An Introduction to Software Architecture 笔记
"An Introduction to Software Architecture"是David Garlan和Mary Shaw于1994年发表的一篇论文。
论文介绍了软件架构设计中的常见风格与组合方式,并举出6个实例来具体分析。
Common Architectural Styles
常见风格及其利弊。
本论文将系统视为许多模块(Component)、他们之间的交互关系(Connector),以及一些前提约束(Constraint)。
可以使用这些问题来分析一个风格:
- 结构(Component、Connector、Constraint)?
- 背后的计算模型?
- 重要的不变量?
- 常见应用?
- 优缺点?
- 常见变种?
Pipes and Filters

结构:
本风格中每个component都有一系列输入和输出。一个component接受一系列输入数据,处理后产生一系列输出数据,按照一定的顺序传给下一个component。于是component称为filter,connector称为pipe。
重要不变量:
filter们必须是单独的实体,不能和其他filter共享状态。filter可以限制上游或下游filter应具备哪些属性,但不能明确限制filter的身份。系统最终输出的正确性不能依赖于filter的顺序,虽然其也要经过一定的规划。
常见变种:
Pipeline:限制拓扑结构为线性序列。
Bounded pipe:限制pipe上可以存留的数据量。
Typed pipe:限制两个filter间传递的数据必须是某种数据结构。
还有一种退化的pipeline,每次只接收一个单个的输入实体,只是一个流水线处理程序。
常见应用:
Unix shell。传统编译器。
优点:
全局的系统输入输出行为可被视为独立filter行为的组合。
允许复用。可以拼接任意两个filter,只要他们的输入输出数据能够匹配。
系统容易维护与扩展。新filter很容易添加,老filter也很容易被改进版本替代。
支持一些系统分析,比如流量分析、死锁分析。
显然利于实现并行处理。每一个filter可以实现为一个单独的task,然后与其他filter并行处理。
缺点:
需要为每一个filter考虑完整的输入数据到输出数据的转化过程,不适用于交互程序。
可能需要维护两个单独却相关的数据流,比较麻烦。
传输数据可能需要一个共同的底层结构,于是每个filter处理时需要额外解析和反解析其数据。会影响性能并增加复杂度。
Data Abstraction and Object-Oriented Organization
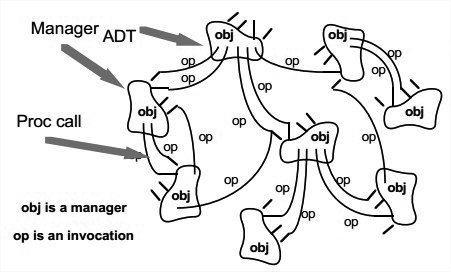
结构:
数据属性及其操作被封装在抽象数据类型里。component是对象即类的实例,对象与对象之间通过函数和过程调用交互。
每一个对象要保持自己的意义与实现完整性。
每一个对象的内部实现对其他对象来说是不可见的。
常见变种:
对象是可并行的task。或对象有多个接口。
优点:
对象可以对客户隐藏自己的内部实现。修改内部实现不会影响客户。
可以将问题分解成多个交互的角色。
缺点:
为了让两个对象交互,他们必须知道对方的身份。于是修改一个对象的话,所有调用其函数的对象都要做相应修改。如果B和C都对同一个对象A做修改,可能会有一些预料遇到的副作用。
Event-based, Implicit Invocation
结构:
不再使用显式调用,而是发送或广播一个event。其他component可以注册一个函数为event的接收函数。当event被发送时,相关component的对应函数即被调用。
常见应用:
编辑器和变量监视器接收调试器的breakpoint事件。调试器在断点出发送一个事件,这些工具接收并显示对应信息。
在数据库中保证一致性约束。
在用户界面中将数据显示与数据管理分开。
在syntax-directed editor中支持渐进语法检查。
重要不变量:
