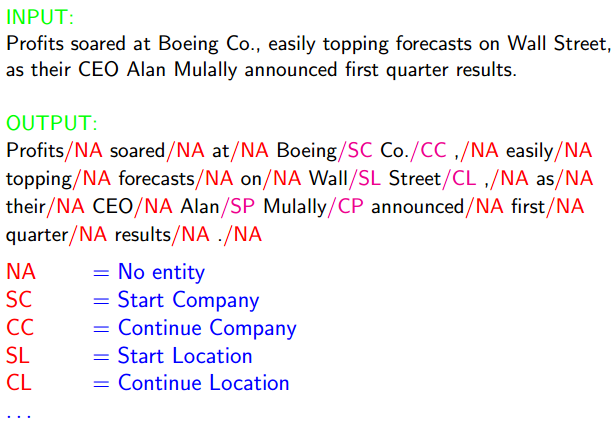
Our Goal

Two Types of Constraints

Generative models, and the noisy-channel model, for supervised learning
Supervised Learning Problems - Conditional models

本例中x,y大概为:
x(i) = the dog laughs, y(i) = DT NN VB
也叫Discriminative Model。
Generative Models

Note那一行就是Bayes rule。
Generative Model比也叫Discriminative Model更灵活通用。
Decoding with Generative Models

由于p(x)并不受y的变化影响,被约去。
Hidden Markov Model (HMM) taggers
Basic definitions
Hidden Markov Models

Trigram Hidden Markov Models(Trigram HMMs)

q代表Trigram Parameters,e代表Emission Parameters。
An Example

Why the Name?

即
Parameter estimation
Smoothed Estimation
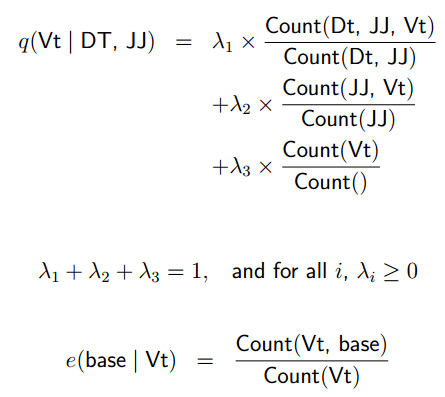
回顾前面的linear interprelation method。
q包含trigram ml estimate/bigram ml estimate/unigram ml estimate。
这个方式的问题是:e(x|y)=0 for all y if x is never seen in the training data.有一个词没有出现过的话,整个p都是0了。
Dealing with Low-Frequency Words
Example:
Profits soared at Boeing Co. , easily topping forecasts on Wall Street, as their CEO Alan Mulally announced first quarter results.
其中Mulally这个词在training set中可能没有出现过。那么
e(Mulally|y)=0 for all tags y 所以 p(x1, …, xn, y1, …, yn+1) = 0 for all tag sequences y1, …, yn+1。
解决方法:

Example:
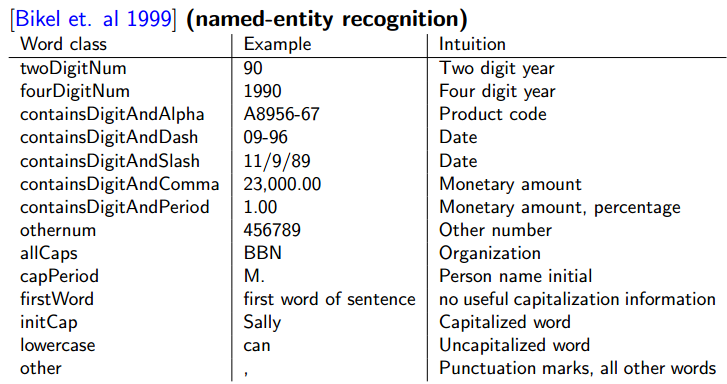

这样就有类似e(firstword|NA)或e(initcap|SC)这样的e了。缺点是需要人手动整理分类。
The Viterbi algorithm
The Problem

Brute Force Search is Hopelessly Inefficient
The Viterbi Algorithm Defination

Example:

k是1到n。u是Sk-1。v是Sk。
A Recursive Definition
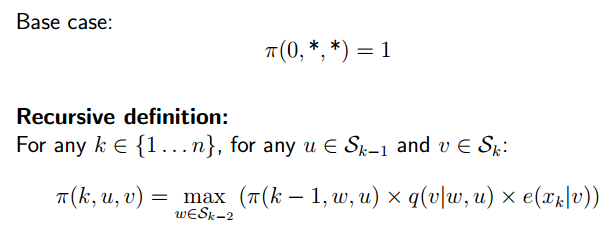
动态规划。
Justification for the Recursive Definition:

The Viterbi Algorithm

The Viterbi Algorithm with Backpointers

只是动态规划的具体实现,记录tag。
The Viterbi Algorithm: Running Time

Summary
Pros and Cons

Parsing, and Context-Free Grammars
An Introduction to the Parsing Problem
Parsing(Syntactic Structure)

Syntactic Formalisms
- Work in formal syntax goes back to Chomsky’s PhD thesis in the 1950s.
Book “Syntactic Structures” - Examples of current formalisms: minimalism, lexical functional grammer(LFG), head-driven phrase-structure grammar(HPSG), tree adjoining grammars(TAG), categorial grammars.
今天学的context-free grammar是这些modern grammar的基础。
Data for Parsing Experiments

是supervised learning,Training data是人手动标的,Penn WSJ Treebank。
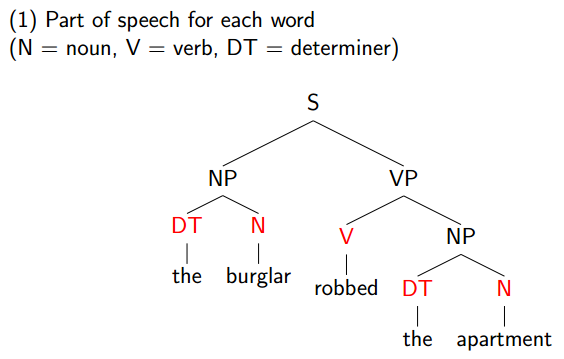
The Information Conveyed by Parse Trees
1.Part of speech for each word
2.Phrases
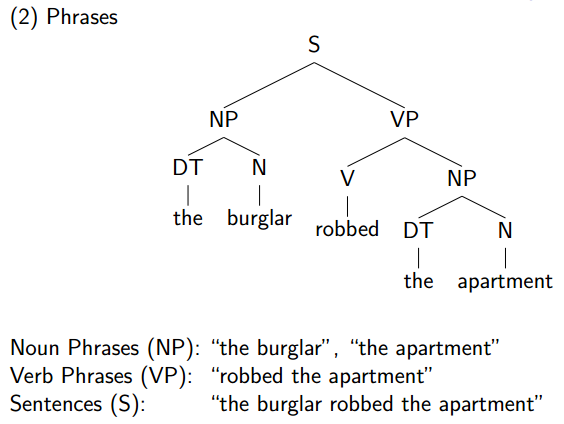
3.Useful Relationships
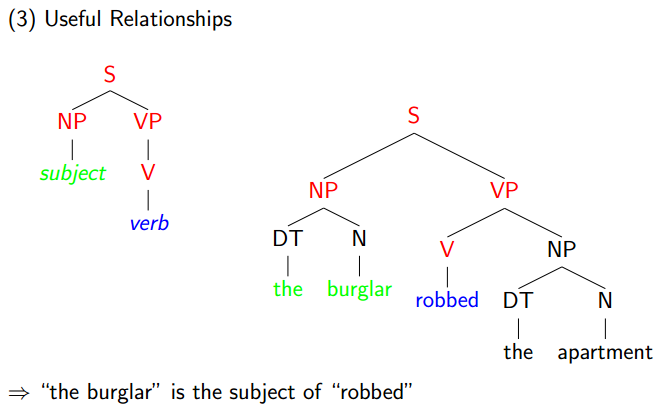
An Example Application: Machine Translation


有Syntactic Structure后任务容易了很多。
Context Free Grammars
Context-Free Grammars Definition

A Context-Free Grammar for English

Left-Most Derivations

An Example:

Properties of CFGs

CFG - Context Free Grammars
An Example of Ambiguity
The Problem with Parsing: Ambiguity
有14种解释。
A Brief(!) Sketch of the Syntax of English
A Brief Overview of English Syntax

A Fragment of a Noun Phrase Grammar
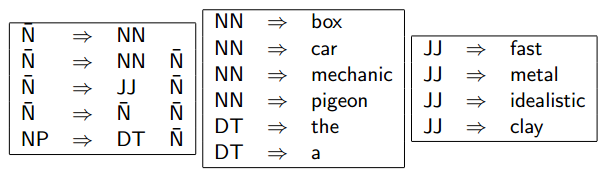
可以试着组合出很多种tree。
Prepositions, and Prepositional Phrases
An Extended Grammar
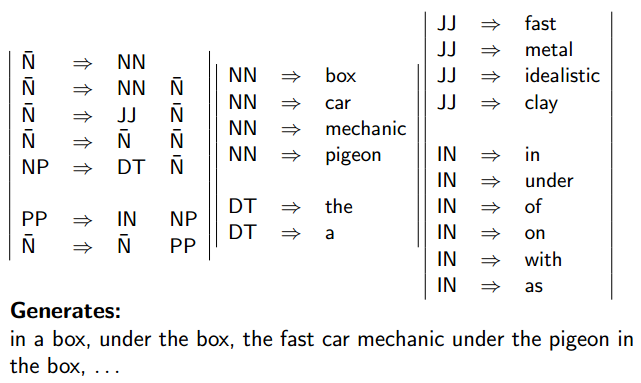
Verbs, Verb Phrases, and Sentences

