论文 Deep Face Recognition - A Survey
History。2014年起转向 deep-learning-based 方法。常见 network architecture 有 convolutional neural networks (CNNs),deep belief networks (DBNs),stacked autoencoders (SAEs)。
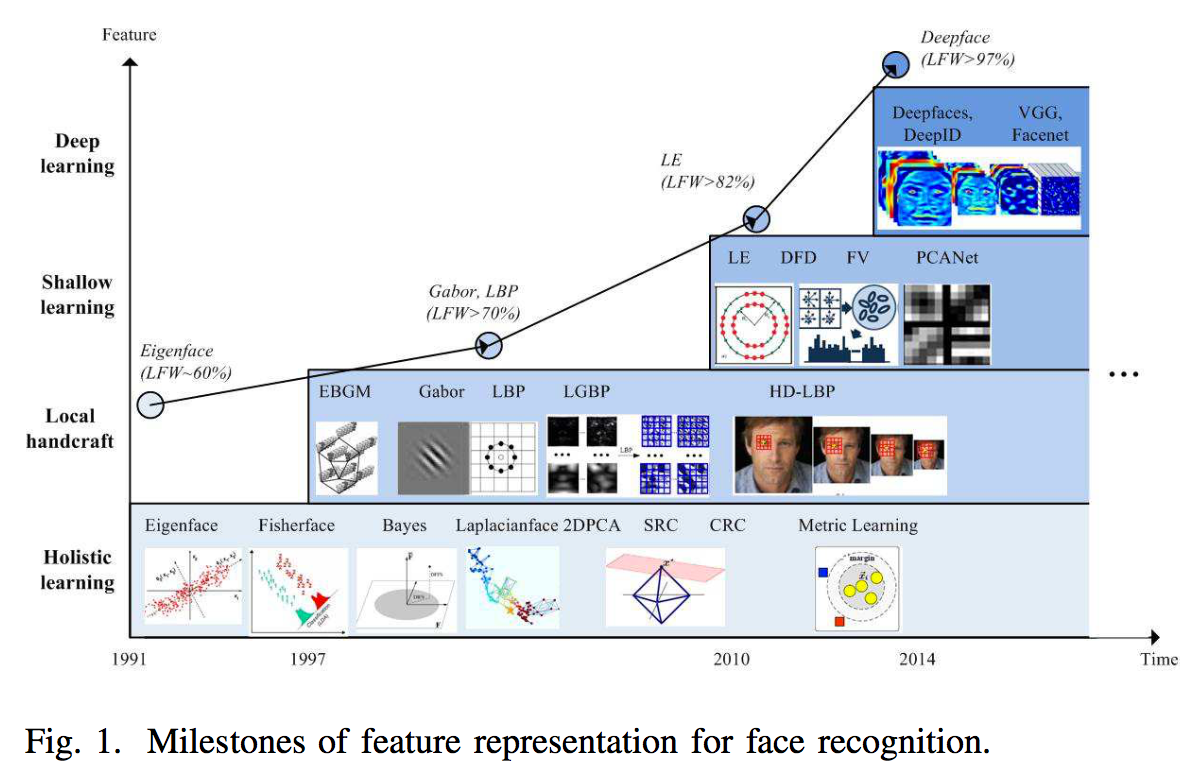
人脸识别的麻烦在于:太多种不同的人脸不可能拿到所有 class;一个人自身不同情况(pose, illuminations, expressions, ages, occlusions)的差异可能大于与另一个人的差异;
本文从data,algorithm,FR scene 三个角度总结。
Background Concepts and Terminology
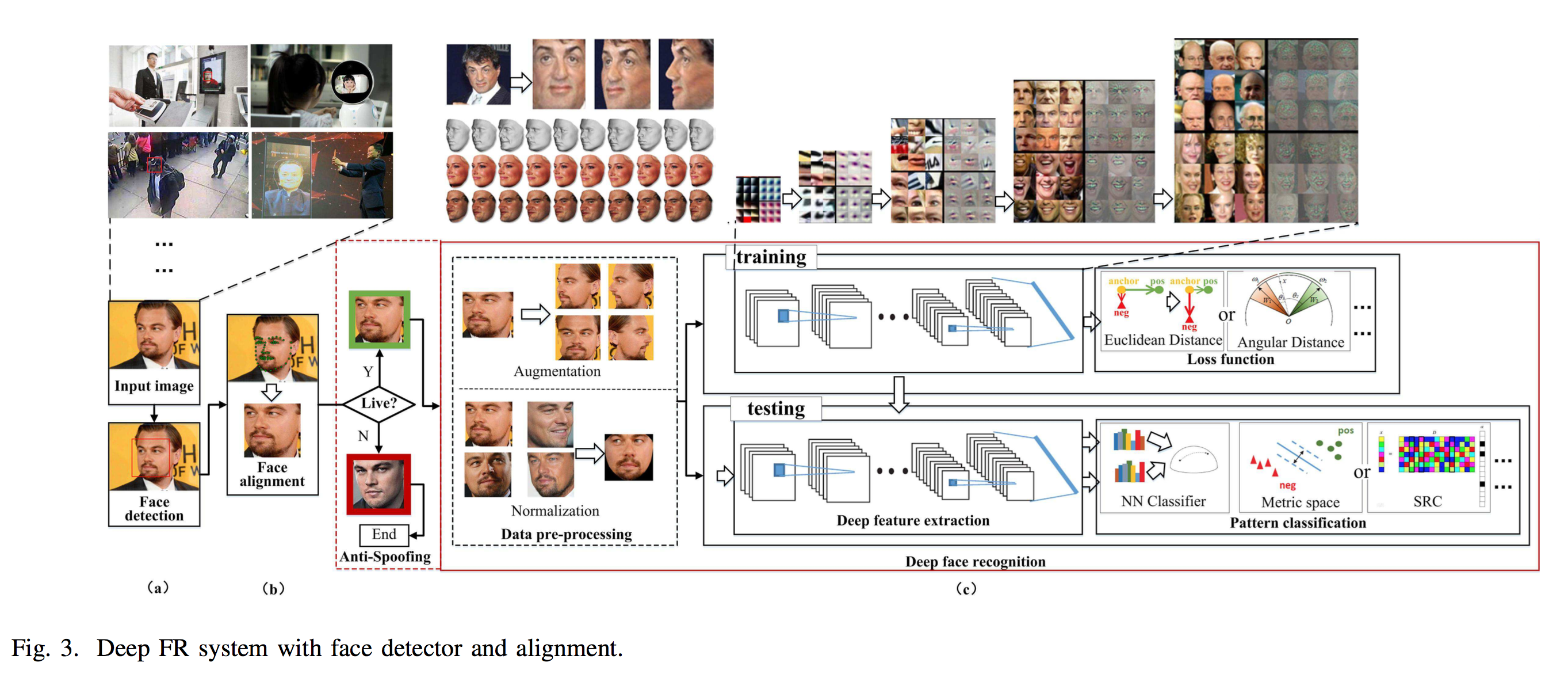
Face recognition:
Detection -> Alignment (~= landmark localization) -> Recognition
- face verification: one-to-one similarity. Same person?
- face identification: one-to-many similarity. Appears in the gallery?
Components of Face Recognition
data preprocessing -> deep feature extraction -> similarity comparison

Data Preprocessing
影响因素有 poses, illuminations, expressions, occlusions。
两个方向:
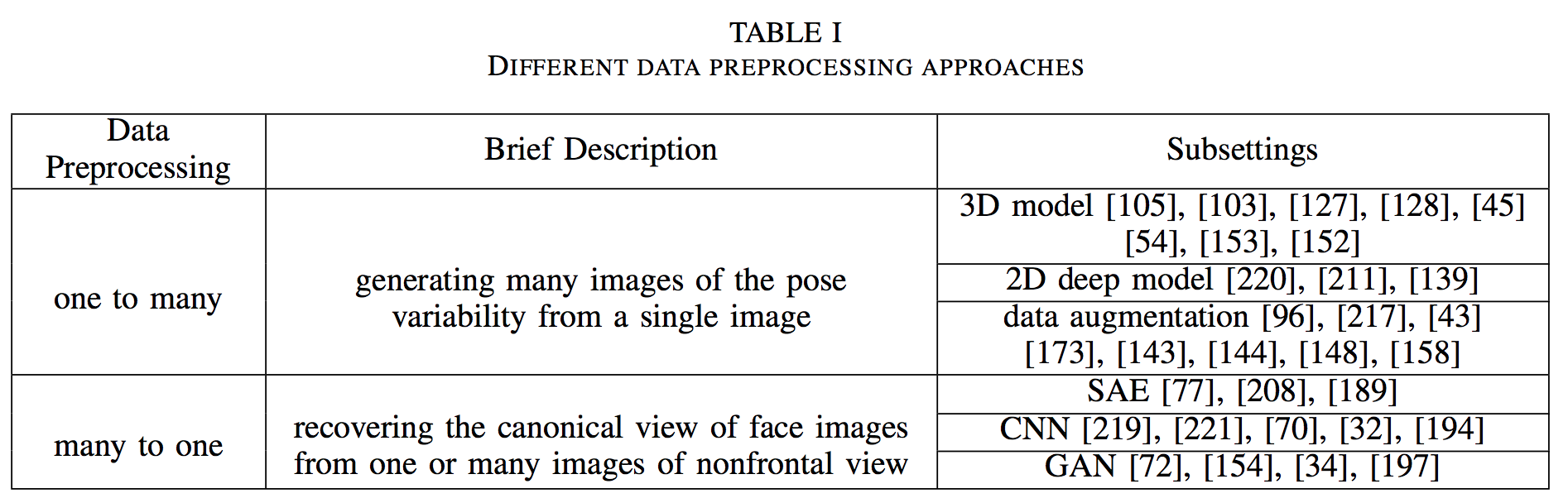
One to Many
- Data Augmentation
photometric transformations and geometric transformations, such as oversampling (multiple patches obtained by cropping at different scales) , mirroring, and rotating the images. - 3D Model
- 2D Deep Model
| 思路 | id | 简介 | 论文 |
|---|---|---|---|
| 3D model | 105 | Generated face images with new intra - class facial appearance variations, including pose, shape and expression, and then trained a 19-layer VGGNet with both real and augmented data. | I. Masi, A. T. Tr?n, T. Hassner, J. T. Leksut, and G. Medioni. Do wereally need to collect millions of faces for effective face recognition?In ECCV, pages 579–596. Springer, 2016. |