发送事件的component不知道哪些component会被这个时间影响。所以这些component的处理顺序也是不可控的。
优点:
易复用。一个component只要注册一下就可加入系统。
更换component不会影响其他component的接口。
缺点:
component放弃了对系统执行的控制。当一个component发送一个事件时,它不知道其他component会怎么反应。也不知道会以什么样的顺序反应。也不知道它们什么时候反应结束。
数据交换也可能成为问题。有时候数据可以保存在发送的事件里,有时候component们需要共享一个数据仓库来交换数据。这种时候资源管理可能比较成问题。
结果的正确性也难以保证,因为一个事件发送后执行的结果和当时程序环境上下文相关。
Layered Systems
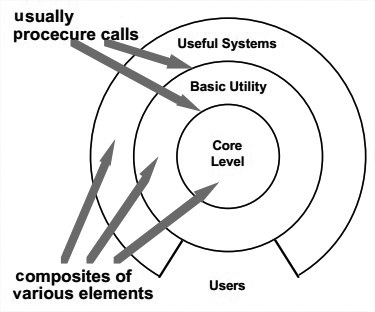
结构:
这种结构有层级之分。每一层为上层提供服务,又是下层的客户。有些这类系统中,内部层级只有相邻外层层级才知道,除了某些刻意设计过的外部接口。他们之间的connector是定义层级之间如何交互的协议。
常见应用:
layered communication protocols。还有数据库和操作系统。
优点:
支持逐层抽象。可以把一个复杂的问题分解为连续的几步。
支持扩展。每一层的更改只影响相邻两层而已。
支持复用。不同实现的同一层换起来很方便,只要有相同的接口。
缺点:
系统很难表示为逐层的,即便逻辑上可以视为逐层,基于性能的考虑,最高层与最底层之间也许也需要密切的交互。
将各层抽象得很恰当不容易。有些功能可能跨越几层。
Repositories
结构:
有两种很不一样的component:一个中央数据结构表示当前状态,一些独立的component基于这个中央存储运行。
独立component和中央存储之间的交互方式有很多可能:
如果一组输入数据的类型决定了哪些操作会被调用,这是传统数据库。
如果中央存储的当前状态决定哪些操作被调用,这是blackboard。
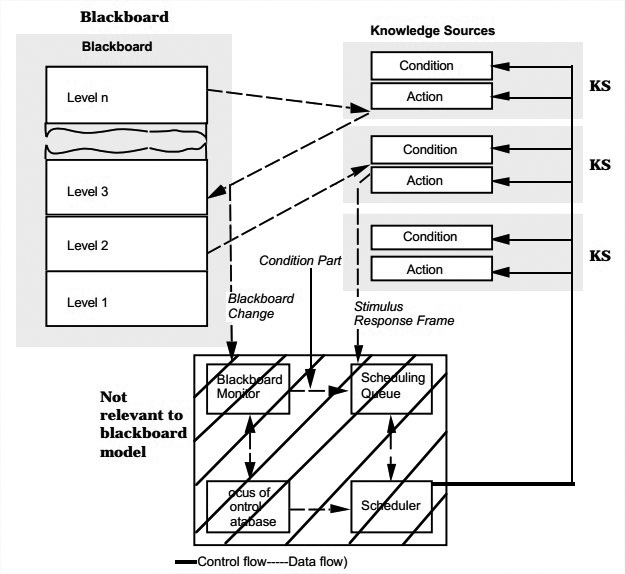
Blackboard
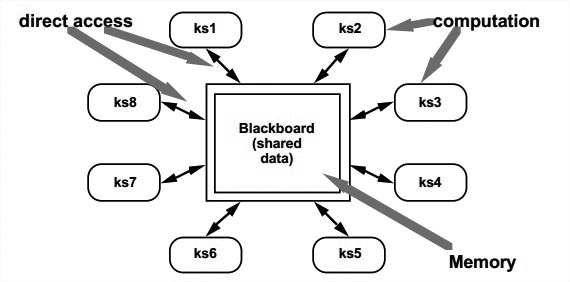
结构:
分成三部分:
The knowledge sources: 独立、分散的,与应用相关的知识包。对知识包的交互只能通过blackboard。
The blackboard data structure: 目前问题解决状态的数据,按照应用分成层级结构。知识源对blackboard做出修改,直到问题的答案被渐进地解决出来。
Control: 完全由blackboard的状态驱动。blackboard中的变化让一些知识源可以运行时,他们会寻机响应。
图中没有明确展示Control部分。blackboard中的状态变化会触发知识源的调用。实际的控制可以写在知识源、blackboard、单独模块,或者所有这些之中。
常见应用:
用在需要复杂的信号处理和解释的应用中,比如语音与模式识别。
关系不密切的agent需要共享数据时。
Table Driven Interpreters
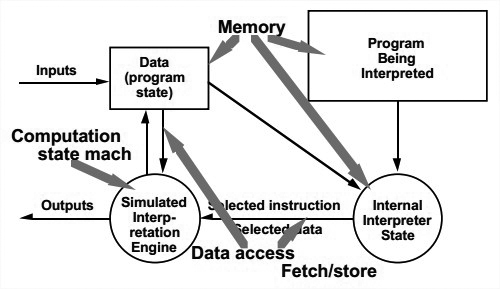
结构:
Interpreter里包含pseudo-program和interpretation engine。伪代码程序里包含程序自己还有解释器所对其执行状态的模拟。解释器引擎包含解释器的定义和其执行状态。
所以一个interpreter一般包括4个component: an interpretation engine to do the work, a memory that contains the pseudo-code to be interpreted, a representation of the control state of the interpretation engine, and a representation of the current state of the program being simulated.