PPs Modifying Verb Phrases

Complementizers, and SBARs

More Verbs

Coordination

We’ve Only Scratched the Surface…

Examples of Ambiguous Structures
Sources of Ambiguity - Part-of-Speech ambiguity
Sources of Ambiguity - Prepositional Phrase Attachment
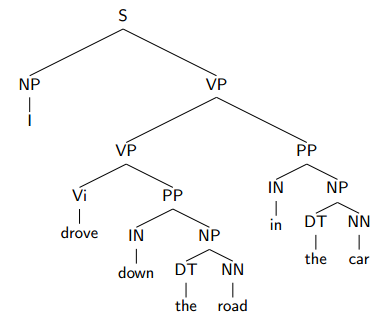
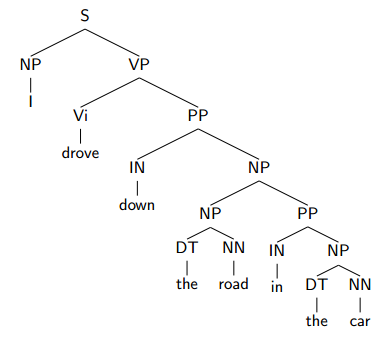
前文有提到。
另一个例子:Two analyses for: John was believed to have been shot by Bill。by Bill修饰shot或believed。
人类会更倾向于让prepositions去修饰the most recent verb in a sentence.
Sources of Ambiguity - Noun Premodifiers
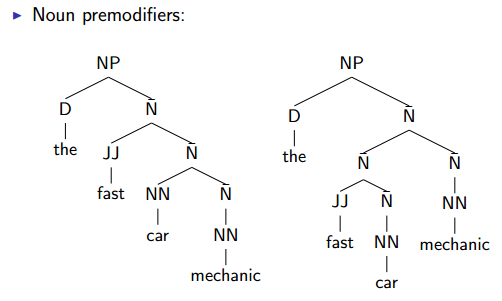
左边那个fast相当于修饰car mechanic了。右边是fast car修饰mechanic。
Probabilistic Context-Free Grammars (PCFGs)
为每个rule添加概率,这样生成不同parse tree的几率也不一样了。
又旧又简单效果也不好,但是别人的基础,稍加改进之后表现就很好了。
Probabilistic Context-Free Grammars (PCFGs)
A Probabilistic Context-Free Grammar (PCFG)
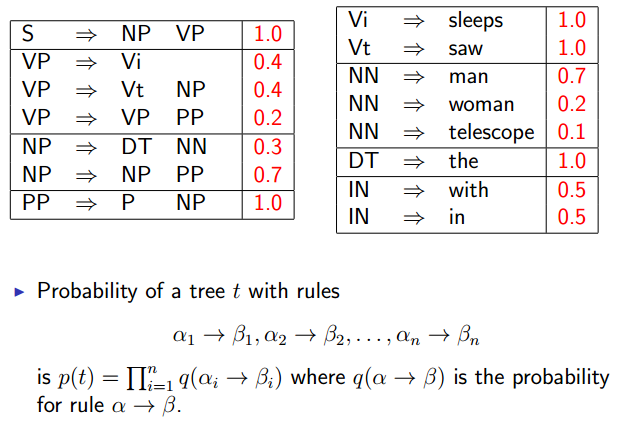
An Example:
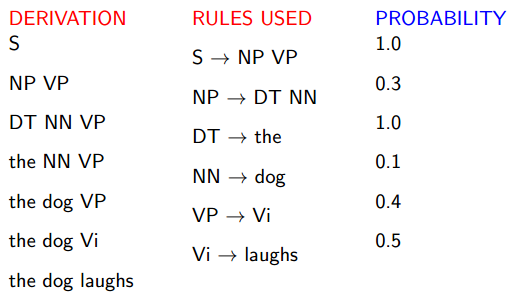
Properties of PCFGs

Deriving a PCFG from a Treebank
Treebank是什么:

用Treebank计算PCFG

PCFGs
Booth and Thompson (1973) showed that a CFG with rule probabilities correctly defines a distribution over the set of derivations provided that:
- The rule probabilities define conditional distributions over the different ways of rewriting each non-terminal.
- A technical condition on the rule probabilities ensuring that the probability of the derivation terminating in a finite number of steps is 1. (This condition is not really a practical concern.)
The CKY Algorithm for parsing with PCFGs
** Parsing with a PCFG**
Brute Force还是完全不可能的。
Chomsky Normal Form

R那行的意思就是要么分成两个非终端节点,要么就是终端节点。如果多于两个,就定义变量分成几条Rule,每条都是两个。
有了这个标准形式就可以用动态规划了。
A Dynamic Programming Algorithm

词i到词j之间形成X形式的可能组成方式中概率最大的那个。
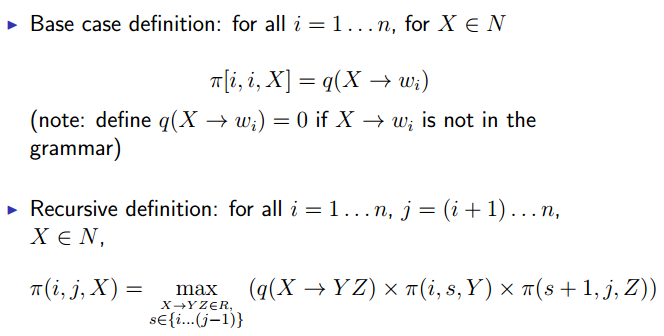
s是split point。
The Full Dynamic Programming Algorithm
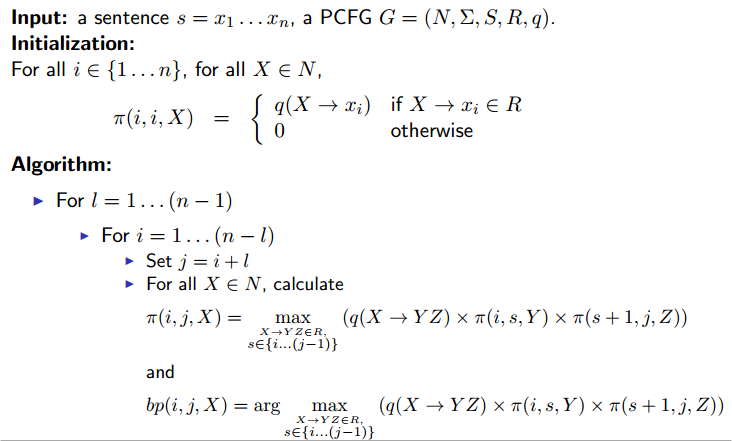
A Dynamic Programming Algoritm for the Sum

Summary
- PCFGs augments CFGs by including a probability for each rule in the grammar.
- The probability for a parse tree is the product of probabilities for the rules in the tree.
- To build a PCFG-parsed parser:
1.Learn a PCFG from a treebank.
2.Given a test data sentence, use the CKY algorithm to compute the highest probability tree for the sentence under the PCFG.
Weeknesses of PCFGs
PCFGs = Probabilistic Context-Free Grammars
只有大约72%的准确率。而现代parser大约有92%的准确率。
- Lack of sensitivity to lexical information
- Lack of sensitivity to structural frequencies
Lack of Sensitivity to Lexical Information
每个假设都是独立的。且和word完全无关。
PP Attachment Ambiguity

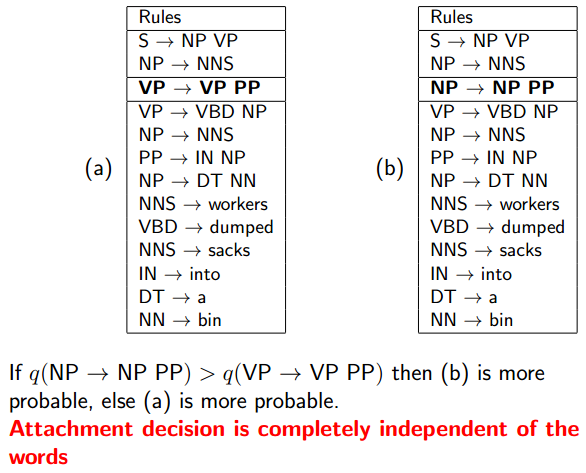
本例中粗体那条一条就决定了整个树的成败。
Coordination Ambiguity
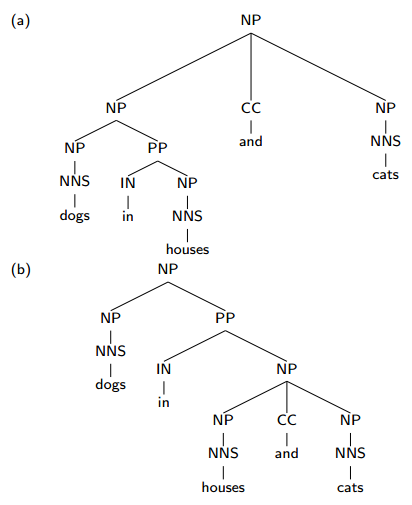
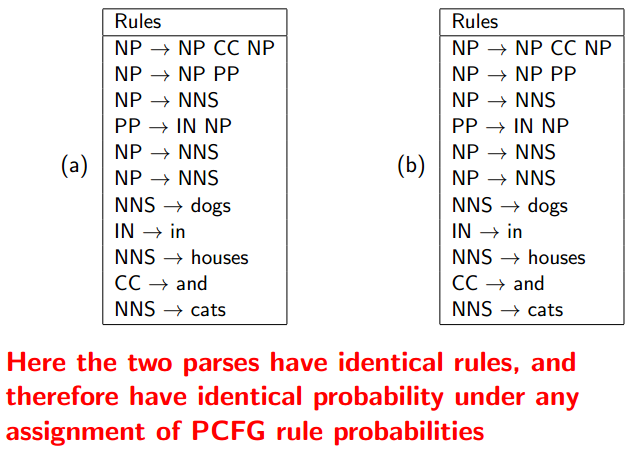
本例中两棵树的概率完全相等,不分伯仲,因为只是顺序不同而已。
Lack of Sensitivity to Structural Frequencies
Structural Preferences: Close Attachment
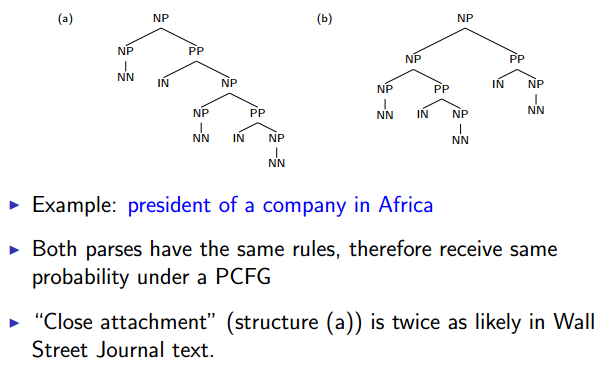
in Africa可以修饰president或company。就近原则。
Previous example: John was believed to have been shot by Bill
Here the low attachment analysis (Bill does the shooting) contains same rules as the high attachment analysis (Bill does the believing), so the two analyses receive same probability.
Lexicalized PCFGs
Lexicalization of a treebank
Heads in Context-Free Rules
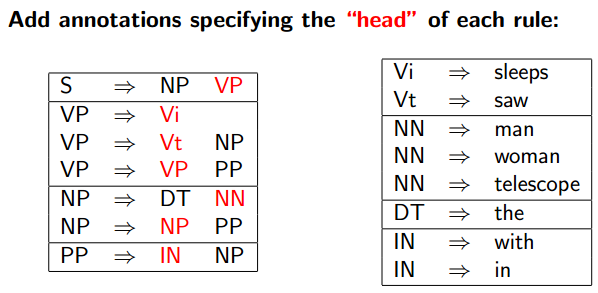

