《C陷阱与缺陷》笔记
同事言讲,自从他学习了《C陷阱与缺陷》和《C专家编程》后,写比较底层一点的程序就很少出错了。我听后甚是羡慕,慕名学习。
这本书主要讲解C语言使用中可能遇到的坑,包括很多语法细节,不过有些内容已经过时。
词法陷阱
程序会被词法分析器分解成各个符号。探讨符号和组成符号的字符间的关系,以及有关符号含义的一些常见误解。
=不同于==。分别是赋值运算符和比较运算符。&和|不同于&&和||。分别是按位运算符和逻辑运算符。- 词法分析中的贪心法则。C语言中某些符号如
/、*、=只有一个字符长,称为单字符符号。其他符号如/*和==和标识符包括多个字符,称为多字符符号。当C编译器读入一个字符/后又跟了一个字符*,编译器就需要作出判断:是将其作为两个分别的符号对待,还是合起来作为一个符号对待。C语言的解决方案是:贪心规则,即每一个符号应该包含尽可能多的字符。
注意除了字符串与字符常量,符号的中间不能嵌有空白(空格符、制表符和换行符)。
例如:y = x/*p是错误的,应写为y = x / *p或者y = x/(*p)。 - 整型常量。如果一个整型常量的第一个字符是数字0,那么该常量会被视为八进制数。
- 字符与字符串。C语言中的单引号与双引号含义迥异。
用单引号引起的一个字符实际上代表一个整数,整数值对应于该字符在编译器采用的字符集中的序列值,如'a'的含义与0141(八进制)或者97(十进制)严格一致。
用双引号引起的字符串,代表的是一个指向无名数组起始字符的指针,该数组被双引号之间的字符以及一个额外的二进制值为零的字符'\0'初始化。
例如:printf("Hello world\n");与char hello[] = {'H','e','l','l','o',' ','w','o','r','l','d','\n',0}; printf(hello);是等效的。
题目
- 问:写一个测试程序。要求:无论是对允许嵌套注释的编译器,还是对不允许嵌套注释的编译器,该程序都能正常通过编译,但是这两种情况下程序执行的结果却不相同。
答:/*/*/0*/**/1。如果允许嵌套注释,上式解释为:/* /* /0 */ * */ 1,结果为1;如果不允许嵌套注释,上式解释为/* / */ 0 * /**/ 1,结果为0*1,即0。 - 问:
a+++++b的含义是什么?
答:上式唯一有意义的解析方式是:a ++ + ++b。但是根据贪婪规则,上式会被分解为:a ++ ++ + b,等价于((a++)++) + b,,由于a++结果不能作为左值,语法上不正确。
语法陷阱
一些用法和意义与我们想当然的认识不一致的语法结构。
- 理解函数声明。任何C变量的声明都由两部分组成:类型以及一组类似表达式的声明符declarator。
例如:
float *g(), (*h)();表示*g()与(*h)()是浮点表达式。因为()结合优先级高于*,*g()也就是*(g()),g是一个函数,该函数的返回值类型为指向浮点数的指针。同理得出h是一个函数指针,h所指向函数的返回值为浮点类型。
float (*h)();表示h是一个指向返回值为浮点类型的函数的指针,因此(float (*)())表示一个“指向返回值为浮点类型的函数的指针”的类型转换符。
调用首地址为0位置的子例程:(*(void(*)())0)();。一般用typedef来优化可读性,例如typedef void (*funcptr)(); (*(funcptr)0)();。
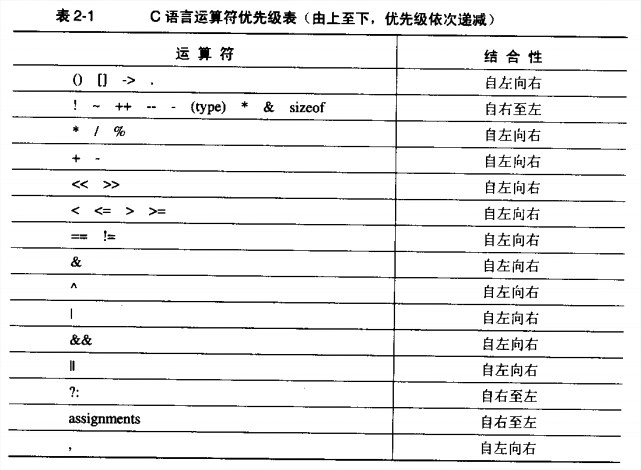
void (*signal(int, void(*)(int)))(int);可以表示为typedef void (*HANDLER)(int); HANDLER signal(int, HANDLER);。 - 运算符的优先级问题。分组记忆。
优先级最高的并不是真正意义上的运算符,包括数组下标、函数调用操作符各结构成员选择操作符,都是从左到右结合。
之后是单目运算符,是从右到左结合。因此*p++被编译器解释成*(p++)即取指针p所指向的对象,然后将p递增1,而不是(*p)++即取指针p所指向的对象,然后将该对象递增1。