| 103 | Used generic 3D faces and rendered fixed views to reduce much of the computational effort. | I. Masi, T. Hassner, A. T. Tran, and G. Medioni. Rapid synthesis of massive face sets for improved face recognition. In FG 2017, pages 604–611. IEEE, 2017. | |
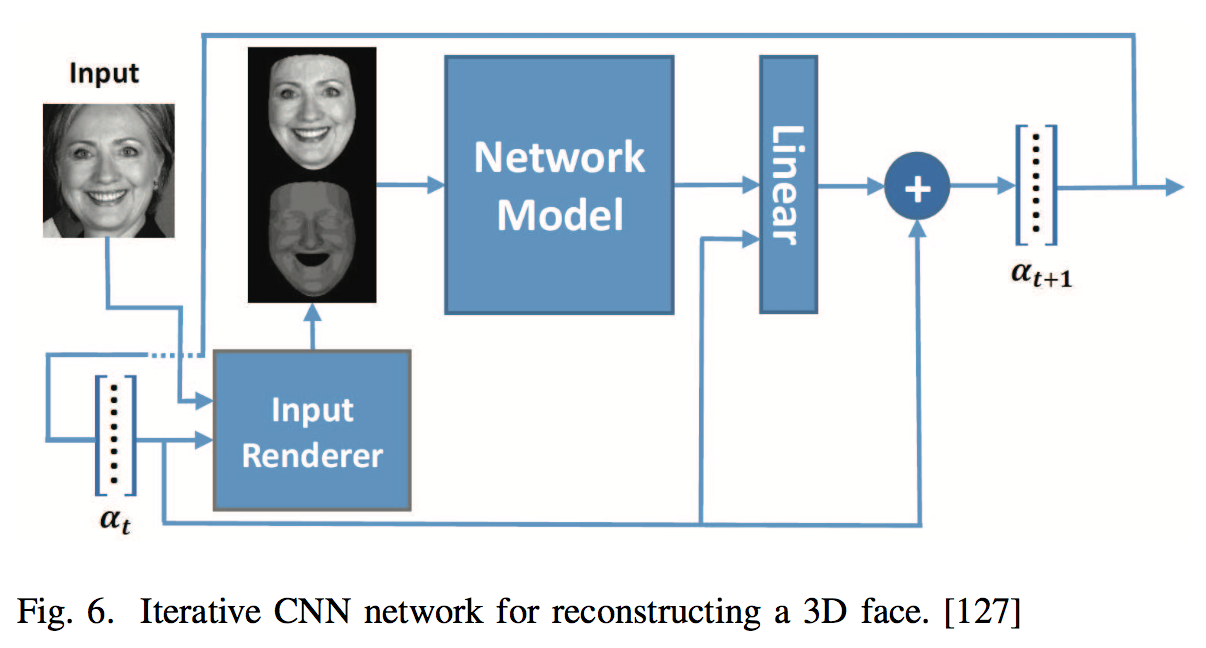
| 127 | An iterative CNN by using a secondary input channel to represent the previous network’s output as an image for reconstructing a 3D face. | E. Richardson, M. Sela, and R. Kimmel. 3d face reconstruction bylearning from synthetic data. In 3DV, pages 460–469. IEEE, 2016. | |
| 128 | E. Richardson, M. Sela, R. Or-El, and R. Kimmel. Learning detailed face reconstruction from a single image. In CVPR, pages 5553–5562. IEEE, 2017. | ||
| 45 | a multi-task CNN to divide 3D face reconstruction into neutral 3D reconstruction and expressive 3D reconstruction. | P. Dou, S. K. Shah, and I. A. Kakadiaris. End-to-end 3d facereconstruction with deep neural networks. In CVPR, volume 5, 2017. | |
| 54 | Y. Guo, J. Zhang, J. Cai, B. Jiang, and J. Zheng. 3dfacenet: Real-time dense face reconstruction via synthesizing photo-realistic face images.,2017. | ||
| 153 | Regressed 3D morphable face model (3DMM) parameters from an input photo by a very deep CNN architecture. | A. T. Tran, T. Hassner, I. Masi, and G. Medioni. Regressing robust and discriminative 3d morphable models with a very deep neural network.In CVPR, pages 1493–1502. IEEE, 2017. | |
| 152 | A. Tewari, M. Zollho ̈fer, H. Kim, P. Garrido, F. Bernard, P. Perez, and C. Theobalt. Mofa: Model-based deep convolutional face autoencoder for unsupervised monocular reconstruction. In ICCV, volume 2, 2017. | ||