常见应用:
虚拟机,用来兼容硬件引擎和代码所期待的引擎。
Other Familiar Architectures
Distributed processes
以拓扑结构知名,如ring and star organizations。
以进程间通信协议知名,如heartbeat algorithms。
一个常见的结构是client-server结构。一个server为其他process(client)提供服务。server事先不知道client都是谁,client知道server是谁并且远程发送请求。
Main program/subroutine organizations
结构与采用语言相关。一般是模块化,或者就是一个main控制几个subroutine。
Domain-specific software architectures
有利于自动或半自动生成架构。
State transition systems
很多交互系统采用这种结构,state和transition。
Process control systems
要和物理世界交互的程序通常采用。基本上是一个反馈循环,从sensor来的输入处理过之后产生输出,对环境产生一些影响。
Heterogeneous Architectures
组合多种风格的混合结构。组合风格的方式有种:
- 通过层级。一个风格里的某个component内部有另一种不同风格的结构,比如Unix pipeline里单独component可以是任何风格。甚至connector也可以用层级方式处理,比如一个pipe connector内部可以用FIFO的queue实现。
- 允许一个component使用混合风格的connector。比如,一个component可能通过接口获取一个repository的数据,但是和其他component的交互用pipe完成,接收控制消息又用另外一些接口。再比如active database,该repository通过消息等隐式调用激活外部component,外部component是与数据库中的某部分注册关联好的。(Blackboards are often constructed this way; knowledge sources are associated with specific kinds of data, and are activated whenever that kind of data is modified.)
- 绞尽脑汁精心实现组合。
Case Studies
第一个:展示对同一个问题采用不同的风格各有什么利弊。
第二个:总结设计domain-specific风格的经验。
第三个:用新眼光看编译器架构。
剩下三个:展示混合结构。
Case 1: Key Word in Context
使用案例:KWIC system
“The KWIC [Key Word in Context] index system accepts an ordered set of lines, each line is an ordered set of words, and each word is an ordered set of characters. Any line may be ‘circularly shifted’ by repeatedly removing the first word and appending it at the end of the line. The KWIC index system outputs a listing of all circular shifts of all lines in alphabetical order.”
常被用来展示对问题的分解方式不同会导致它们适应软件设计变化的能力不同。
一个软件的设计可以有这些可变部分:
- Changes in processing algorithm: 比如,行旋转可以发生在从输入设备读入每行时,所有行都读完时,字母排序需要新的旋转行时。
- Changes in data representation: 比如,行可以有很多种保存方式。旋转也可以存结果或是(序列、平移)对。