Rules which Recover Heads
原始的Treebank里没有Head信息,要用这些Rule来Recover。
An Example for NPs:

An Example for VPs:

Adding Headwords to Trees
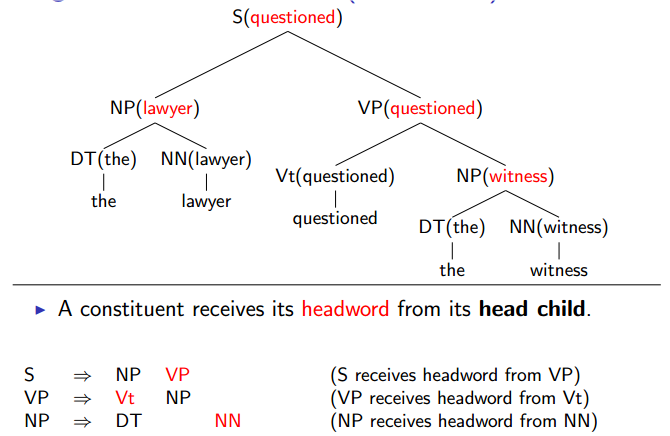
Lexicalized probabilistic context-free grammars
Chomsky Normal Form
前文有讲过。
Lexicalized Context-Free Grammars in Chomsky Normal Form

增加了标明head从哪儿来。
Example:

Parameters in a Lexicalized PCFG

参数变多。
Parsing with Lexicalized CFGs

Parameter estimation in lexicalized probabilistic context-free grammars
An Example:
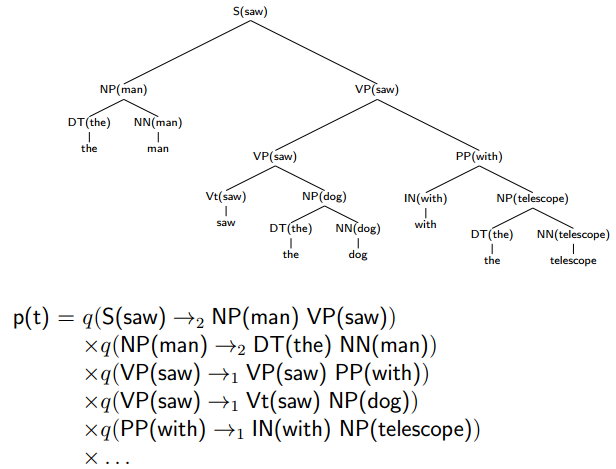
A Model from Charniak (1997)


ML = maximum likelihood
qML = count(A) / count(B)
一组之和为1。
逐步一般化以平滑。
Other Important Details

binalize。
Accuracy of lexicalized probabilistic context-free grammars
Method 1: Constituents/Precision and Recall
Evaluation: Representing Trees as Constituents
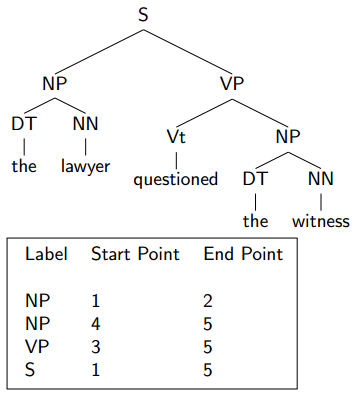
Precision and Recall
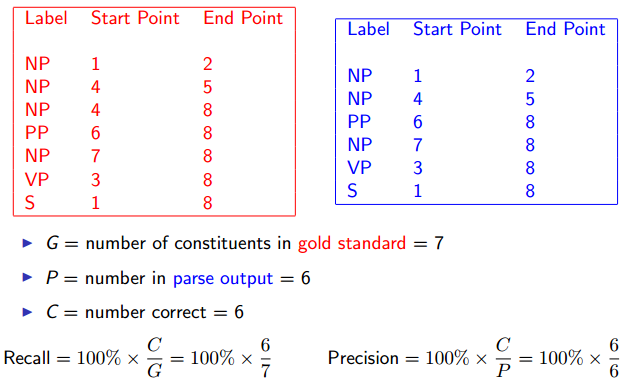
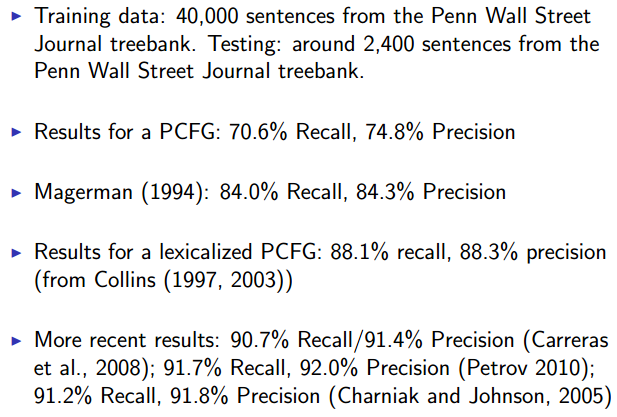
Results
Method 2: Dependency Accuracies
Example:
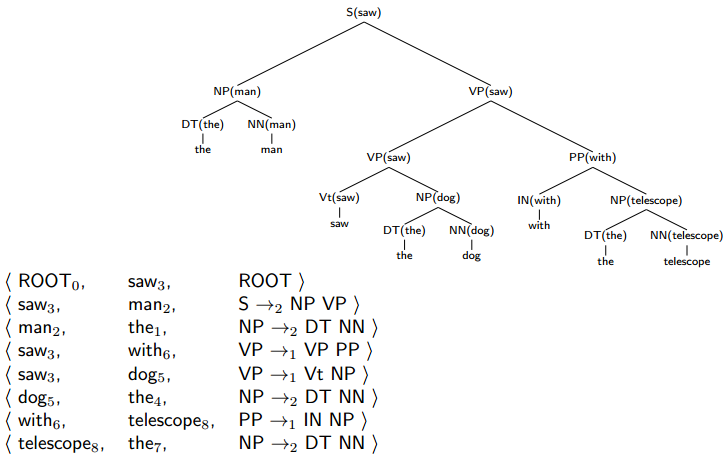
三列分别是:head word(h)/modifier word(w)/rule。
Dependency Accuracies:

Strengths and Weaknesses of Modern Parsers:

Summary
- Key weakness of PCFGs: lack of sensitivity to lexical information.
- Lexicalized PCFGs:
Lexicalize a treebank using head rules.
Estimate the parameters of a lexicalized PCFG using smoothed estimation. - Accuracy of lexicalized PCFGs: around 88% in recovering constituents or dependencies.
Introduction to Machine Translation(MT)
Challenges in machine translation
Challenges: Lexical Ambiguity

从英语翻译到西班牙语,英语同词不同义在翻译时的不同选择。
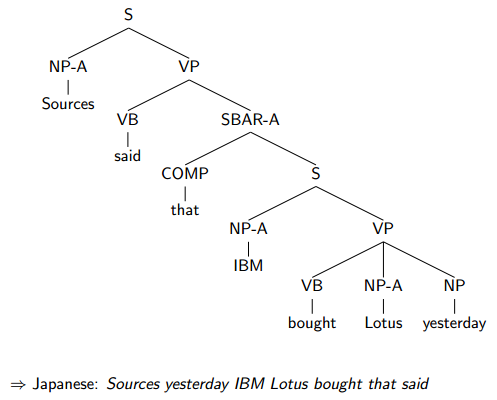
Challenges: Differing Word Orders

老例子,英语与日语的语法中词的顺序不同。
Syntactics Structure is not Preserved Across Translations
Example from Dorr et. al, 1999

float这个动词在下面不再那么动词了。此例中floated对应floating,into对应entered。
Syntactic Ambiguity Causes Problems
Example from Dorr et. al, 1999