| 2D deep model | 220 | Z. Zhu, P. Luo, X. Wang, and X. Tang. Multi-view perceptron: a deepmodel for learning face identity and view representations. In NIPS,pages 217–225, 2014. | |
| 211 | After using a 3D model to generate profile face images, refined the images by a generative adversarial network (GAN) , which combines prior knowledge of the data distribution and knowledge of faces (pose and identity perception loss). | J. Zhao, L. Xiong, P. K. Jayashree, J. Li, F. Zhao, Z. Wang, P. S. Pranata, P. S. Shen, S. Yan, and J. Feng. Dual-agent gans for photorealistic and identity preserving profile face synthesis. In NIPS, pages 65–75, 2017. | |
| 139 | A. Shrivastava, T. Pfister, O. Tuzel, J. Susskind, W. Wang, and R. Webb. Learning from simulated and unsupervised images through adversarial training. In CVPR, volume 3, page 6, 2017. | ||
| Data Augmentation | 96 | Seven CNNs with the same structure were used on seven overlapped image patches centered at different landmarks on the face region. | J. Liu, Y. Deng, T. Bai, Z. Wei, and C. Huang. Targeting ultimate accuracy: Face recognition via deep embedding. arXiv preprint arXiv:1506.07310, 2015. |
| 217 | E. Zhou, Z. Cao, and Q. Yin. Naive-deep face recognition: Touching the limit of lfw benchmark or not? arXiv preprint arXiv:1501.04690, 2015. | ||
| 43 | C. Ding and D. Tao. Robust face recognition via multimodal deep face representation. IEEE Transactions on Multimedia, 17(11):2049–2058, 2015. | ||
| 173 | W.-S.T.WST.Deeplylearnedfacerepresentationsaresparse,selective, and robust. perception, 31:411–438, 2008. | ||