其次是双目运算符。双目运算符中,算术运算符的优先级最高,移位运算符次之,关系运算符再次之,接着是逻辑运算符、赋值运算符、三目运算符。记住两点:1.任何一个逻辑运算符的优先级低于任何一个关系运算符。2.移位运算符的优先级比算术运算符要低,但是比关系运算符要高。
最后是逗号运算符。
- 注意作为语句结束标志的分号。不要不小心写在if或while语句等之后需要紧跟另一条语句的语句后。return语句后遗漏分号也麻烦。当一个声明的结尾紧跟一个函数定义时,如果声明结尾的分号被忽略,编译器可能会将声明的类型视作函数的返回值类型。
- switch语句。不要忘写break。故意不写break的地方最好写上注释说明。
- 函数调用。要有参数列表()。
- 悬挂else引发的问题。if的内容要放在{}里。
语义陷阱
可能的语义误解。程序员本意是希望表示某物,而实际表示的是另外一种事物。
- 指针与数组。C语言中的数组值得注意的地方有以下两点。
1.C语言中只有一维数组,而且数组的大小必须在编译期就作为一个常数确定下来。C语言中数组的元素可以是任何类型的对象,也可以是其他数组。这样就可以仿真出一个多维数组。
2.对于一个数组,只能做两件事:确定该数组的大小,以及获得指向该数组下标为0的元素的指针。其他有关数组的操作,实际上都是通过指针进行的。
例如:int calendar[12][31];声明了calendar是一个数组,该数组拥有12个数组类型的元素,其中每个元素都是一个拥有31个整形元素的数组。
sizeof(calendar)的值是372(31x12)与sizeof(int)的乘积。
如果calendar不是用于sizeof的操作数,而是用于其他的场合,那么calendar总是被转换成一个指向calendar数组的起始元素的指针。
calendar[4]表示calendar数组的第5个元素,是calendar数组中12个有着31个整型元素的数组之一。sizeof(calendar[4])的结果是31与sizeof(int)的乘积。int *p = calendar[4];使指针p指向了数组calendar[4]中下标为0的元素。
int i = calendar[4][7];等价于i = *(*(calendar+4)+7);。
p = calendar;是非法的。应该写为int (*monthp)[31]; monthp = calendar;,monthp会指向数组calendar的第1个元素,也就是数组calendar的12个有着31个元素的数组类型元素之一。 - 非数组的指针。字符串常量代表了一块包含字符串中所有字符以及一个空字符
'\0'的内存区域的地址。
例子:将字符串s和t连接成单个字符串r。可以这么写。
1 | char *r, *malloc( ); |
- 作为参数的数组声明。数组名作为参数没有意义,它会立刻被转换为指向该数组第一个元素的指针。
但不是所有情况下都有这种自动的转换。extern char *hello;和extern char hello[];有天壤之别。TODO4.5。
main(int argc, char* argv[]){}和main(int argc, char** argv){}。这两种写法完全等价,前一种写法更强调argv是一个指向某数组的起始元素的指针,该数组的元素为字符指针类型。 - 避免以整体代表部分或以部分代表整体。
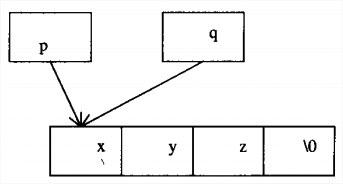
例如在char *p, *q; p = "xyz"; q=p;中,p的值是一个指向由’x’,‘y’,‘z’和’\0’4个字符组成的数组的起始元素的指针。p和q是指向内存中同一地址的两个指针。复制指针并不同时复制指针所指向的数据。
- 空指针并非空字符串。当将0赋值给一个指针变量时,绝对不能企图使用该指针所指向的内存中存储的内容。
例如:if (p == (char *)0) ...写法是合法的。但是如果写成这样,if (strcmp(p, (char*)0) == 0) ...就是非法的。因为库函数strcmp的实现中包括查看它的指针参数所指向内存中的内容的操作。 - 边界计算与不对称边界。C语言中一个拥有n个元素的数组的下标范围是从0到n-1为止。
