Transform and Conquer
变治法
变治法是一组基于变换思想的技术,用来把问题变换成一种更容易解决的类型。
变治法有3种主要的类型:
- 实例化简。是一种把问题的实例变换成相同问题的另一个实例的技术,这个新的实例有一些特殊的属性,使得它更容易被解决。列表预排序、高斯消去法和AVL树都是这种技术的好例子。
- 改变表现。是将一个问题实例的表现改变为同样实例的另一种表现。比如2-3树表示集合、堆和堆排序、求多项式的霍纳法则以及两种二进制幂算法。
- 问题化简。提倡把一个给定的问题变换为另一个可以用已知算法求解的问题。如化简为线性规划问题和化简为图问题。
预排序
如果列表是有序的话,很多关于列表的问题更容易求解。排序算法的效率超不过nlogn。
- **例1:检验数组中元素的唯一性。**先对数组排序,然后只检查它的连续元素:如果该数组有相等的元素,则一定有一对元素是相互紧挨着的,反之亦然。
- 例2:模式计算。在给定的数字列表中最经常出现的一个数值成为模式。可以先对输入排序。然后所有相等的数值都会邻接在一起。为了求出模式,我们需要做的全部工作就是求出在该有序数组中邻接次数最多的等值元素。
许多处理点集合的几何算法都使用了这样或那样的预排序。点的排序依据可以是它们的一个坐标,或者是它们到一条特定直线的距离,或者是根据某种角度等。如之前解决的最近对问题和凸包问题的分治算法。
相关题目
-
给定一个集合,里面包含个在x-y坐标平面上的点,用简单多边形把它们连接起来,也就是一条穿过所有点的最短路径,并且它的线段(多边形的边)不能相互交叉(除了公共顶点上的两条相邻边)。如下图。为该问题设计一个较为高效的算法。
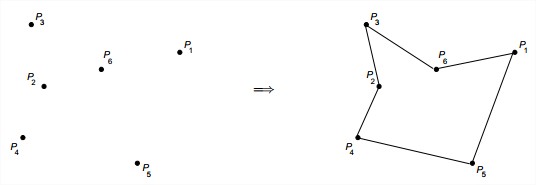
答案:该问题在点不是全共线的时候有解,且解可能不唯一。思路是:先找到y值最小的点P^\*,再求其它n-1的点在极坐标下的角度,排序。最后按顺序连接这些点。如图:
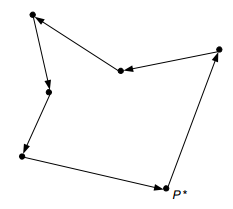
极坐标(在平面内取一个定点O,叫极点,引一条射线Ox,叫做极轴,再选定一个长度单位和角度的正方向(通常取逆时针方向)。对于平面内任何一点M,用ρ表示线段OM的长度,θ表示从Ox到OM的角度,ρ叫做点M的极径,θ叫做点M的极角,有序数对 (ρ,θ)就叫点M的极坐标)。 -
我们有一个n个数字构成的数组以及一个整数s。确定该数组是否包含两个和为s的元素(例如,对于数组5,9,1,3和s=6,答案为是,但对于相同的数组和s=7,答案为否)。为该问题设计一个算法,使它的时间效率要好于平方级。
思路:1. 先对所有的点减s/2,变成s=0的情况。2. 如果数组值唯一,把A[i]变成abs(A[i])排序,看看是否有重复元素。3. 如果数组值不唯一,按abs(A[i])排序,看有无相邻相加为0的元素对。
相关leetcode题目,算法不同:
[Arrays] | Two Sum
[Arrays] | 3Sum
[Arrays] | 3Sum Closest
[Arrays] | 4Sum -
我们在实数域上有n个开区间(开区间(a,b)是由严格位于端点a和b之间的所有点构成的,即)。求包含共同点的区间的最大数量。例如,对于区间(1,4),(0,3),(-1.5,2),(3.6,5)来说,这个数量是3。为这个问题设计一个算法,要求效率要好于平方级。