- Enhancement to system function: 比如,旋转行来移除以a/an/and等词开始的行。添加交互功能,让用户来删除行。
- Performance: 时间和空间复杂度更改。
- Reuse: 每个component的可复用性如何。
Solution 1: Main Program/Subroutine with Shared Data
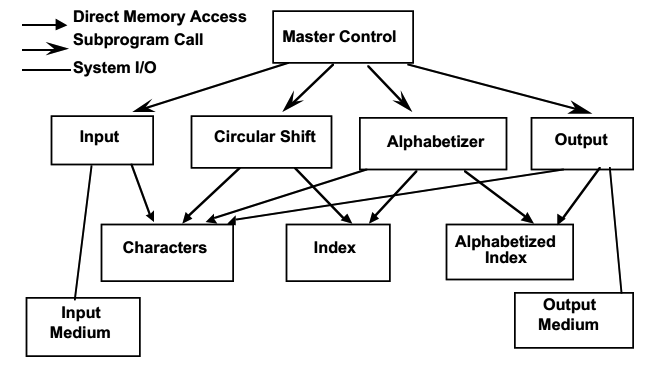
这种分解方式基于4个基本功能:input, shift, alphabetize, output。
由一个main函数按顺序循环执行这几个子功能。数据通过shared storage在component之间传输。component和shared storage之间通信基于不受限制的读写协议,因为程序执行时保证依次读写数据。
优点:用这种结构,数据被有效利用,因为所有操作都共享同一份存储数据。而且这种结构设计很符合直觉,不同的操作被分为不同的模块。
缺点:难以应付软件设计变化。尤其是数据存储格式的更改会影响所有模块。修改主函数功能和扩展系统都不容易。分散的模块设计也不利于复用。
Solution 2: Abstract Data Types
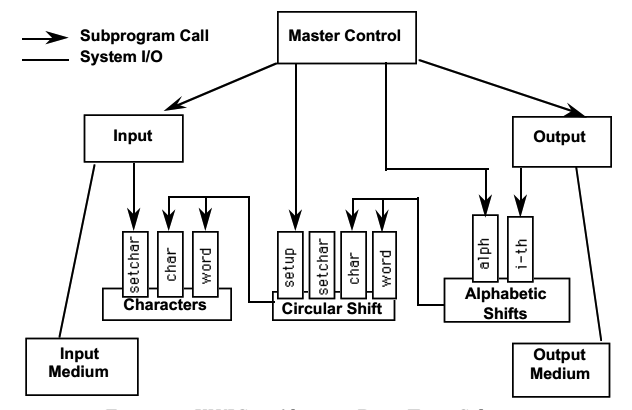
这个方案将系统分解为5部分。不过这里面的数据已经不是被计算component所直接共享的了,而是只能通过模块的接口来访问。逻辑的处理方式还是一样。
优点:和第1个方案相比,比较容易应对软件设计变化。算法和数据结构都可以在单一模块中修改,不会影响其他模块。可复用性也得到提高,因为模块项目之间交互时很少猜测,都用明确的接口。
缺点:仍然不利于扩展。如果要向系统添加新功能,要么修改现有模块使其变复杂,要么添加新的模块造成性能损失。
Solution 3: Implicit Invocation
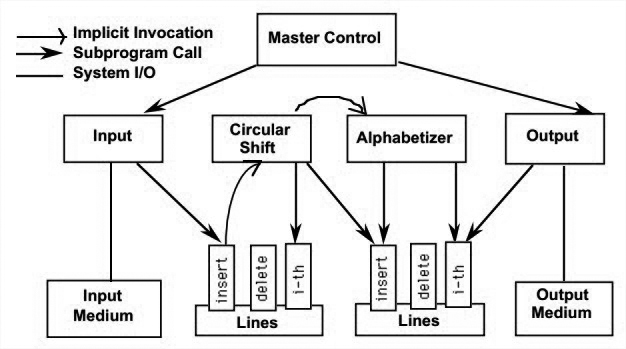
这个方案使用和方案1一样的共享数据,但是有两个重要不同:数据的接口更加抽象。计算是当数据修改时被隐形调用的,比如,向line storage添加新line会向shift模块发送事件,shift模块会生成circular shift,其又隐式调用alphabetizer去为line排序。
优点:利于扩展。新模块添加时只要注册为监听数据修改事件即可。由于数据读写是抽象的,数据结构的内部变化不会影响外界读写。可复用性提高,因为能被隐式调用的模块只依赖于一些外部触发事件。
缺点:难以控制被隐式调用的模块的执行顺序。由于调用是数据驱动的,实现时可能会用更多空间。
Solution 4: Pipes and Filters
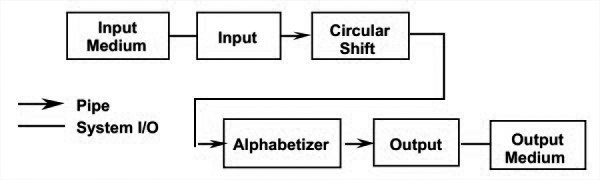
这个方案使用pipeline,有4个filter:input, shift, alphabetize, output。每个filter处理完数据后发给下一个filter。control是分布在每一个filter上的。数据在filter之间只通过pipe共享。
优点:保持了直觉上的数据流动。支持复用和修改,每个filter都是独立的。新功能很容易添加。
缺点:不可能支持互动。空间利用率不高,因为每个filter都需要拷贝其所有数据到下一filter。
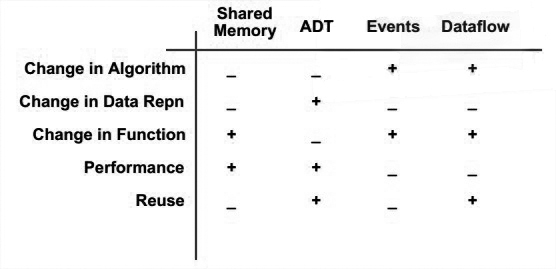
Comparisons
Case 2: Instrumentation Software
目标是为示波器设计一个可重用性强且性能好的系统。
An object-oriented model
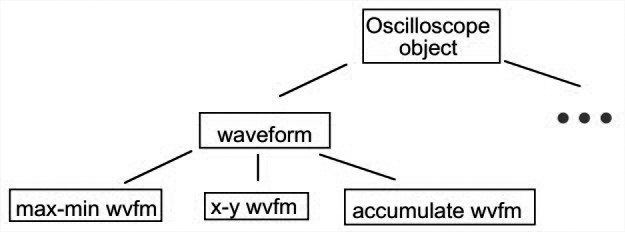
界定示波器中的数据类型:waveforms, signals, measurements, trigger modes, etc.
功能如何划分不明确。比如,测量应该和所测量的数据关联,还是单独表示?用户界面应该和哪个对象交互?