程序设计错误中最难以察觉的一类是差一错误(off-by-one error)。要避免这个错误有两个原则。1.首先考虑最简单情况下的特例,然后将得到的结果外推。2.仔细计算边界,绝不掉以轻心。
所以表示范围的时候常常用半开区间[start,end),可以省去很多麻烦。
对于数组结尾之后的下一个元素,取它的地址是合法的,但是取值是非法的。
例子:程序按一定顺序生成一些整数,并将这些整数按列输出。程序的输出可能包括若干页的整数,每页包括NCOLS列,每列又包括NROWS个元素,每个元素就是一个待输出的整数。程序生成的整数是按列连续分布的,而不是按行分布的。
1 | /* |
- 求值顺序。C语言中只有四个运算符(
&&、||、?:、,)存在规定的求值顺序。运算符&&和运算符||首先对左侧操作数求值,只在需要时才对右侧操作数求值。运算符?:先对条件求值,然后再根据条件选择分支求值。逗号运算符首先对左侧操作数求值,然后该值被丢弃,再对右侧操作数求值。
例如:if (y != 0 && x/y > tolerance)保证仅当y非0时才对x/y求值。
而y[i] = x[i++];的写法是错误的,因为不能保证y[i]的地址在i的自增操作执行之前被求值。 - 运算符
&&、||和!与运算符&、|和~是截然不同的。例如10&12 = 8即二进制1010&1100 = 1000,10|12 = 14,~10=-11。而10&&12 = 1,10||12 = 1,!10 = 0。与运算符&&不同,运算符&两侧的操作数都必须被求值。 - 整数溢出。C语言中存在两类整数算术运算,有符号运算与无符号运算。在无符号算术运算中,没有溢出一说,所有的无符号运算都是以2的n次方为模。如果算术运算符的两个操作数分别是有符号和无符号整数,有符号整数会被转换为无符号整数,溢出也不会发生。但当两个操作数都是有符号整数时,就有可能发生结果未定义的溢出。
例如,假定a和b是两个非负整型变量,检查a+b是否会溢出。使用if((unsigned)a + (unsigned)b > INT_MAX){}或if(a > INT_MAX - b){}。 - 为函数main提供返回值。返回值为0表示程序执行成功,返回值非0则表示程序执行失败。
题目
- 问:编写一个函数,对一个已排序的整数表执行二分查找。函数的输入包括一个指向表头的指针,表中的元素个数,以及待查找的数值。函数的输出是一个指向满足查找要求的元素的指针,当未查找到满足要求的数值时,输出一个NULL指针。
答:注意其中做的优化。
1 | int *bsearch(int *t, int n, int x) |
连接
C程序通常是由若干个部分组成,它们分别进行编译,最后再整合起来。这个过程称为“连接”,是程序和其支持环境之间关系的一部分。
- 什么是连接器。典型的连接器把由汇编器生成的若干个目标模块,整合成一个被称为载入模块或可执行文件的实体,该实体能够被操作系统直接执行。连接器的输入是一组目标模块和库文件。连接器的输出是一个载入模块。连接器读入目标模块和库文件,同时生成载入模块。对每个目标模块中的每个外部对象,连接器都要检查载入模块,看是否已有同名的外部对象。如果没有,连接器就将该外部对象添加到载入模块中;如果有,连接器就要开始处理命名冲突。在连接器生成载入模块的过程中,还需要记录外部对象的引用。当连接器读入一个目标模块时,它需要解析出这个目标模块中定义的所有外部对象的引用,并作出标记说明这些外部对象不再是未定义的。
- 声明与定义。声明语句
int a;如果位置出现在所有函数体之外,那么它被称为外部对象a的定义。说明a是一个外部整型变量,同时为a分配了存储空间。未指定初始值的外部变量被初始化为0。而extern int a;也说明a是一个外部整型变量,但也说明a的存储空间是在程序的其他地方分配的,是对a的引用而不是定义。每个外部对象都必须在程序某个地方进行定义,并且只能定义一次。 - 命名冲突与static修饰符。static修饰符可以减少命名冲突。如