是John用棍子打狗,还是狗自己有棍子。with the stick是修饰hit还是dog。
Pronoun Resolution
Example from Dorr et. al, 1999

it可以是The computer,也可以是the data。
Classical machine translation
都是Rule-based。
Direct Machine Translation
- Translation is word-by-word.
- Very little analysis of the source text(e.g., no syntactic or semantic analysis).
- Relies on a large bilingual directionary. For each word in the source language, the dictionary specifies a set of rules for translating that word.
- After the words are translated, simple reordering rules are applied (e.g., move adjectives after nouns when translating from English to French).
An Example:

Some Problems with Direct Machine Translation:

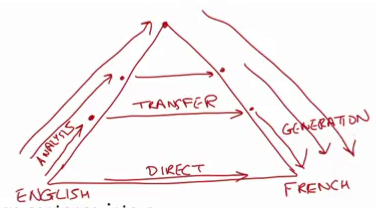
Transfer-Based Approaches
Three phases in translation:
Analysis: Analyze the source language sentence; for example, build a syntactic analysis of the source language sentence.
Transfer: Convert the source-language parse tree to a target-language parse tree.
Generation: Convert the target-language parse tree to an output sentence.
- The “parse trees” involved can vary from shallow analyses to much deeper analyses (even semantic representations).
- The transfer rules might look quite similar to the rules for direct translation systems. But they can now operate on syntactic structures.
- It’s easier with these approaches to handle long-distance reorderings.
- The Systran systems are a classic example of this approach.
Interlingua-Based Translation
Two phases in translation:
- Analysis: Analyze the source language sentence into a (language-independent) representataion of its meaning.
- Generation: Convert the meaning representation into an output sentence.
One Advantage: If we want to build a translation system that translates between languages, we need to develop analysis and generation systems. With a transfer based system, we’d need to develop sets of translation rules.
Disadvantage: What would a language-independent representation look like?
- How to represent different concepts in a interlingua?
- Different languages break down concepts in quite different ways:
German has two words for wall: one for an internal wall, one for a wall that is outside.
Japanese has two words for brother: one for an elder brother, one for a younger brother.
Spanish has two words for leg: pierna for a human’s leg, pata for an animal’s leg, or the leg of a table. - An interlingua might end up simple being an intersection of these different ways of breaking down concepts, but that doesn’t seem very satisfactory…
A Pyramid Represnts These Three
A brief introduction to statistical MT
- Parallel corpora are available in several language pairs.
- Basic idea: use a parallel corpus as a training set of translation examples.
- Classic example: IBM work on French-English translation, using the Canadian Hansards. (1.7 million sentences of 30 words or less in length). (Early 1990s)
- Google Translation用的就是这个。
- Idea goes back to Warren Weaver (1949): suggested applying statistical and cryptanalytic techniques to translation.
Warren Weaver, 1949, in a letter to Norbert Wiener:
"… one naturally wonders if the problem of translation could conceivably be treated as a problem in cryptography. When I look at an article in Russian, I say: “This is really written in English, but it has been coded in some strange symbols. I will now proceed to decode.”
The Noisy Channel Model

e是一个英文句子。f是一个法文句子。
p(e): a probability to any sentence in English.
p(f|e): the conditional probability of any French sentence given an English sentence.

Example from Koehn and Knight tutorial:


The IBM Translation Models
First Generation Translation Systems.
IBM Model做到了1-5,2就已经很不错了。
IBM Model 1
IBM Model 1: Alignments - Introduction
- How do we model ?
- English sentence has words ,French sentence has words .
- An alignment identifies which English word each French word originated from.
- Formally, an alignment is , where each .
- There are possible alignments.
- e.g., ,
= And the program has been implemented
= Le programme a ete mis en application
One alignment is {2,3,4,5,6,6,6}
Another (bad!) alignment is {1,1,1,1,1,1,1}
Alignments in the IBM Models
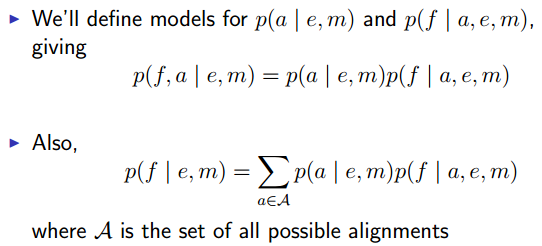
例如 p(le chien aboie,{1,2,3} | the dog barks, 3)
A By-Product: Most Likely Alignments

IBM Model现在不做翻译,反而主要来找最可能的Alignment了。
An Example Alignment

IBM Model 1: Alignments
Step 1:
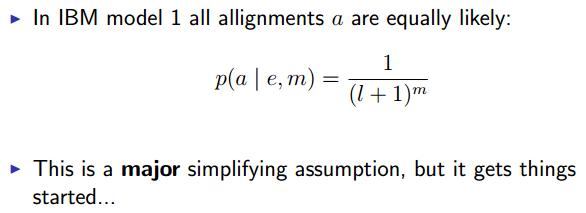
IBM Model 1: Translation Probabilities
Step 2:
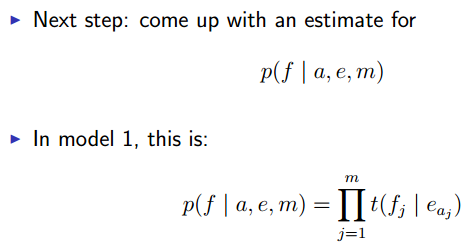
例如:
e = NULL the dog barks 于是l=3
a = {1, 2, 3}
f = le chian aboie 于是m=3
p(f|a,e,m) = t(le|the) x t(chien|dog) x t(aboie|barks)
又一个例子:

IBM Model 1: The Generative Process
Generation:

An Example Lexical Entry

IBM Model 2
** IBM Model 2 - Introduction**

只是a部分的模型不同。
An Example


IBM Model 2: The Generative Process

Recovering Alignments

EM Training of Models 1 and 2
Parameter estimation in models 1 and 2.
The Parameter Estimation Problem

Parameter Estimation if the Alignments are Observed

在已有a关系的情况下,只需要计算count相除就可以。

Parameter Estimation with the EM Algorithm

迭代改进。

Justification for the Algorithm

Summary

Phrase-based Translation Models
Second Generation Translation Systems.
Late 1990s.
Google Translate.
Learning Phrases From Alignments
Phrase-Based Models

An Example (from tutorial by Koehn and Knight):
Calculate PB Lexicon Pairs using IBM Model 2.


Representation as Alignment Matrix
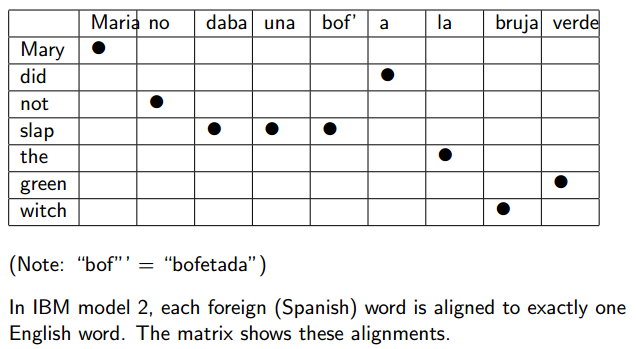
Finding Alignment Matrices
问题:
- Alignments are often “noisy”.
- “Many to One” instead of “Many to Many”.
解决方法:
- Step 1: train IBM model 2 for p(f|e), and come up with most likely alignment for each (e,f) pair.
- Step 2: train IBM model 2 for p(e|f) and come up with most likely alignment for each (e,f) pair.
- We now have two alignments:
take intersection of the two alignments as a starting point.


Heuristics for Growing Alignments
- Only explore alignment in union of p(f|e) and p(e|f) alignments.
- Add one alignment point at a time.
- Only add alignment points which align a word that currently has no alignment.
- At first, restrict ourselves to alignment points that are “neighbors” (adjacent or diagonal) of current alignment points.
- Later, consider other alignment points.
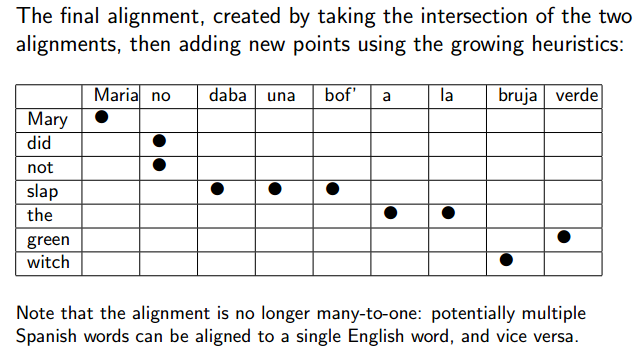
Extracting Phrase Pairs from the Alignment Matrix
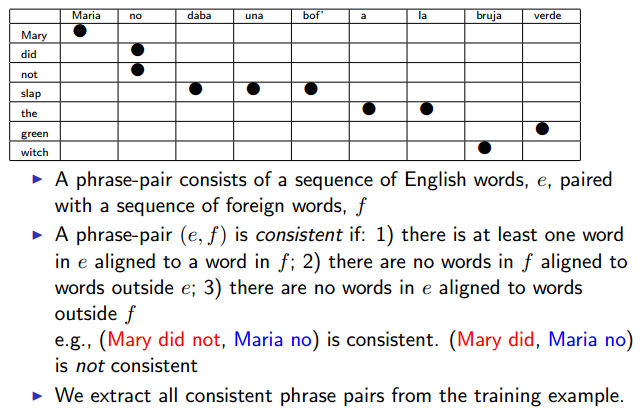
Probabilities for Phrase Pairs
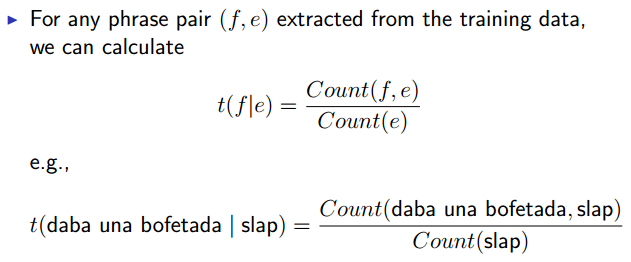
An Example Phrase Translation Table
A Phrase-Based Model
A Sketch