An layered model
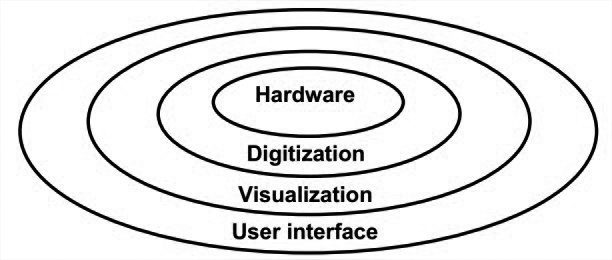
Hardware层过滤发给示波器的信号。Digitization层将信号数字化并存储,以及对waveform进行操作,包括测量、增益、傅里叶变换等。Visualization层将数字化的waveform和测量显示出来。User interface层用于用户交互并确定显示哪些内容。
层次的划分很符合直觉,可惜不适用于此应用领域。因为每层之间的硬性划分不符合众多功能之间所需的密切交互。
A Pipe and Filter Model
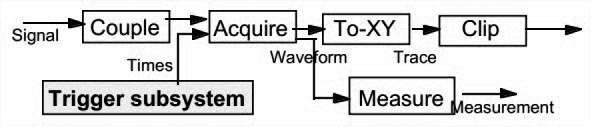
Signal转换器处理外部信号。Acquisition转换器从这些信号生成数字waveform。Display转换器把这些waveform转换为显示数据。
该结构并没像layered结构一样将功能硬性划分为独立区间,signal数据也可以直接传入display转换器。且该模型的设计比较符合工程师的数据流分析。
缺点是用户如何交互并不清晰。
A Modified Pipe and Filter Model
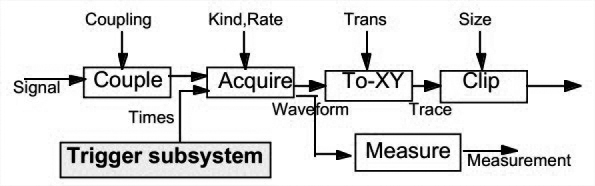
为每个filter添加一个control接口,从而可以从外部控制filter,解决用户输入问题。
Further Specialization
前一个设计仍然有些问题,其中一个就是Pipe and Filter风格的性能比较差;另一个就是每个filter运行的速度很不一样,因为一个处理数据慢大家就都等它不太好。
解决这些问题需要更加“特化”。定义很多种不同类型的pipe,其中一些允许数据传递时不用复制,另外一些允许数据处理中不接受其他数据。
Case 3: A Fresh View of Compilers
技术的进步也会影响系统的设计,从编译器就可以看出这点。
在19世纪70年代,编译被看做一个序列化的进程,其结构如下图。文本从左端开始依次转化 - lexical token stream, parse tree, intermediate code - 直到变成机器码出现在右端。

事实上很多编译器还会有一个变量表独立存在。
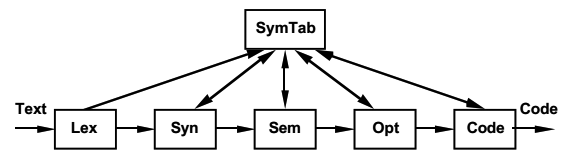
19世纪80年代中期,出现了中间表示,它在编译初期生成,在接下来的步骤中持续修改。
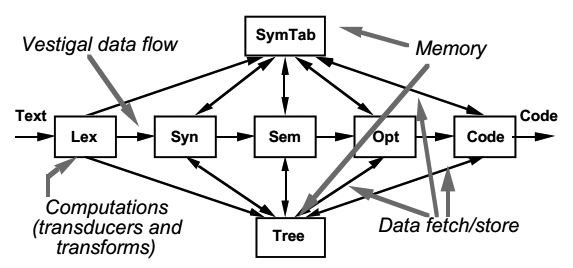
如果将关注的重点从顺序执行的过程转移到共享数据的表示,这个架构可以重绘为下图。很多工具是针对这个中间数据开发的,比如syntax-directed editor和很多分析工具。
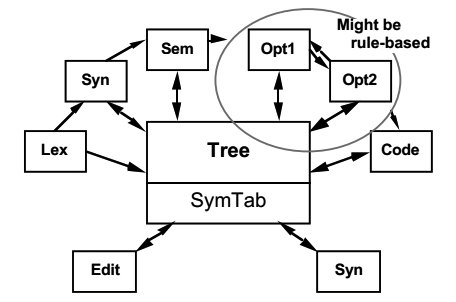