| 143 | Cropped 400 face patches varying in positions, scales, and color channels and mirrored the images. | Y. Sun, Y. Chen, X. Wang, and X. Tang. Deep learning face representation by joint identification-verification. In NIPS, pages 1988– 1996, 2014. | |
| 144 | Y. Sun, D. Liang, X. Wang, and X. Tang. Deepid3: Face recognition with very deep neural networks. arXiv preprint arXiv:1502.00873, 2015. | ||
| 148 | Y. Sun, X. Wang, and X. Tang. Sparsifying neural network connections for face recognition. In CVPR, pages 4856–4864, 2016. | ||
| 158 | D. Wang, C. Otto, and A. K. Jain. Face search at scale: 80 million gallery. arXiv preprint arXiv:1507.07242, 2015. |
Many-to-One Normalization
- SAE
- CNN
- GAN
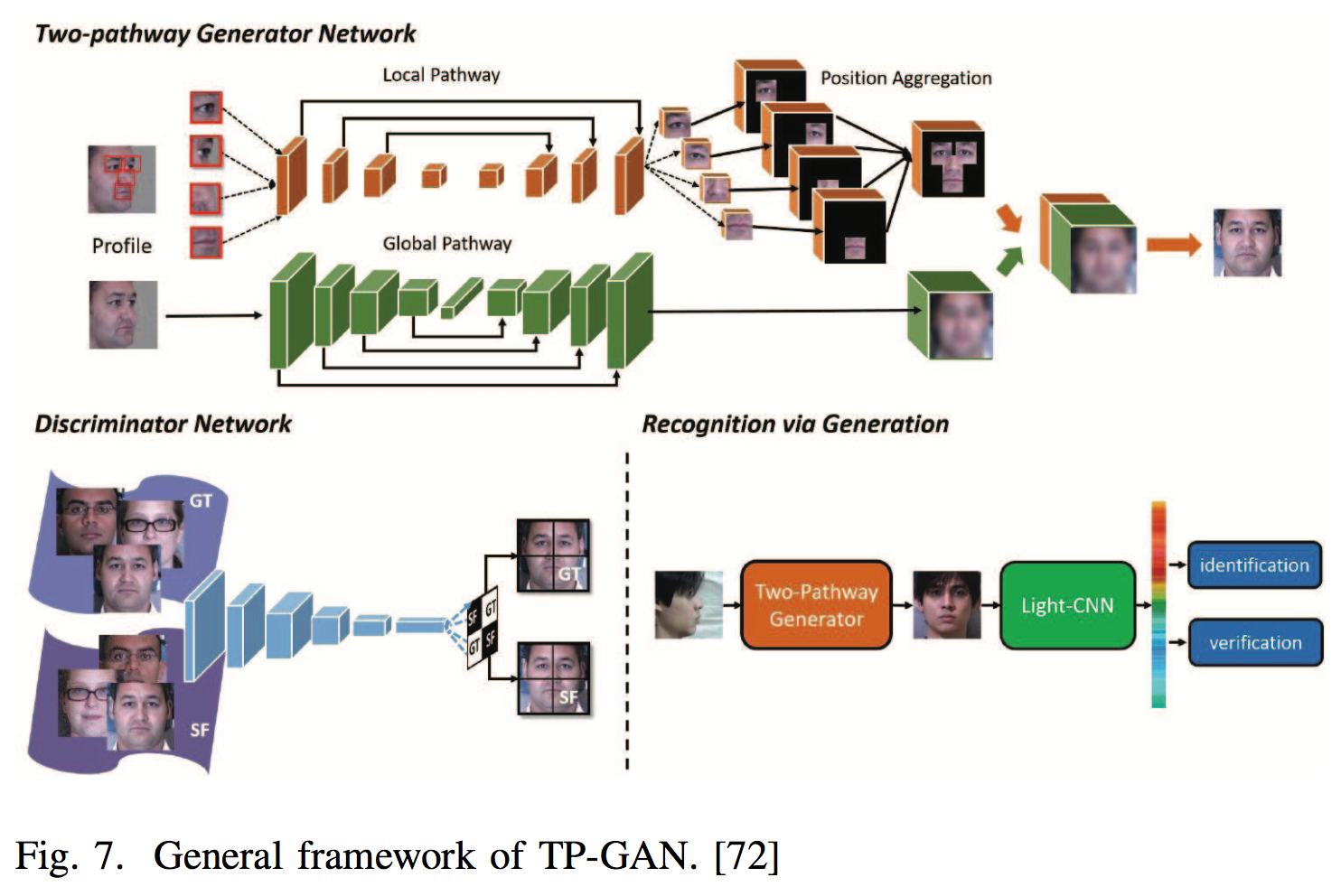
| 思路 | id | 简介 | 论文 |
|---|---|---|---|
| SAE | 77 | The proposed stacked progressive autoencoders (SPAE) progressively map the nonfrontal face to the frontal face through a stack of several autoencoders. | M. Kan, S. Shan, H. Chang, and X. Chen. Stacked progressive autoencoders (spae) for face recognition across poses. In CVPR, pages 1883–1890, 2014. |
| 208 | A sparse many-to-one encoder by setting frontal face and multiple random faces as the target values. | Y. Zhang, M. Shao, E. K. Wong, and Y. Fu. Random faces guided sparse many-to-one encoder for pose-invariant face recognition. In ICCV, pages 2416–2423. IEEE, 2013. | |
| 189 | a novel recurrent convolutional encoder-decoder network com- bined with shared identity units and recurrent pose units can render rotated objects instructed by control signals at each time step. | J. Yang, S. E. Reed, M.-H. Yang, and H. Lee. Weakly-supervised disentangling with recurrent transformations for 3d view synthesis. In NIPS, pages 1099–1107, 2015. | |