6是因为跳过了6个词,那是一个负值,为了不让两种语言句子结构跳跃太大的penalty。


Decoding of Phrase-based Translation Models
Definition of the Decoding Problem
Phrase-based Translation

Phrase-based Models: Definitions

Phrased-based Translation: Definitions

s: start point.
t: end point.
e: sequence of 1 or more english words.
Definitions

Valid Derivations

第三条:distortion limit: a hard constraint on how far phrases can move.
两个(s,t,e)组之间的距离不能离太远。前一组的尾与后一组的头之间。
这个方法很僵化,已被淘汰。
y(x)数量会随着句子长度指数增长。
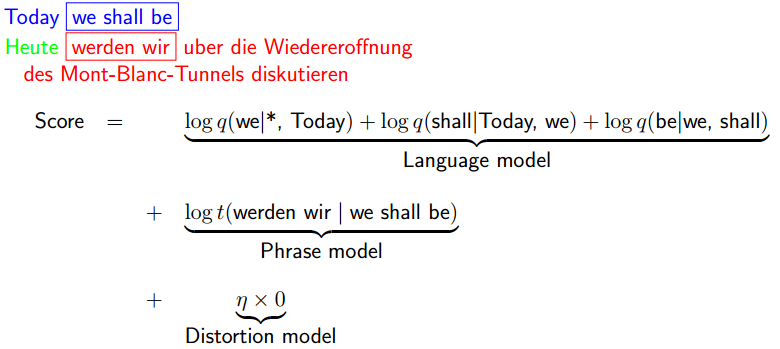
Scoring Derivations

An Example:

We must also take this critic seriously.
- Langauge Model. 这个英语句子有多可能
log q(we|**)+log(must|*,we)+log(also|we,must)+log(the|must,also)+… - Phrase Scores. 这个英语句子与德语有多匹配
g(1,3,we must also)+g(7,7,take)+g(4,5,the critic)+… - Distortion Scores. 对语法结构差太多的惩罚
|1-1|x{zeta}+|3+1-7|x{zeta}+|7+1-4|x{zeta}+|5+1-6|x{zeta}
The Decoding Algorithm
上面的问题NP hard,需要用到heuristic的算法。
Decoding Algorithm: Definitions

例如(we, must, 1100000, 2, -2.5)
中间的int有点像占位,哪些词被翻译了。
States, and the Search Space

可以表现为这样的树。
Transitions

ph(q)就是每个state的可行选择。
The next function
We define next(q,p) to be the state formed by combining state q with phrase p.
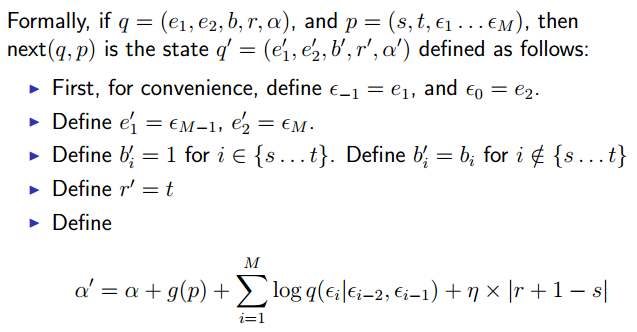
The Equality Function
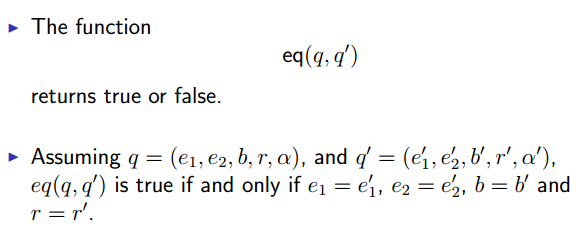
判断两个state是否相同。
The Decoding Algorithm

Definition of Add(Q, q’, q, p)
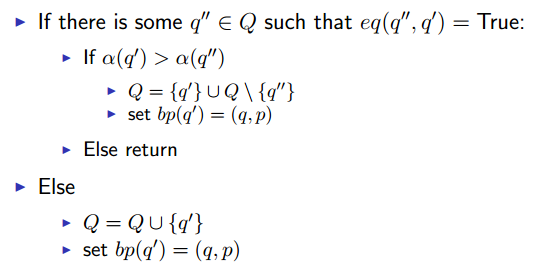
如果走到了同一个state,谁分数高留谁。
Definition of beam(Q)
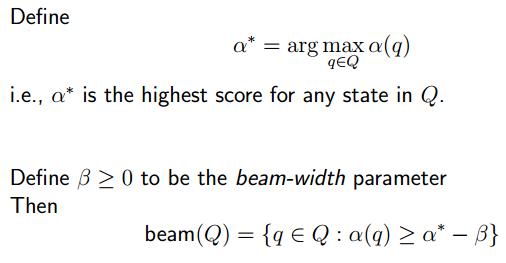
图中不应该有arg,错误。
比最高分低太多的直接删了。
Log-linear Models
Two Example Problems
The Language Modeling Problem

Trigram Models:


利用的信息太少了。
A Naive Approach:

一个Smooth Model,加权考虑每个信息。很快就大到无法控制。
A Second Example: Part-of_Speech Tagging

那么问题来了,??该是什么?


同样的,有很多没有利用到的信息。
Features in Log-Linear Models
For Problem 1
The General Problem
- We have some input domain X
- Have a finite label set Y
- Aim is to provide a conditional probability for any x,y where
Language Modeling
- x is a “history” w1, w2, …, e.g.,
Third, the notion “grammatical in English” cannot be identified in any way with the notion “hign order of statistical approximation to English”. It is fair to assume that neither sentence (1) nor (2) (nor indeed any part of these sentences) has ever occurred in an English discourse. Hence, in any statistical - y is an “outcome”
Feature Vector Representations

Language Modeling


f1相当于unigram feature,f2相当于bigram feature,f3相当于trigram feature,f4相当于skip bigram feature。
Defining Features in Practice

Do not include trigrams not seen in training data.
Lead to:
Too many features;
Many not worth including in the model.
For Problem 2
The POS-Tagging Example

i: the position being tagged.
The Full Set of Features in Ratnaparkhi, 1996


The Final Result

绿色是x,红色是y。
Often sparse: relatively few 1’s than 0’s.
Definition of Log-linear Models
Parameter Vectors
前文介绍了feature,这里再引入parameter vector的概念。

两个vector点乘。
Language Modeling Example

p(model|x;v) = e^5.6 / (e^5.6 + e^1.5 + e^4.5 + e^-3.2 + …)
p(the|x;v) = e^-3.2 / (e^5.6 + e^1.5 + e^4.5 + e^-3.2 + …)
Log-Linear Models
总结定义:

经过这样处理后就满足条件p都大于0,且和为1了。
Why the name?
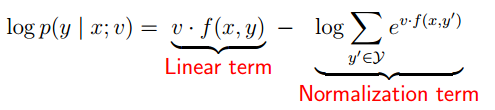
Parameter Estimation in Log-linear Models
求v。
Maximum-Likelihood Estimation

选让整个training example总值最大的。naive。
L(v)是一个倒吊钟形的函数,concave。比较容易优化,可以用gradient ascent。
Calculating the Maximum-Likelihood Estimates

Gradient Ascent Methods

Conjugate Gradient Methods

一般情况下工具包已经实现此算法。
Smoothing/Regularization in Log-linear Models
Smoothing in Log-Linear Models

Regularization

Experiments with Regularization

Experiments with Gaussian Priors

Log-linear Models for Tagging(MEMMs)
Applications for log-linear models.
MEMMs : Maximum-entropy(熵) Markov Models
Recap: The Tagging Problem
有以下几种:
Part-of-Speech Tagging
Named Entity Recognition
Named Entity Extraction as Tagging
Our Goal

已经讲过的方法有:
Hidden Markov Models 和 Viterbi Algorithm。
Log-Linear Taggers
Independence Assumptions in Log-linear Taggers
Log-Linear Models for Tagging

How to model p(t[1:n]|w[1:n])?