这个结构和blackboard有一些相像之处,比如计算所需的数据存在中央存储,并且只通过共享数据与其他运算模块交互。也有不同之处,blackboard中操作执行的顺序是数据修改发生的顺序所决定的,而编译器执行的顺序是事先确定的。
Case 4: A Layered Design with Different Styles for the Layers
对化工生产过程进行分布式过程控制的系统,PROVOX。
从简单的压力流量循环控制到复杂的交叠循环策略控制都有。系统通过一个5层的层级架构实现了过程控制与设备管理的整合。
下图体现了这个架构,右侧是软件视角,左侧是硬件视角。
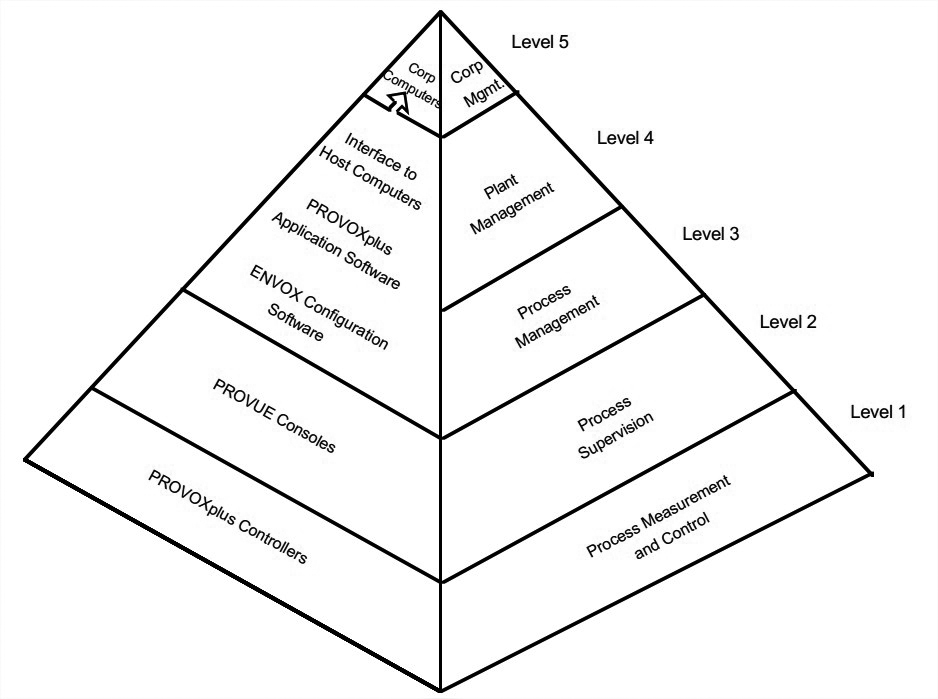
- Level 1: Process measurement and control: direct adjustment of final control elements.
- Level 2: Process supervision: operations console for monitoring and controlling Level 1.
- Level 3: Process management: computer-based plant automation, including management reports, optimization strategies, and guidance to operations console.
- Level 4 and 5: PLant and corporate management: higher-level functions such as cost accounting, inventory control, and order processing/scheduling.
其中,Level 1-3是object-oriented,Level 4-5是传统的data-processing repository。
对于Level 2所需的控制与监控功能,PROVOX使用了一系列的point,类似一个object。下图是point的规范形式。
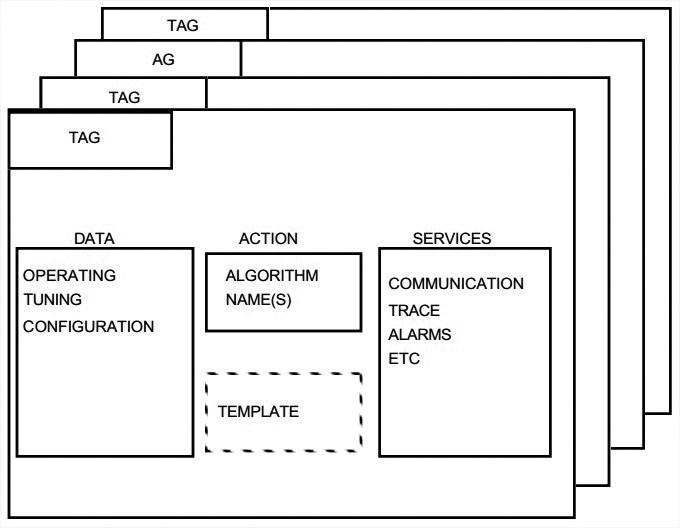
Case 5: An Interpreter Using Different Idioms for the Componnets
专家系统常用一系列situation-action规则的方式构建。Hayes-Roth就是一个这样的基于规则的系统。
最基础的rule-based系统,类似一个table-driven interpreter。
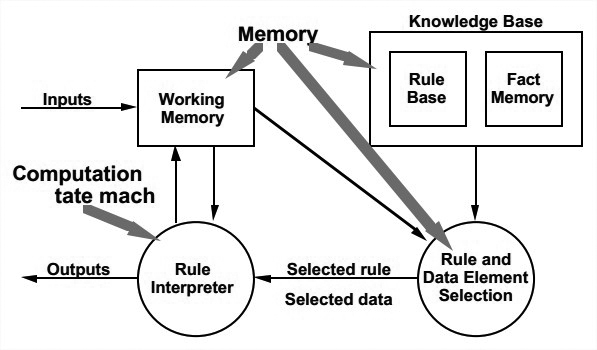
- The pseudo-code to be executed, in this case the knowledge base.