| CNN | 219 | Extracted face identity-preserving features to reconstruct face images in the canonical view using a CNN that consists of a feature extraction module and a frontal face reconstruction module. | Z. Zhu, P. Luo, X. Wang, and X. Tang. Deep learning identitypreserving face space. In ICCV, pages 113–120. IEEE, 2013. |
| 221 | Selected canonical-view images according to the face images’ symmetry and sharpness and then adopted a CNN to recover the frontal view images by minimizing the reconstruction loss error. | Z. Zhu, P. Luo, X. Wang, and X. Tang. Recover canonical-view faces in the wild with deep neural networks. arXiv preprint arXiv:1404.3543, 2014. | |
| 70 | Transformed nonfrontal face images to frontal images according to the displacement field of the pixels between them. | L. Hu, M. Kan, S. Shan, X. Song, and X. Chen. Ldf-net: Learning a displacement field network for face recognition across pose. In FG 2017, pages 9–16. IEEE, 2017. | |
| 32 | F. Cole, D. Belanger, D. Krishnan, A. Sarna, I. Mosseri, and W. T. Freeman. Synthesizing normalized faces from facial identity features. In CVPR, pages 3386–3395, 2017. | ||
| 194 | A multi-task network that can rotate an arbitrary pose and illumination image to the target-pose face image by utilizing the user’s remote code. | J. Yim, H. Jung, B. Yoo, C. Choi, D. Park, and J. Kim. Rotating your face using multi-task deep neural network. In CVPR, pages 676–684, 2015. | |