思路:把a和b放在同一个数组里排序,遇到a和b相等时认为b比较小。然后遍历此数组,遇到a加1,遇到b减1,求得此过程中的最大值。
类似括号那个问题[Stacks],如题目中的描述其实等价于"((())())"。
高斯消去法
高斯消去法是一种解线性方程组的算法,它是线性代数中的一种基本算法。它通过把方程组变换为一种具有上三角形系数矩阵的方程组来解题,这种方程组很容易用反向替换法求解。高斯消去法大约需要次乘法运算。
经典高斯消去法
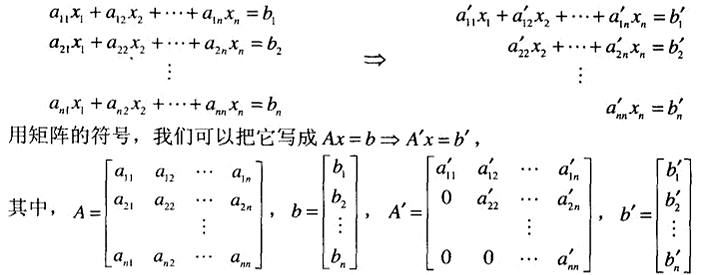
可以通过一系列初等变换将一个具有任意系数矩阵的方程组推导为一个具有上三角系数矩阵的等价方程组。

优化:为防止比例因子过大而有舍入误差,可以每次都去找第i列系数的绝对值最大的行,作为第i次迭代的基点。部分选主元法,保证比例因子的绝对值永远不会大于1。
高斯消去法消去阶段使用部分选主元法的一个实现。
1 |
|
LU分解及其他应用
对于如图的矩阵A:
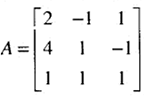
考虑下三角矩阵L,它是由主对角线上的1以及在高斯消去过程中行的乘数所构成的:
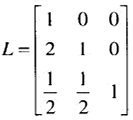
而上三角矩阵U是消去的结果:
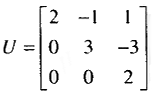
可以看出,这两个矩阵的乘积LU等于矩阵A。
所以解方程组Ax=b等价于解方程组LUx=b。于是可以先求出Ux,再求出x。
LU分解实际上并不需要额外的存储空间,因为我们可以把U的非零部分存储在A的上三角部分(包括主对角线),并把L中的有效部分存储在A的主对角线的下方。
计算矩阵的逆
一个n阶方阵的逆也是一个n阶方阵,记作,使得。是一个n阶的单位矩阵。
不是每一个方阵都有逆,当且仅当矩阵的某一行是其他行的一个线性组合(某些乘积的和)时,没有逆,称为退化矩阵。
检查矩阵是否退化的一个简便方法是应用高斯消去法:如果高斯消去法生成的上三角矩阵的主对角线不包含0,该矩阵是非退化的;否则,是退化的。
计算矩阵的逆可以视为解n个具有相同系数矩阵的线性方程组。可以使用高斯消去法求出的分解,然后再对方程组求解。
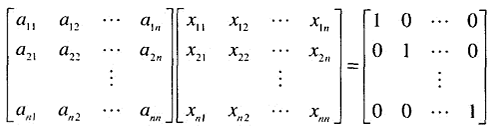
相关题目
- 高斯-若尔当消去法和高斯消去法的不同在于,在系数矩阵的主对角线下方的元素变为0的同时,它用主元行把主对角线上方的元素也变成了0。如:
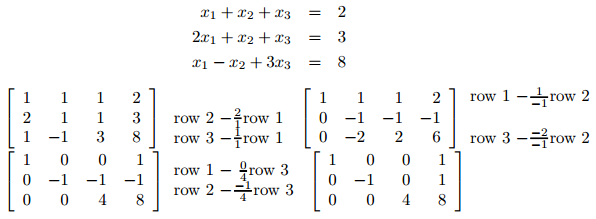
1 | #include <vector> |
- 关灯问题。这个单人游戏中有一块的面板,都是由的电灯小面板组成的。每个小面板都有一个开关可以打开或关闭,这会同时打开或关闭水平和垂直邻接的4块小面板的灯(因此,拨动角上的面板开关会改变3个面板的灯,拨动边界上的非角落的面板开关会改变4个面板的灯)。如果知道初始时哪些灯是点亮的,如何关闭所有的灯呢?(利用高斯消去法解该问题的全1实例。)
思路:一个面板点击中间(2,2)可以用矩阵这样表示:
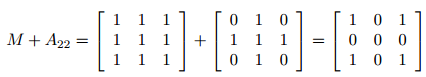