- The interpretation engine, in this case the rule interpreter, the heart of the inference engine.
- The control state of the interpretation engine, in this case the rule and data element selector.
- The current state of the program running on the virtual machine, in this case the working memory.
Rule-based系统常用pattern matching和context(currently relevant rules)。把这些也添加进去,再标记出模块。
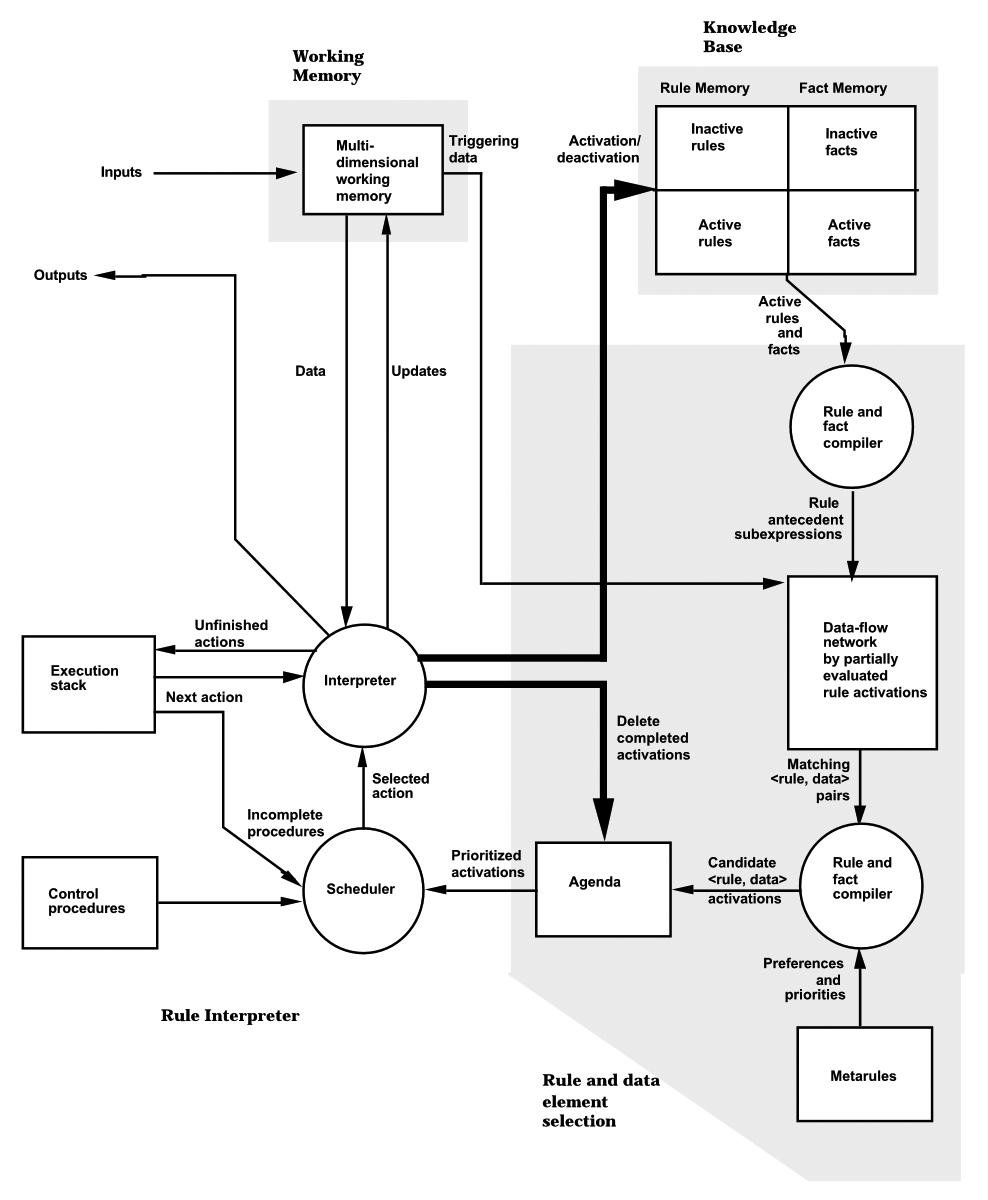
除了两条黑线(Interpreter控制激活),其余部分结构和简单模型一样。
- Knowledge base仍然是一个相对简单的存储结构,有一些区分活跃和非活跃内容的子结构。
- Rule interpreter内部使用table-driven interpreter扩展了一下,而control procedure起的是pseudo-code作用,execution stack起的是current program state的作用。
- Rule and data element selection主要使用pipeline实现的,逐步通过激活的规则和事实得出下一步激活的规则。在这个pipeline中,第3个filter(nominator)也是一个固定的原规则数据库。
- Working memory没有进一步扩展。