| GAN | 72 | two-pathway generative adversarial network (TP-GAN) that contains four landmark-located patch networks and a global encoder-decoder network. Through combining adversarial loss, symmetry loss and identity- preserving loss, TP-GAN generates a frontal view and simultaneously preserves global structures and local details. | R. Huang, S. Zhang, T. Li, R. He, et al. Beyond face rotation: Global and local perception gan for photorealistic and identity preserving frontal view synthesis. arXiv preprint arXiv:1704.04086, 2017. |
| 154 | disentangled representation learning generative adversarial network (DR-GAN) , an encoder produces an identity representation, and a decoder synthesizes a face at the spec- ified pose using this representation and a pose code. | L. Tran, X. Yin, and X. Liu. Disentangled representation learning gan for pose-invariant face recognition. In CVPR, volume 3, page 7, 2017. | |
| 34 | J. Deng, S. Cheng, N. Xue, Y. Zhou, and S. Zafeiriou. Uv-gan: Adversarial facial uv map completion for pose-invariant face recognition. arXiv preprint arXiv:1712.04695, 2017. | ||
| 197 | incorporated 3DMM into the GAN structure to provide shape and appearance priors to guide the generator to frontalization. | X. Yin, X. Yu, K. Sohn, X. Liu, and M. Chandraker. Towards largepose face frontalization in the wild. arXiv preprint arXiv:1704.06244, 2017. |
Deep Feature Extraction
Network Architecture

Single Network
- Typical Architectures
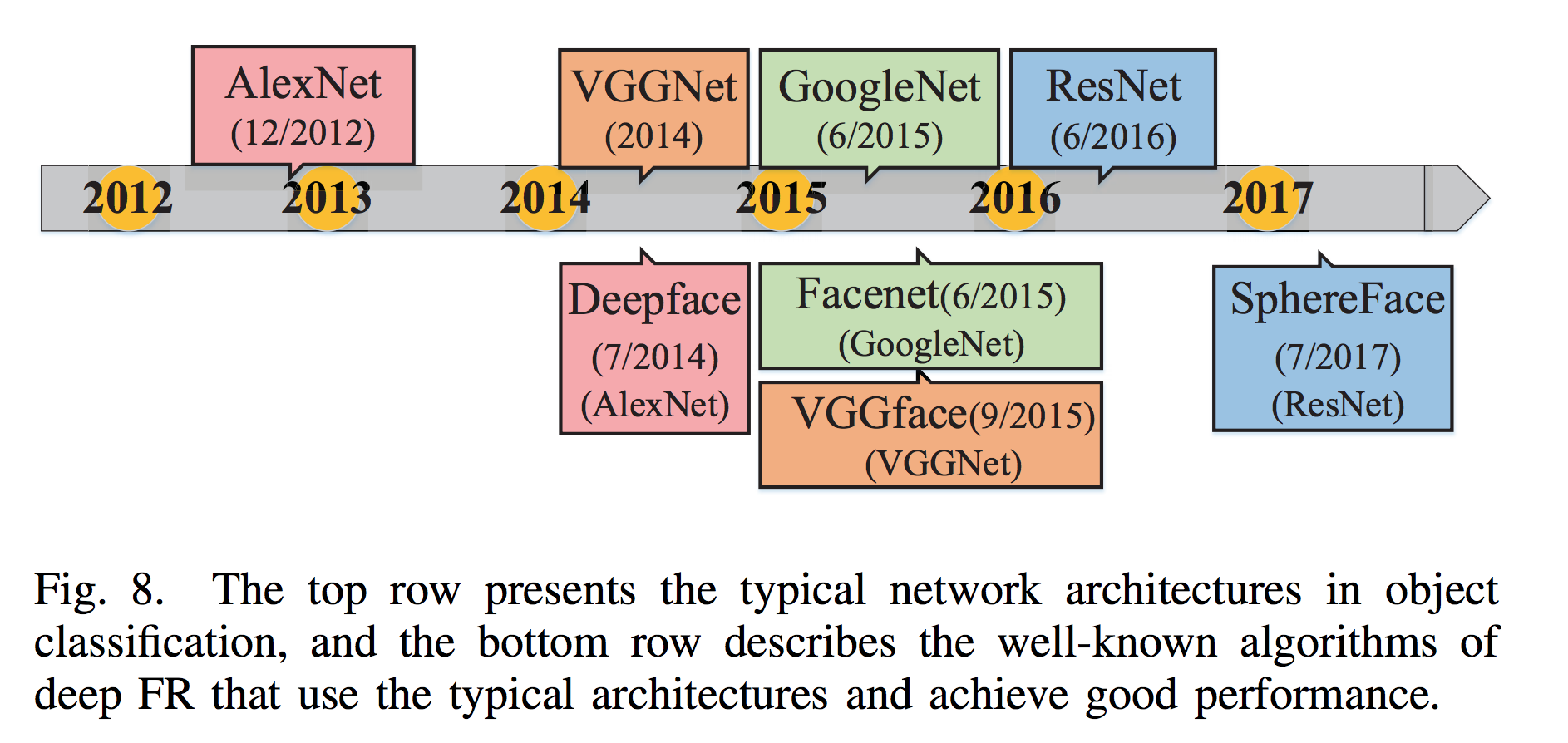
- Novel architectures
Several,看下表。
And although the light-weight CNNs for mobile devices, such as SqueezeNet, MobileNet, ShuffleNet and Xception , are still not widely used in FR, they have potential and deserve more attention.