所以可以列出等式: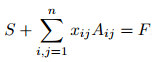
那么的问题可以列出下面的式子,得到4个四项式方程。然后用高斯消去法求解即可。
平衡查找树
维持平衡的两种思路:
- 实例化简。把一棵不平衡的二叉查找树转变为平衡的形式。这个思想的特定实现之间的区别在于它们对平衡的定义是不同的。AVL树要求它的每个节点的左右子树的高度差不能超过1。红黑树能够容忍同一节点的一棵子树的高度是另一棵的两倍。如果一个节点的插入或删除产生了一棵违背平衡要求的树,我们就从一系列成为旋转的特定变换中选择一种,重新构造这棵树,使得这棵树重新满足平衡要求。
- 改变表现。允许一棵查找树的单个节点不止包含一个元素。这种树的特例是2-3树,2-3-4树,以及更一般和更重要的B树。
AVL树
AVL树是一种在二叉树可能达到的广度上尽量平衡的二叉查找树。平衡是由四种称为旋转的变换来维持的。AVL树上的所有基本操作都属于O(logn),它消除了经典二叉查找树在最差效率上的弊端。
2-3树
2-3树是一种得到了完美平衡的查找树,它允许一个节点最多包含两个键和三个子女。这个思想推而广之,会产生一种非常重要的B树。
2-3树是一种可以包含两种类型节点的树:2节点和3节点。一个2节点只包含一个键K和两个子女:左子女作为一棵所有键都小于K的子树的根,而右子女作为一棵所有键都大于K的子树的根。一个3节点包含两个有序的键K1和K2(K1<K2)并且有3个子女。最左边的子女作为键值小于K1的子树的根,中间的子女作为键值位于K1和K2之间的子树的根,最右边的子女作为键值大于K2的子树的根。
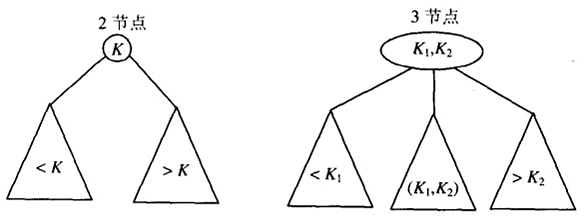
2-3树的最后一个要求是,树中的所有叶子必须位于同一层,也就是说,一棵2-3树总是高度平衡的。
- 查找。如果是2节点,与二叉查找树一样。如果是3节点,在不超过两次比较之后,就知道是停止查找还是应该在根的3棵子树的哪一棵继续查找。
- 插入。首先,除非空树,否则总是把一个新的键K插入到一个叶子里。通过查找K来确定一个合适的插入位置。如果找到的叶子是一个2节点,根据K是小于还是大于节点中原来的键,我们把K作为第一个键或者第二个键进行插入。如果叶子是一个3节点,我们把叶子分裂成两个节点:三个键(两个原来的键和一个新键)中最小的放入第一个叶子里,最大的键放到第二个叶子里,同时中间的键提升到原来叶子的父母中去(如果这个叶子恰好是树的根,我们就创建一个新的根来接纳这个中间键)。注意,中间键提升到父母中去可能会导致父母的溢出(如果它是一个3节点),并且因此会导致沿着该叶子的祖先链条发生多个节点的分裂。
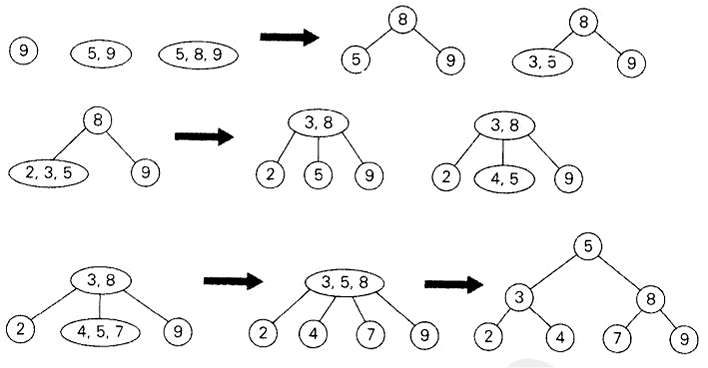
1 | // 构造一棵2-3树 |
2-3树有一种重要的一般性形式,B树,详细看这里。
堆和堆排序
堆是一棵基本完备二叉树,它的键都满足父母优势的要求(即每一个节点的键都要大于或等于它子女的键)。虽然定义为二叉树,但一般用数组来实现堆。堆对于优先队列的高效实现来说尤为重要,同时,堆还是堆排序的基础。
堆排序的基本思路是,在排列好堆中的数组元素后,再从剩余的堆中连续删除最大的元素。无论在最差情况还是在平均情况下,该算法的运行时间都属于O(nlogn),而且,它还是在位的排序算法。