例子:the dog barks **DNV
P(D N V|the dog barks) = P(D|the dog barks, * *) x P(N|the dog barks, * D) x P(V|the dog barks, D N)
Features in Log-Linear Taggers
Representation: Histories

Recap: Feature Vector Representations in Log-Linear Models

An Example


f2对于HMM来说很难。
The Full Set of Features in [(Ratnaparkhi, 96)]
Parameters in Log-linear Models
Recap: Log-Linear Models

Training the Log-Linear Model

The Viterbi Algorithm for Log-linear Taggers
The Viterbi Algorithm


A Recursive Definition

与HMM的区别只在q那里。
The Viterbi Algorithm with Backpointers

An Example Application
FAQ Segmentation: McCallum et. al
- McCallum et. al compared HMM and log-linear taggers on a FAQ Segmentation task
- Main point: in an HMM, modeling is difficult in this domain
从文本中自动tag哪些行是head、question、answer。
1 | <head>X-NNTP-POSTER: NewsHound v1.33 |
FAQ Segmentation: Line Features
1 | begins-with-number |
FAQ Segmentation: The Log-Linear Tagger
得到feature。
1 | “tag=question;prev=head;begins-with-number” |
FAQ Segmentation: An HMM Tagger
对于:
1 | <question>2.6) What configuration of serial cable should I use |
得到
- First solution
把一句话分成很多词。

i.e. have a language model for each tag - Second solution

FAQ Segmentation: Results
| Method | Precision | Recal |
|---|---|---|
| ME-Stateless(Maximum Entropy Stateless) | 0.038 | 0.362 |
| TokenHMM | 0.276 | 0.140 |
| FeatureHMM | 0.413 | 0.529 |
| MEMM | 0.867 | 0.681 |
- Precision and recall results are for recovering segments
- ME-stateless is a log-linear model that treats every sentence seperately (no dependence between adjacent tags)
- TokenHMM is an HMM with first solution we’ve just seen
- FeatureHMM is an HMM with second solution we’ve just seen
- MEMM is a log-linear trigram tagger (MEMM stands for “Maximum-Entropy Markov Model”)
Summary

Log-Linear Models for History-based Parsing
这个方法的应用范围更广。
Conditional History-based Models
Recap: Log-Linear Taggers

A General Approach: (Conditional) History-Based Models
- We’ve shown how to define p(t[1:n]|w[1:n]) where t[1:n] is a tag sequence.
- How do we define p(T|S) if T is a parse tree (or another structure)? (We use the notation S = w[1:n])

并不使用Markov Assumption,所以不能用动态规划。
Representing Trees as Decision Sequences(关于Step 1)
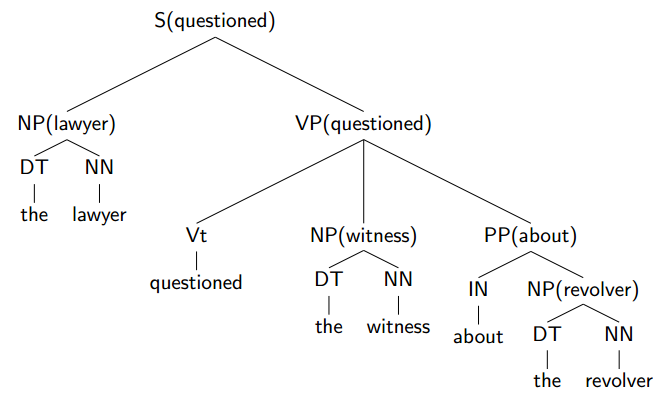
Ratnaparkhi’s Parser: Three Layers of Structure
- Part-of-speech tags
- Chunks
- Remaining structure
Layer 1: Part-of-Speech Tags

Layer 2: Chunks

QP: numeric phrases.

Layer 3: Remaining Structure

前两步之后到这里:
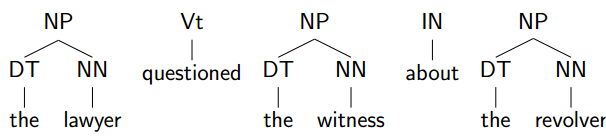
选择最左边的:
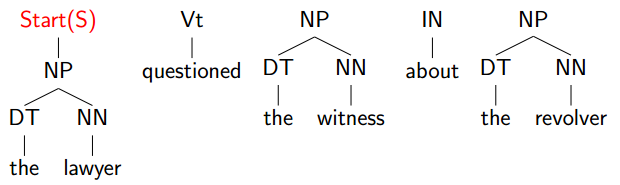
因为句子并没有结束,check为no:
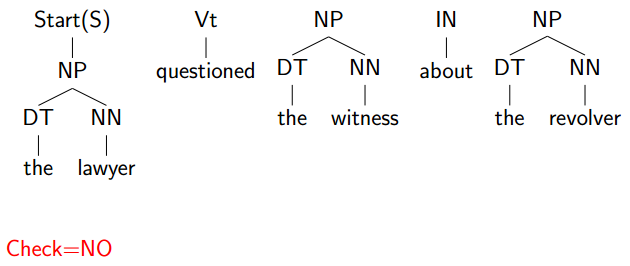
继续,省略数步:
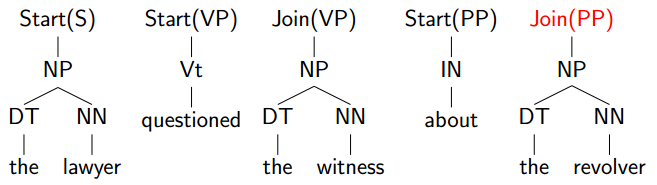
当前的constituent已结束,所以Check为yes:
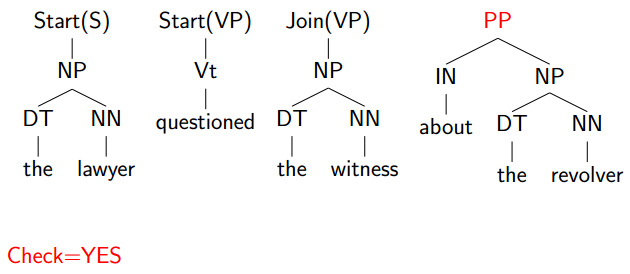
然后再选择最左边的没有Join或Start的项:
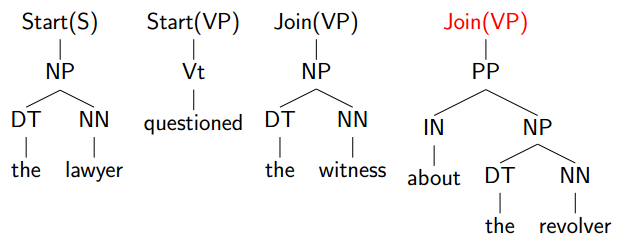
Check又选yes:
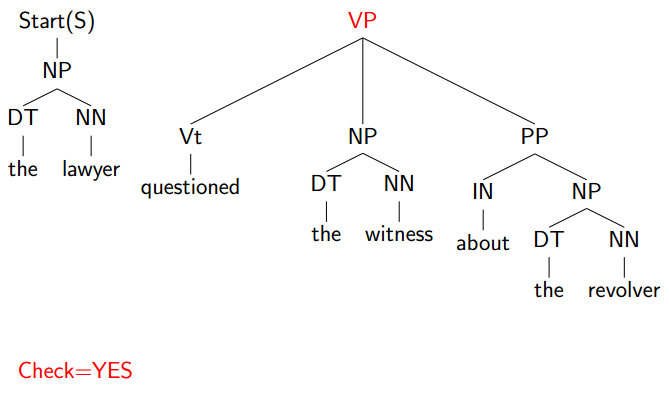
继续选择最左边:
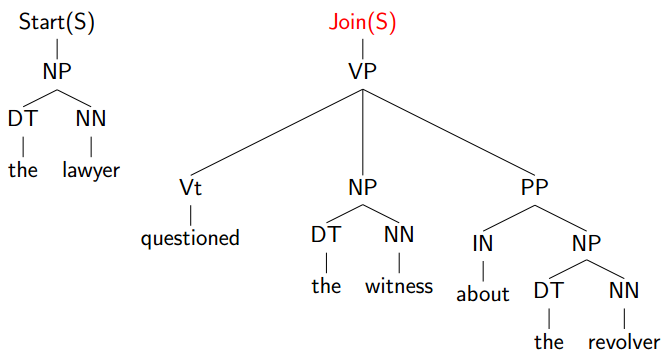
Check为yes:
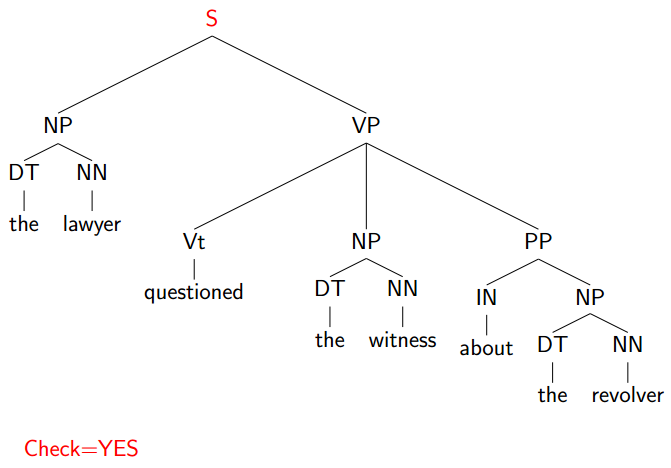
The Final Sequence of decisions

Features(关于Step 3)
Applying a Log-Linear Model


Layer 3: Join of Start
- Looks at head word, constituent (or POS) label, and start/join annotation of n’th tree relative to the decision, where n = −2, −1
- Looks at head word, constituent (or POS) label of n’th tree relative to the decision, where n = 0, 1, 2
- Looks at bigram features of the above for (-1,0) and (0,1)
- Looks at trigram features of the above for (-2,-1,0), (-1,0,1) and (0, 1, 2)
- The above features with all combinations of head words excluded
- Various punctuation features
Layer 3: Check=NO or Check=YES
- A variety of questions concerning the proposed constituent
Beam Search(关于Step 4)
The Search Problem

同理,不能用动态规划了。
得到很多可能的parse tree,每个有自己的概率。
Unsupervised Learning: Brown Clustering
本课讲的首个Unsupervised learning algorithm。
Word Cluster Representations
The Brown Clustering Algorithm
- Input: a (large) corpus of words
- Output 1: a partition of words into word clusters
- Output 2 (generalization of 1): a hierarchichal word clustering
Example Clusters (from Brown et al, 1992)
论文里给出的cluster结果,效果很好啊!
1 | Friday Monday Thursday Wednesday Tuesday Saturday Sunday weekends Sundays Saturdays |
A Sample Hierarchy (from Miller et al., NAACL 2004)
论文给出的Hierarchy结果。
哈夫曼树,左1右0。可以表示Hierarchy。
1 | lawyer 1000001101000 |
The Brown Clustering Algorithm
The Intuition
- Similar words appear in similar contexts
- More precisely: siilar words have similar distributions of words to their imediate left and right
The Formulation