static int a;含义与int a;相同,但a的作用域限制在一个源文件内,对于其他源文件,a是不可见的。static不仅适用于变量,也适用于函数。 - 形参、实参与返回值。要明确类型,尤其是遇到在不同情形下可以接收不同类型的参数的函数。
- 检查外部类型。要保证一个特定名称的所有外部定义在每个目标模块中都有严格相同的类型。
- 头文件。每个外部对象只在一个地方声明,就是一个头文件中,所有需要用到该外部对象的模块都包含这个头文件。
题目
- 问:假定一个程序在一个源文件中包含了声明:
long foo;而在另一个源文件中包含了:extern short foo;。又进一步假定,如果给long类型的foo赋一个较小的值,例如37,那么short类型的foo就同时获得了一个值37。我们能够对运行该程序的硬件作出什么样的推断?如果short类型的foo得到的值不是37而是0,我们又能够作出什么样的推断?
答:如果把值37赋给long型的foo,相当于同时把值37也赋给了short型的foo,那么这意味着short型的foo,与long型的foo中包含了值37的有效位的部分,两者在内存中占用的是同一区域。这有可能是因为long型和short型被实现为同一类型,但很少有C语言实现会这样做。更有可能的是,long型的foo的低位部分与short型的foo共享了相同的内存空间,一般情况下,这个部分所处的内存地址较低;因此我们的一个可能推论就是,运行该程序的硬件是一个低位优先(little-endian)的机器。同样道理,如果在long型的foo中存储了值37,而short型的foo的值却是0,我们所用的硬件可能是一个高位优先(big-endian)的机器。
注:
Endian的意思是“数据在内存中的字节排列顺序”,表示一个字在内存中或传送过程中的字节顺序。在微处理器中,像long/DWORD(32bits) 0x12345678这样的数据总是按照高位优先(BIG ENDIAN)方式存放的。但在内存中,数据存放顺序则因微处理器厂商的不同而不同。一种顺序称为big-endian,即把最高位字节放在最前面;另一种顺序就称为little-endian,即把最低位字节放在最前面。
BIG ENDIAN:最低地址存放高位字节,可称为高位优先。内存从最低地址开始,按顺序存放。BIG ENDIAN存放方式正是我们的书写方式,高数位数字先写(比如,总是按照千百十个位来书写数字)。而且所有的处理器都是按照这个顺序存放数据的。
LITTLE ENDIAN:最低地址存放低位字节,可称为低位优先。内存从最低地址开始,顺序存放。LITTLE ENDIAN处理器是通过硬件将内存中的LITTLE ENDIAN排列顺序转换到寄存器的BIG ENDIAN排列顺序的,没有数据加载/存储的开销,不用担心。
库函数
可能的库函数误用。
- 返回整数的getchar函数,再赋值给char类型的话会被截断,可能出错。
- 更新顺序文件。为了保持与过去不能同时进行读写操作的程序的向下兼容性,一个输入操作不能随后直接紧跟一个输出操作,反之亦然。如果要同时进行输入和输出操作,必须在其中插入fseek函数的调用。
1 | FILE *fp; |
- 缓冲输出与内存分配。程序输出有两种方式:一种是即时处理方式,另一种是先暂存起来,然后再大块写入的方式,前者往往造成较高的系统负担。C语言使用库函数
setbuf(stdout, buf);控制实际写之前产生的输出数据量。为防止函数结束时缓冲数组刷新前就已经被释放,应该将缓冲数组设置为静态数组,或把声明移到函数之外,或动态分配缓冲区。 - 使用errno检测错误,错误则值为0,正确则不确定。
1 | // 调用库函数 |
- 库函数signal。包含头文件
#include <signal.h>。调用signal(signal type, handler function);。由于signal是异步,不要在其回调函数中进行诸如内存分配这种危险的操作,这个函数越简单越好。
题目
- 问:当一个程序异常终止时,程序输出的最后几行常常会丢失,原因是什么?可以采取怎样的措施来解决这个问题?