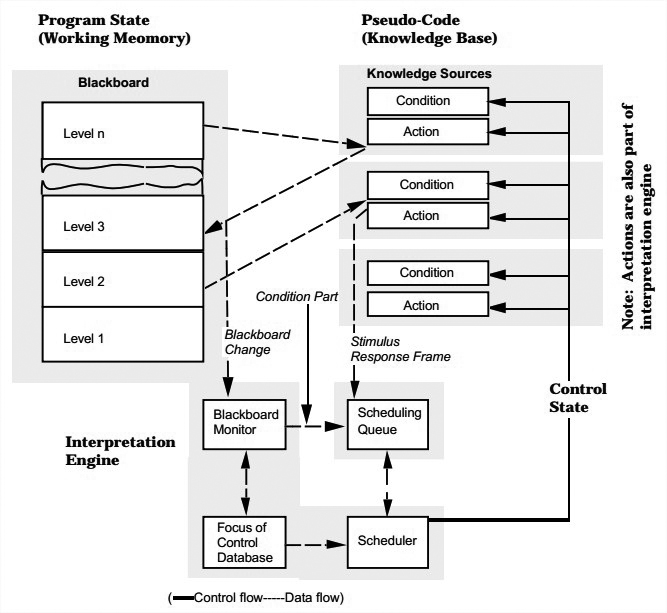
Case 6: A Blackboard Globally Recast as Interpreter
最基础的blackboard结构,标明了其最主要的3个部分:knowledge sources, the blackboard data structure, control。这就是前面那张图。
HEARSAY-II语音识别系统是一个大型blackboard结构的系统,它的结构如下图。
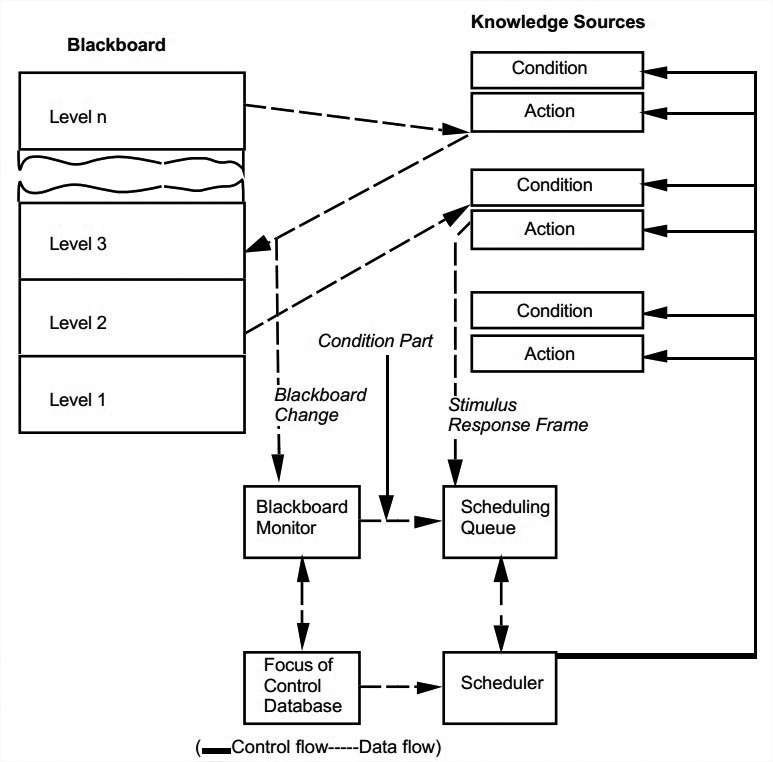
Blackboard被分成6到8层层级,每一层都对下层数据进行进一步抽象,其元素是对输入语言解析方式的假说。
Knowledge source的设计也要适应这些任务,比如segmenting the raw signal, identifying phonemes, generating word candidates, hypothesizing syntactic segments, proposing semantic interpretations。每一个knowledge source都包括一个用于确定其何时可用的condition部分,和一个处理对应旧blackboard元素并生成新的的action部分。
Control被实现为blackboard monitor和scheduler。scheduler监视blackboard,并且为请求knowledge source的各个blackboard元素计算优先级。
这个模型在设计时是blackboard模型,实现时用到了interpreter模型。并不是说其中一个component用到了interpreter,而是可以从两种角度来看。