| 思路 | id | 简介 | 论文 |
|---|---|---|---|
| AlexNet | 131 | S. Sankaranarayanan, A. Alavi, and R. Chellappa. Triplet similarity embedding for face verification. arXiv preprint arXiv:1602.03418, 2016. | |
| 130 | S. Sankaranarayanan, A. Alavi, C. D. Castillo, and R. Chellappa. Triplet probabilistic embedding for face verification and clustering. In BTAS, pages 1–8. IEEE, 2016. | ||
| 135 | F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In CVPR, pages 815– 823, 2015. | ||
| VGGNet | 115 | O. M. Parkhi, A. Vedaldi, A. Zisserman, et al. Deep face recognition. In BMVC, volume 1, page 6, 2015. | |
| 105 | I. Masi, A. T. Tr?n, T. Hassner, J. T. Leksut, and G. Medioni. Do we really need to collect millions of faces for effective face recognition? In ECCV, pages 579–596. Springer, 2016. | ||
| 205 | X. Zhang, Z. Fang, Y. Wen, Z. Li, and Y. Qiao. Range loss for deep face recognition with long-tail. arXiv preprint arXiv:1611.08976, 2016. | ||
| GoogleNet | 190 | J. Yang, P. Ren, D. Chen, F. Wen, H. Li, and G. Hua. Neural aggregation network for video face recognition. arXiv preprint arXiv:1603.05474, 2016. | |
| 135 | F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In CVPR, pages 815– 823, 2015. | ||
| ResNet | 97 | W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song. Sphereface: Deep hypersphere embedding for face recognition. In CVPR, volume 1, 2017. | |
| 205 | X. Zhang, Z. Fang, Y. Wen, Z. Li, and Y. Qiao. Range loss for deep face recognition with long-tail. arXiv preprint arXiv:1611.08976, 2016. | ||
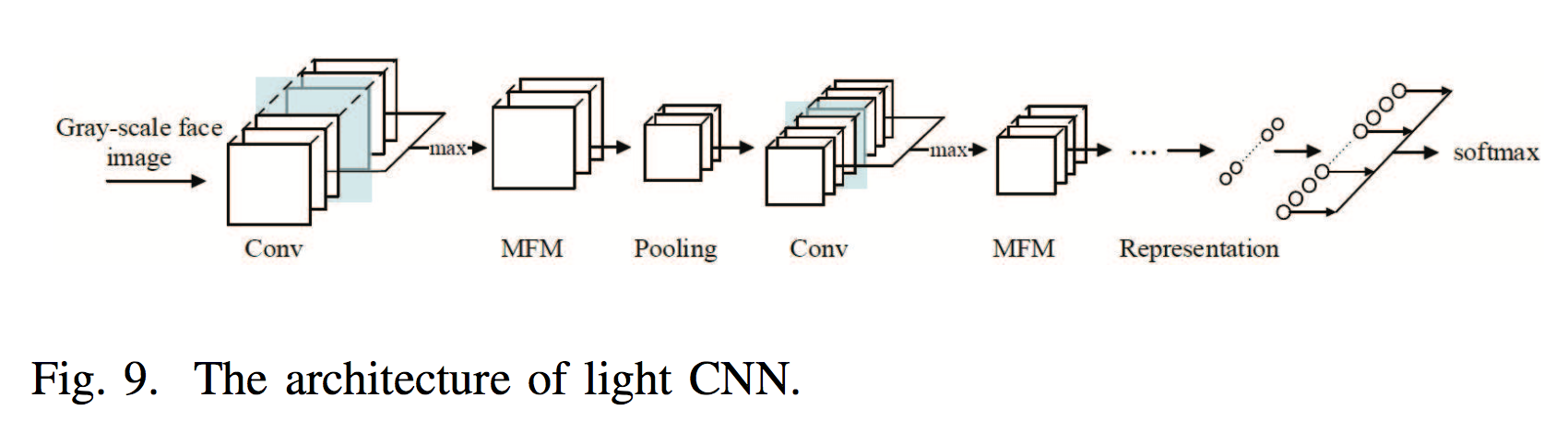
| Novel Architecture | 175 | X. Wu, R. He, and Z. Sun. A lightened cnn for deep face representation. In CVPR, volume 4, 2015. | |
| 176 | A max-feature- map (MFM) activation function that introduces the concept of maxout in the fully connected layer to CNN. The MFM obtains a compact representation and reduces the computa- tional cost. | X. Wu, R. He, Z. Sun, and T. Tan. A light cnn for deep face representation with noisy labels. arXiv preprint arXiv:1511.02683, 2015. | |
| 148 | Sparsifying deep networks iteratively from the previously learned denser models based on a weight selection criterion. | Y. Sun, X. Wang, and X. Tang. Sparsifying neural network connections for face recognition. In CVPR, pages 4856–4864, 2016. | |
| 31 | bilinear CNN (B-CNN), The outputs at each location of two CNNs are combined (using outer product) and are then average pooled to obtain the bilinear feature representation. | A. R. Chowdhury, T.-Y. Lin, S. Maji, and E. Learned-Miller. One-tomany face recognition with bilinear cnns. In WACV, pages 1–9. IEEE, 2016. | |
| 182 | Conditional convolutional neural network (c-CNN) dynamically activated sets of kernels according to modalities of samples. | C. Xiong, X. Zhao, D. Tang, K. Jayashree, S. Yan, and T.-K. Kim. Conditional convolutional neural network for modality-aware face recognition. In ICCV, pages 3667–3675. IEEE, 2015. |
Multiple Networks
- Multi-input Networks
对应 one-to-many augmentation (generate multiple images of different patches or poses),multiple networks for different image inputs。 - Multi-task Learning Networks
Identity classification is the main task, and the side tasks are pose, illumination, and expression estimations, among others.