堆的一些性质:
- 只存在一棵n个节点的完全二叉树,它的高度等于。
- 堆的根总是包含了堆的最大元素。
- 堆的一个节点以及该节点的子孙也是一个堆。
- 可以用数组来实现堆,方法是用从上到下、从左到右的方式来记录堆的元素。为了方便起见,可以在这种数组从1到n的位置上存放堆元素,留下H[0],要么让它空着,要么在其中放一个限位器,它的值大于堆中任何一个元素。在这种表示法中:
-
- 父母节点的键将会位于数组的前n/2个位置中,而叶子节点的键将会占据后n/2个位置。
-
- 在数组中,对于一个位于父母位置的键来说,它的子女将会位于和,相应地,对于一个位于的键来说,它的父母将会位于。
- 因此数组前半部分每个位置i上的元素总是大于等于位置2i和2i+1中的元素。
构造一个堆
自底向上堆构造:按照给定的顺序放置键,然后按照下面的方法对树进行“堆化”:
- 从最后的父母节点,到根为止,检查这些节点的键是否满足父母优势要求。
- 如果该节点不满足,把节点的键K和它子女的最大键进行交换,然后再检查在新位置上,K是不是满足父母优势要求。
- 持续这个过程直到对K的父母优势要求满足为止。
- 对以当前父母节点为根的子树,完成它的“堆化”后,对该节点的前一节点继续同样的操作。直到对树的根也完成以上操作。
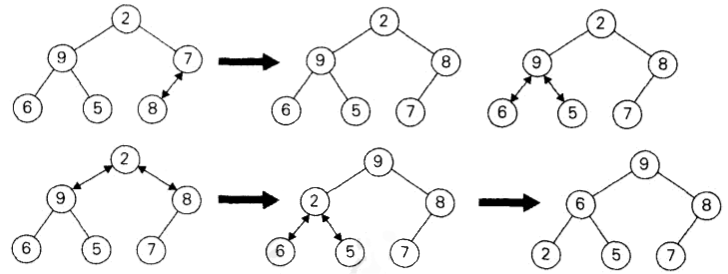
从堆中删除一个元素
- 如果该节点时叶子节点,直接删除,并将堆的规模减1。
- 否则,该节点的键和堆的最后一个键K作交换。
- 堆的规模减1.
- 严格按照自底向上堆构造算法中的做法,把K沿着树向下筛选,来对这棵较小的树进行“堆化”。
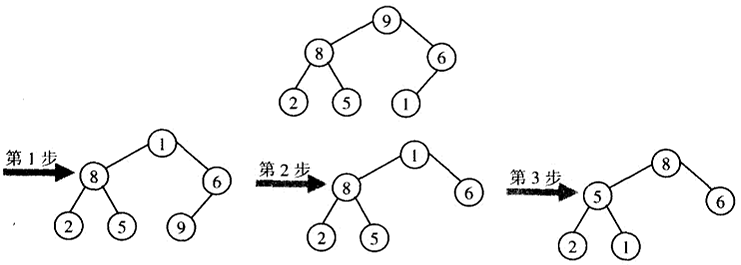
堆排序
第一步:(构造堆)为一个给定的数组构造一个堆。
第二步:(删除最大键)对剩下的堆应用n-1次根删除操作。
堆排序的详细解释和实现看这里。
相关题目
- 面条排序。想象一把意大利生面条,每一根面条代表一个需要排序的数字。描述这个“面条排序”以及它和堆排序的关系。
解答:把面条一把挂起来,垂直下来,不断拿走最长的那根。和堆排序一样,针对最大元素的寻找和删除都很容易。
霍纳法则和二进制幂
已知x,求多项式
的值的问题。以及该问题的一个特例——计算。
目前最重要的算法是快速傅立叶变换(fast Fourier transform, FFT),基本思想史用多项式在某些特定点上的值来表示该对象式。[快速傅立叶变换详情见这里]。
在无需对系数进行预处理的多项式求解算法中,霍纳法则是最优的。它只需要n次乘法和n次加法。它还有一些有用的副产品,比如综合除法算法。
霍纳法则
相当于不断地把x作为公因子从降次以后的剩余多项式中提取出来。
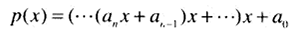
可以方便地用一个两行的表来帮助笔算。第一行包含了该多项式的系数(如果有0也包含进来),从最高的到最低的。第二行中,除了第一个单元格用来存储,其他单元格都用来存储中间结果。做了这样的初始化以后,用第二行的前一个有值的单元格乘以x的值再加上第一行的下一个参数,来算出表格下一个单元格的值。最后一个单元格的值就是多项式的值。
例如:对于多项式,改变形式的话就是:
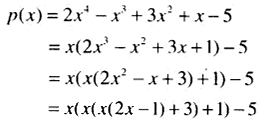
当x=3时,用表格的方式进行计算:

答案就是160。观察可以发现,表格第二行每个元素恰好就是前面公式改变形式后每个单独子式。
1 | #include <vector> |
二进制幂
当用霍纳法则计算时,它惊人的效率就失去了光芒,退化成为对x自乘的蛮力算法,还夹杂着一些无用的加法。
有两种基于改变表现思想的解决算法。这两种算法都使用了指数n的二进制表示,但一个算法从左到右处理这个二进制,而另一个从右到左进行处理。
设n=b1…bi…b0是在二进制系统中,表示一个正整数n的比特串。可以用这个多项式的值来计算n的值:
如
- 从左至右二进制幂算法,将多项式用霍纳方式表示与迭代计算。
对这个多项式应用霍纳法则,这个过程对意味着什么:

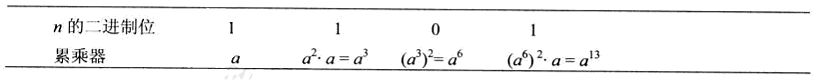
1 |
|
- 从右至左二进制幂算法,以分解的方式使用该多项式,然后用各项积来计算结果。
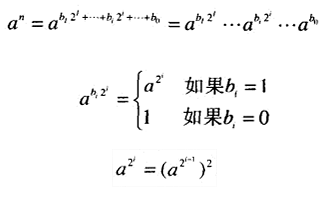

1 |
|
问题化简
将一个待解问题化简为一个已知可以用某解法求解的问题,然后求解。
解析几何的根本思想就是把几何问题化简为代数问题。
求最小公倍数
最小公倍数,记作lcm(m,n),定义为能够被m和n整除的最小整数。原始计算方法是,给出m和n的质因数,把m和n的所有公共质因数的积乘以m的不在n中的质因数,再乘以n的不在m中的质因数。
我们已知求最大公约数的欧几里得算法gcd(m,n),找到它俩的联系,即lcm(m,n)和gcd(m,n)的积把m和n的每一个因子都恰好包含了一次,因此就等于m和n的积。
注:最大公约数的算法是:
1 | int gcd(inta,intb) |
因为最小公倍数=重复的*A中单独的*B中单独的。最大公约数=重复的。
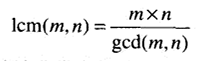
gcd(m,n) = gcd(n, m%n)
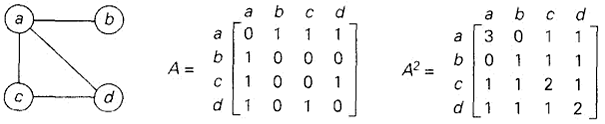
计算图中的路径数量
图两节点间路径的数量可以从邻接矩阵上看出。可以用一个算法来计算图的邻接矩阵的相应幂,来得出图中的路径数量。
优化问题的化简
最大化问题和最小化问题的关系:。即求一个函数的最小值,可以先求负函数的最大值,再取反。
线性规划
线性规划关心的是最优化一个包含若干变量的线性函数,这个函数受到一些形式为线性等式和线性不等式的约束。有一些高效的算法可以对这个问题的庞大实例求解,它们包含了成千上万的变量和约束,但不能要求变量必须是整数。如果变量一定要是整数,我们称之为整数线性规划问题,这类问题的难度要高很多。
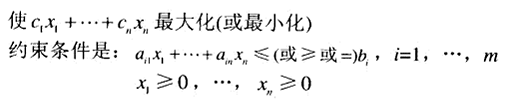
这个问题的经典算法称为单纯形法。
简化为图问题
许多问题可以化简为一种标准的图问题。图的顶点一般用来表示所讨论问题的可能状态,而边则表示这些状态之间的可能转变。称为状态空间图。
比如狼、羊、白菜、农夫问题。P,w,g,c表示农夫、狼、羊和白菜。
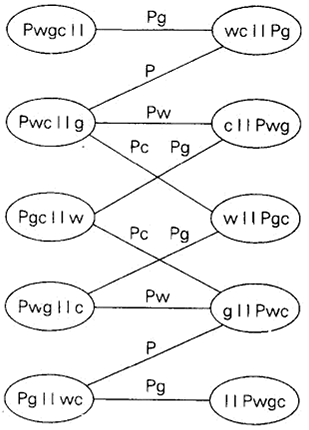
这是人工智能的一个分支。
[1] 算法设计与分析基础(第2版)