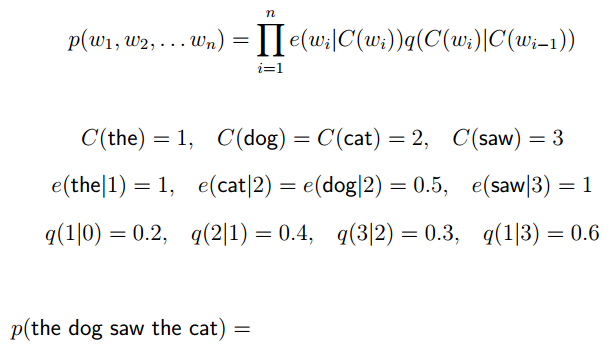
The Brown Clustering Model

Measuring the Quality of C

例如:
| 1 | 2 | 3 | 1 | 2 |
|---|---|---|---|---|
| the | dog | saw | the | cat |
n(1,2) = 2
n(2) = 2
A First Algorithm

A Second Algorithm

Clusters in NE Recognition
Miller et al, NAACL 2004
"Name Tagging with Word Clusters and Discriminative Training"
Scott Miller, Jethran Guinness, Alex Zamanian
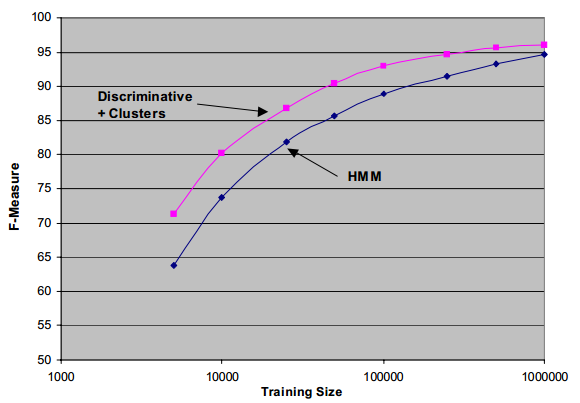
At a recent meeting, we presented name-tagging technology to a potential user. The technology had performed well in formal evaluations, had been applied successfully by several research groups, and required only annotated training examples to configure for new name classes. Nevertheless, it did not meet the user’s needs.
To achieve reasonable performance, the HMM-based technology we presented required roughly 150,000 words of annotated examples, and over a million words to achieve peak accuracy. Given a typical annotation rate of 5,000 words per hour, we estimated that setting up a name finder for a new problem would take four person days of annotation work – a period we considered reasonable. However, this user’s problems were too dynamic for that much setup time. To be useful, the system would have to be trainable in minutes or hours, not days or weeks.
可行的feature种类:
1 | 1. Tag + PrevTag |
结果评估:
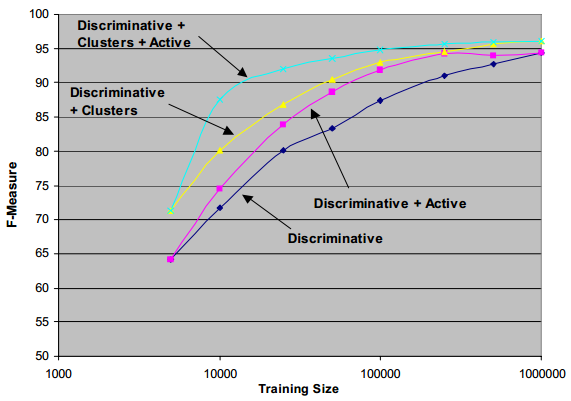
Active Learning -> Choose to label the most “useful” examples at each stage.
Global Linear Models(GLMs)
Techiniques
- So far:
Smoothed estimation
Probabilistic context-free grammars
Log-linear models
Hidden markov models
The EM Algorithm
History-based models - Today
Global linear models
A Brief Review of History-based Methods
Supervised Learning in Natural Language

The Models so far

第一个比如HMMs和PCFGs,第二个如Log-Linear Tagging。
Example 1: PCFGs

S
S->NP VP
q(S->NP VP) = p(S->NP VP|S)
Example 2: Log-linear Taggers

A New Set of Techniques: Global Linear Models
A New Framework: Global Linear Models
Intuition
- We’ll move away from history-based models
No idea of a “derivation”, or attaching probabilities to “decisions” - Instead, we’ll have feature vectors over entire structures “Global features”
“Global features” - First piece of motivation:
Freedom in defining features
A Need for Flexible Features


Three Components of Global Linear Models

例如,x是sentence,y是parse tree。candidates是一堆parse tree。
Component 1:
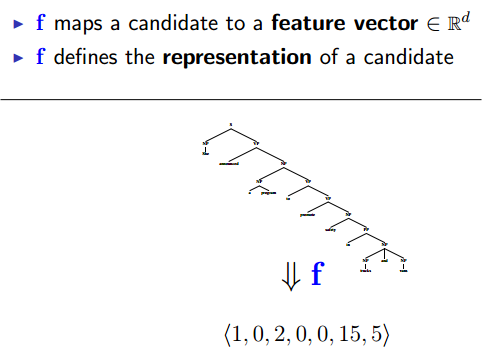
Features:
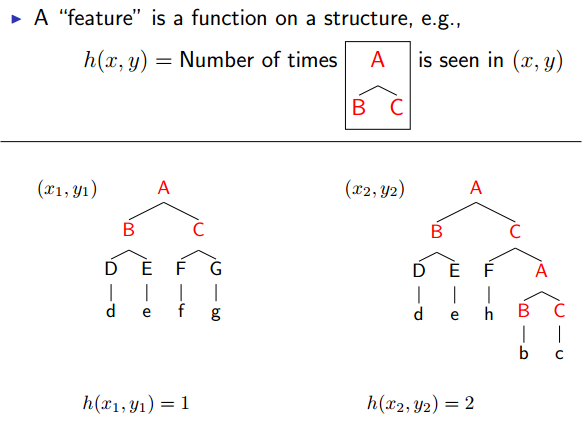
Feature Vectors:
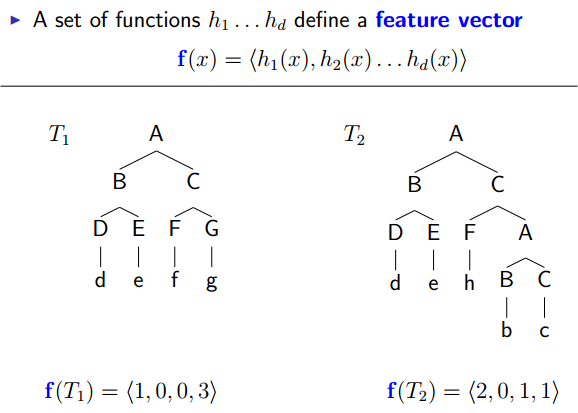
feature的设计很重要,将来要送进learning algorithm的。
Component 2:

- enumerates a set of candidates for an input x
- Some examples of how can be defined:
Parsing: is the set of parses for under a grammar
Any task: is the top N most probable parses under a history-based model
Tagging: is the set of all possible tag sequences with the same length as
Translation: is the set of all possible English translations for the French sentence
Component 3:
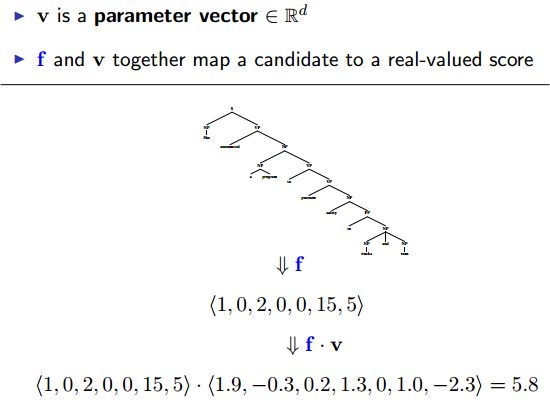
Putting is all Together

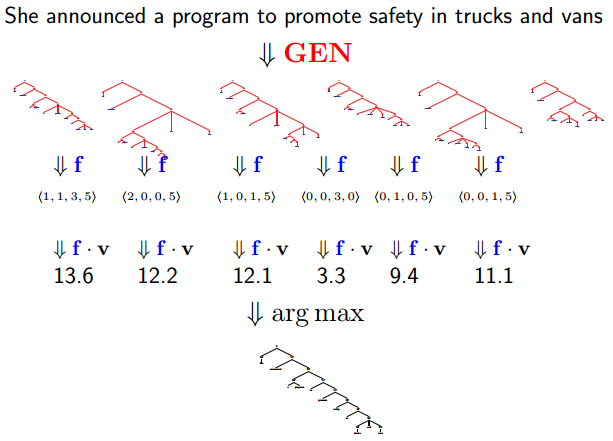
Parsing Problems in This Framework: Reranking Problems
Reranking Approaches to Parsing