答:一个异常终止的程序可能没有机会来清空其输出缓冲区。因此,该程序生成的输出可能位于内存的某个位置,但却永远不会被写出了。在某些系统上,这些无法被写出的输出数据可能长达好几页。容易误导程序员,以为错误发生在实际位置之前。解决方案就是在调试时强制不允许对输出进行缓冲。可以把setbuf(stdout, (char*)0);这个语句写在任何输出被写入到stdout(包括任何对printf的调用)之前。最恰当的就是作为main函数的第一个语句。
预处理器
由于C预处理器的介入,实际运行的程序并不是最初编写的程序,它对程序代码作了必要的转换处理。
- 不能忽视宏定义中的空格。
#define f(x) ((x)-1)。 - 宏并不是函数。宏定义中应把每个参数都用括号括起来。另外还要确保宏中的参数没有副作用,如i++之类。要不然干脆用函数而不是宏。宏的另一个危险是,宏展开可能产生非常庞大的表达式,占用的空间远远超过了编程者所期望的空间。
- 宏并不是语句。展开时容易在ifelse语句中有{}或;应不应该有的错误。例如,正确的assert宏定义,并不是类似一个语句,而是类似一个表达式,利用了||运算符对两侧的操作数依次顺序求值的性质。
#define assert(e) ((void)((e)||_assert_error(__FILE__,__LINE__))) - 宏并不是类型定义。最好还是用类型定义
typedef struct foo FOOTYPE;。宏这样的粗暴展开容易在同时定义多个变量时缺失字符。
2个常用的却很普遍地被误解的库函数
printf函数族
printf、fprintf、sprintf。
int printf(const char* format, ...);printf将格式化字符串输出到标准输出stdout。
int fprintf(FILE* stream, const char* format, ...);fprintf将格式化字符串输出到任意文件。
int sprintf(char* str, const char* format, ...);sprintf将格式化字符串输出到字符数组。
format
format参数是这种格式%[flags][width][.precision][length]specifier。
specifier
| specifier | Output | Example |
|---|---|---|
| d or i | Signed decimal integer | 392 |
| u | Unsigned decimal integer | 7235 |
| o | Unsigned octal | 610 |
| x | Unsigned hexadecimal integer | 7fa |
| X | Unsigned hexadecimal integer (uppercase) | 7FA |
| f | Decimal floating point, lowercase | 392.65 |
| F | Decimal floating point, uppercase | 392.65 |
| e | Scientific notation (mantissa/exponent), lowercase | 3.9265e+2 |
| E | Scientific notation (mantissa/exponent), uppercase | 3.9265E+2 |
| g | Use the shortest representation: %e or %f | 392.65 |
| G | Use the shortest representation: %E or %F | 392.65 |
| a | Hexadecimal floating point, lowercase | -0xc.90fep-2 |
| A | Hexadecimal floating point, uppercase | -0XC.90FEP-2 |
| c | Character | a |
| s | String of characters | sample |
| p | Pointer address | b8000000 |
| n | Nothing printed.The corresponding argument must be a pointer to a signed int. The number of characters written so far is stored in the pointed location. |
|
| % | A % followed by another % character will write a single % to the stream. | % |
flags
| flags | description |
|---|---|
| - | Left-justify within the given field width; Right justification is the default (see width sub-specifier). |
| + | Forces to preceed the result with a plus or minus sign (+ or -) even for positive numbers. By default, only negative numbers are preceded with a - sign. |
| (space) | If no sign is going to be written, a blank space is inserted before the value. |
| # | Used with o, x or X specifiers the value is preceeded with 0, 0x or 0X respectively for values different than zero. Used with a, A, e, E, f, F, g or G it forces the written output to contain a decimal point even if no more digits follow. By default, if no digits follow, no decimal point is written. |
| 0 | Left-pads the number with zeroes (0) instead of spaces when padding is specified (see width sub-specifier). |
width
| width | description |
|---|---|
| (number) | Minimum number of characters to be printed. If the value to be printed is shorter than this number, the result is padded with blank spaces. The value is not truncated even if the result is larger. |
| * | The width is not specified in the format string, but as an additional integer value argument preceding the argument that has to be formatted. |
.precision
| .precision | description |
|---|---|
| .number | For integer specifiers (d, i, o, u, x, X): precision specifies the minimum number of digits to be written. If the value to be written is shorter than this number, the result is padded with leading zeros. The value is not truncated even if the result is longer. A precision of 0 means that no character is written for the value 0. For a, A, e, E, f and F specifiers: this is the number of digits to be printed after the decimal point (by default, this is 6). For g and G specifiers: This is the maximum number of significant digits to be printed. For s: this is the maximum number of characters to be printed. By default all characters are printed until the ending null character is encountered. If the period is specified without an explicit value for precision, 0 is assumed. |
| .* | The precision is not specified in the format string, but as an additional integer value argument preceding the argument that has to be formatted. |
返回值
如果成功,返回格式化字符串的长度。如果失败,返回一个负值,并设置错误码ferror。如果是一个宽字节编码错误,错误码errno是EILSEQ。
示例
1 | /* printf example */ |
1 | /* fprintf example */ |
1 | /* sprintf example */ |
cstdarg(stdarg.h)实现可变参数
va_list、va_start、va_arg、va_end、va_copy
void va_start (va_list ap, paramN);
type va_arg (va_list ap, type)
void va_end (va_list ap);
void va_copy (va_list dest, va_list src);
- 使用
va_start初始化定义为va_list的变量列表。 - 随后
va_arg按照传递进函数的顺序生成额外的参数。 - 在函数返回前执行
va_end。
例子
1 | /* va_start example */ |
1 | /* va_arg example */ |
1 | /* va_end example */ |
1 | /* va_copy example */ |
作者的建议
作者归纳道,要避免那些最令人生厌的那种看起来能工作却深藏bug的程序,最好的办法就是事前周密思考。
- 小心极具伪装性和欺骗性的bug。比如==和=的问题。
- 直截了当地表明意图,用括号等方式消除可能的误解。
- 考察最简单的特例。比如输入数据为空或只有一个元素。
- 使用不对称边界。注意C中数组下标取值从0开始。
- 避免使用生僻的语言特性,以规避编译器差异造成的迷惑。
- 防御性编程。
另外
- 问:在烹饪时你是否失手用菜刀切伤过自己的手?怎样改进菜刀使得使用更安全?你是否愿意使用这样一把经过改良的菜刀?
答:我们很容易想到办法让一个工具更安全,代价是原来简单的工具现在要变得复杂一些。食品加工机一般有连锁装置,保护使用者不让手指受伤。但是菜刀却不同,给这样一个简单、灵活的工具附加保护手指避免受伤的装置,只能让它失去简单灵活的特点。实际上,这样做最后得到的也许更像一台食品加工机,而不是一把菜刀。使其难于做傻事常常也会使其难于做聪明事,正所谓弄巧成拙。
[1] C陷阱与缺陷
[2] http://www.cplusplus.com/reference/cstdio/printf/
[3] http://www.cplusplus.com/reference/cstdio/fprintf/
[4] http://www.cplusplus.com/reference/cstdio/sprintf/
[5] http://www.cplusplus.com/reference/cstdarg/