baseline parser比如lexicalized PCFG。
The Representation

Some Features in the Paper:
From [Colins and Koo, 2005]:
The following types of features were included in the model. We will use the rule VP -> PP VBD NP NP SBAR with head VBD as an example. Note that the output of out baseline parser produces syntactic trees with headword annotations.
Rules These include all context-free rules in the tree, for example VP -> PP VBD NP NP SBAR
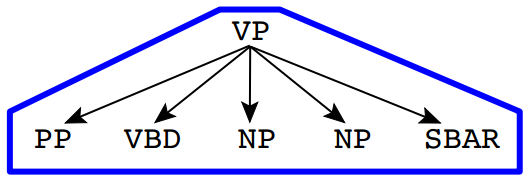
Bigrams These are adjacent pairs of non-terminals to the left and right of the head. As shown, the example rule would contribute the bigrams (Right, VP, NP, NP), (Right, VP, NP, SBAR), (Right, VP, SBAR, STOP), and (Left, VP, PP, STOP) to the left of the head.
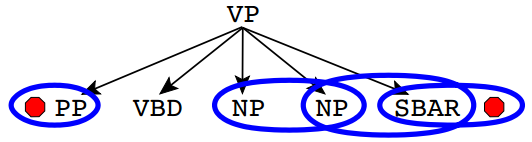
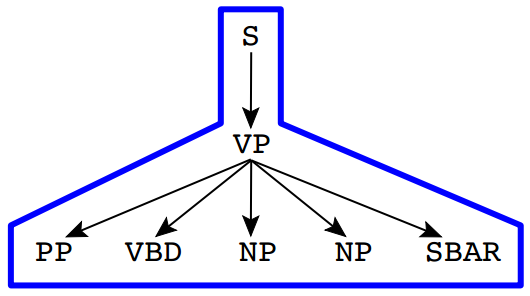
Grandparent Rules Same as Rules, but also including the non-terminal above the rule.
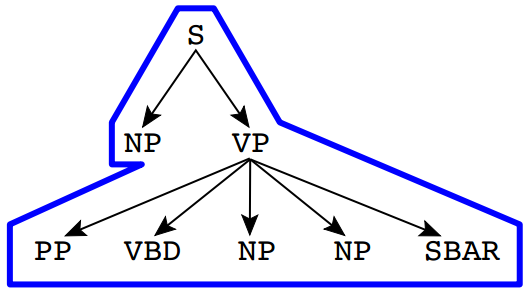
Two-level Rules Same as Rules, but also including the entire rule above the rule.
Parameter Estimation Method 1: A Variant of the Perceptron Algorithm
A Variant of the Perceptron Algorithm

T: number of iterations, small 5, 10, 20
Any features which are seen in the true candidate structure have their parameter value increased, whereas any features seen in the incorrectly proposed structure have their parameter values decreased. Kind of Reinforcing Step.
Perceptron Experiments: Parse Reranking
Parsing the Wall Street Journal Treebank
Training set = 40,000 sentences, test = 2,416 sentences
Generative model(Collins 1999): 88.2% F-measure
Reranked model: 89.5% F-measure(11% relative error reduction)
- Results from Charniak and Johnson, 2005
Improvement from 89.7% (baseline generative model) to 91.0% accuracy
Gains from improved n-best lists, better features, better baseline model
Summary
- A new framework: global linear models
GEN, f, v - There are several ways to train the parameters v:
Perceptron
Boosting
Log-linear models (maximum-likelihood) - Applications:
Parsing
Generation
Machine translation
Tagging problems
Speech recognition
GLMs for Tagging
Global Linear Models Part 2: The Perceptron Algorithm for Tagging
针对Tagging,我们之前已经学过HMMs和Log-Linear Taggers,现在学习第三种GLMs and Perceptron。
Tagging using Global Linear Models

例如:
n = 3
w = the dog barks
T = {D, N ,V}
GEN(the dog barks) = {DDD, DDN, DND, DNN, …} 共3^3 = 27个
f(the dog barks, D N V) = (1, 0, 0, 1)
Representation: Histories

Local Feature-Vector Representations

A tagged sentence with n words has n history/tag pairs.

global feature vector = the sum of local feature vectors
Global and Local Features

Putting it all Together

Recap: A Variant of the Perceptron Algorithm
Training a Tagger Using the Perceptron Algorithm

An Example

Experiments
- Wall Street Journal part-of-speech tagging data
Perceptron = 2.89% error, Log-linear tagger = 3.28% error - [Ramshaw and Marcus, 1995] NP chunking data
Perceptron = 93.63% accuracy, Log-linear tagger = 93.29% accuracy
GLMs for Dependency Parsing
Global Linear Models Part 3: The Perceptron Algorithm for Dependency Parsing
Dependency Parsing
Unlabeled Dependency Parses
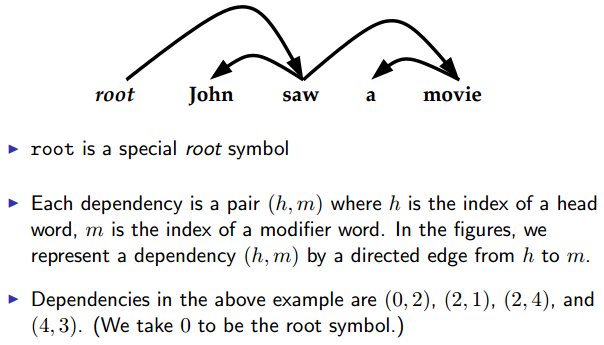
labeled就是标上每个arc代表的关系。
**All Dependency Parses for John saw Mary **
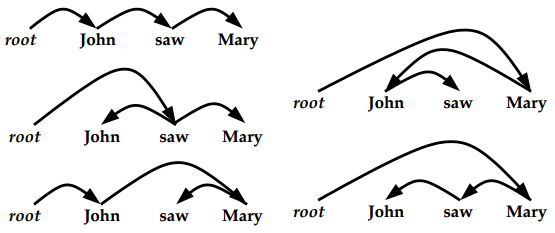
正确的是左列第二个。
Conditions on Dependency Structures
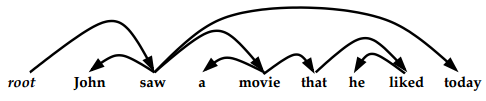
- The dependency arcs from a directed tree, with the root symbol at the root of the tree.
(Definition: A directed tree rooted at root is a tree, where for every word w other than the root, there is a directed path from root to w.) - There are no “crossing dependencies”.
Dependency structures with no crossing dependencies are sometimes referred to as projective structures.
没有环,也没有交叉。
有交叉的叫做Non-projective Structures,在本课中认为是不允许的。

Dependency Parsing Resources
- CoNLL 2006 conference had a “shared task” with dependency parsing of 12 languages (Arabic, Chinese, Czech, Danish, Dutch, German, Japanese, Portuguese, Slovene, Spanish, Swedish, Turkish). 19 different groups developed dependency parsing systems. (See also CoNLL 2007).
- PhD thesis on the topic: Ryan McDonald, Discriminative Training and Spanning Tree Algorithms for Dependency Parsing, University of Pennsylvania.
- For some languages, e.g., Czech, there are “dependency banks” available which contain training data in the form of sentences paired with dependency structures.
- For other languages, we can extract dependency structures from treebanks.
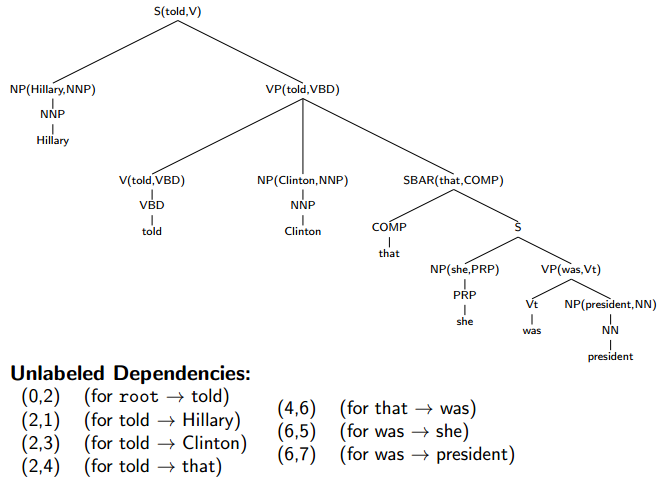
图上右下角的S应该是S(was,Vt)
head word一层层往下找,这个过程就是之前讲过的lexicalization。
Efficiency of Dependency Parsing
- PCFG parsing is where n is the length of the sentence, G is the number of non-terminals in the grammar.
- Lexicalized PCFG parsing is where n is the length of the sentence, G is the number of non-terminals in the grammar.
- Unlabeled dependency parsing is .因为用了dynamic programming,看Jason Eisner的paper。
very efficient at parsing, very useful representations.
GLMs for Dependency Parsing
GLMs for Dependency parsing

size of GEN is exponentional in n.

x是句子,y是一种Dependency结构。
Definition of Local Feature Vectors

例子:针对前文的John saw a movie,可以 有如下feature。
g1(x,h,m) = 1 if xh=saw, and xm=movie; 0 otherwise
g2(x,h,m) = 1 if POS(h)=VBD, and POS(m)=NN; 0 otherwise
g3(x,h,m) = 1 if |h-m|>10; 0 otherwise
Results from McDonald(2005)
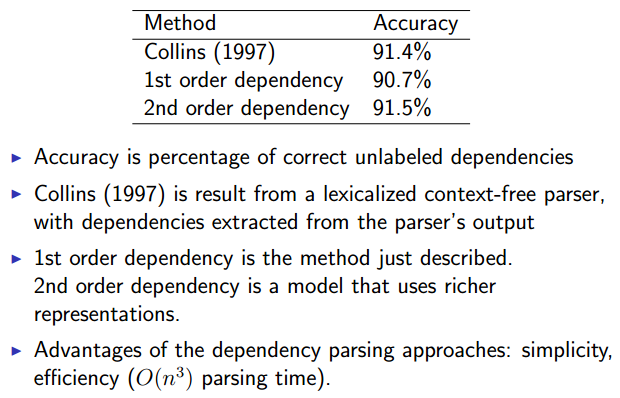
G = Num of non-terminals
Extensions
- 2nd-order dependency parsing, 3rd-order dependency parsing
不再只孤立看一个dependency arc。能得到93-94% accuracy。 - Non-projective dependency structures
spanning tree algorithms
Summary

(「・ω・)「
春假前一天顺利完成!