In these networks, the lower layers are shared among all the tasks, and the higher layers are disentangled into multiple networks to generate the task-specific outputs.
| 思路 | id | 简介 | 论文 |
|---|---|---|---|
| multipose | 79 | multi-view deep network (MvDN) consists of view-specific subnetworks and common sub- networks; the former removes view-specific variations, and the latter obtains common representations. | M. Kan, S. Shan, and X. Chen. Multi-view deep network for cross-view classification. In CVPR, pages 4847–4855, 2016. |
| 104 | Adjusted the pose to frontal (0◦), half-profile (40◦) and full-profile views (75◦) and then addressed pose variation by multiple pose networks. | I. Masi, S. Rawls, G. Medioni, and P. Natarajan. Pose-aware face recognition in the wild. In CVPR, pages 4838–4846, 2016. | |
| 196 | Automatically assigning the dynamic loss weights for each side task. | X. Yin and X. Liu. Multi-task convolutional neural network for poseinvariant face recognition. TIP, 2017. | |
| 165 | Coupled SAE for cross-view FR. | W. Wang, Z. Cui, H. Chang, S. Shan, and X. Chen. Deeply coupled auto-encoder networks for cross-view classification. arXiv preprint arXiv:1402.2031, 2014. | |
| multipatch | 96 | J. Liu, Y. Deng, T. Bai, Z. Wei, and C. Huang. Targeting ultimate accuracy: Face recognition via deep embedding. arXiv preprint arXiv:1506.07310, 2015. | |
| 217 | E. Zhou, Z. Cao, and Q. Yin. Naive-deep face recognition: Touching the limit of lfw benchmark or not? arXiv preprint arXiv:1501.04690, 2015. | ||
| 43 | C. Ding and D. Tao. Robust face recognition via multimodal deep face representation. IEEE Transactions on Multimedia, 17(11):2049–2058, 2015. | ||
| 146 | Y. Sun, X. Wang, and X. Tang. Hybrid deep learning for face verification. In ICCV, pages 1489–1496. IEEE, 2013. | ||
| 147 | Y. Sun, X. Wang, and X. Tang. Deep learning face representation from predicting 10,000 classes. In CVPR, pages 1891–1898, 2014. | ||
| 143 | Y. Sun, Y. Chen, X. Wang, and X. Tang. Deep learning face representation by joint identification-verification. In NIPS, pages 1988– 1996, 2014. | ||
| 173 | W.-S. T. WST. Deeply learned face representations are sparse, selective, and robust. perception, 31:411–438, 2008. | ||
| multitask | 122 | The task-specific subnetworks are branched out to learn face detection, face alignment, pose estimation, gender recognition, smile detection, age estimation and FR. | R. Ranjan, S. Sankaranarayanan, C. D. Castillo, and R. Chellappa. An all-in-one convolutional neural network for face analysis. In FG 2017, pages 17–24. IEEE, 2017. |
Loss Function

Euclidean-distance-based loss
- Contrastive Loss
训练时不太稳定,和 sample 选取有关。
Require face image pairs, pulls together positive pairs and pushes apart negative pairs.
时间线:[173], [143], [144], [148], [192] - Triplet Loss
训练时不太稳定,和 sample 选取有关。
Require the face triplets, and then it minimizes the distance between an anchor and a positive sample of the same identity and maximizes the distance between the anchor and a negative sample of a different identity. 还有一些是先用 softmax 训练,然后再用 triplet loss fine-tune。
时间线:[135], [115], [130], [131], [96], [43]
(1):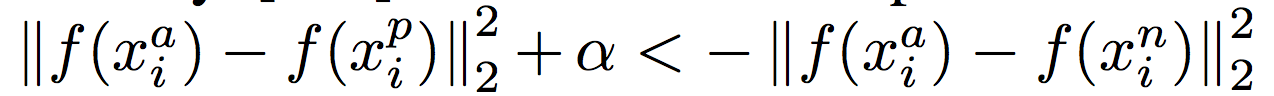
是 anchor, positive, negative samples。是 margin。是 nonlinear transformation embedding an image into a feature space.
(2):
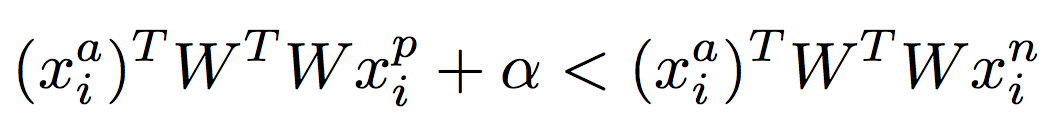
(3):
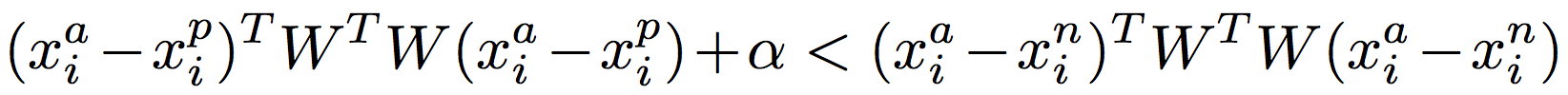
- Center Loss
[170]; [205], [36], [179].
The center loss learned a center for each class and penalized the distances between the deep features and their corresponding class centers.
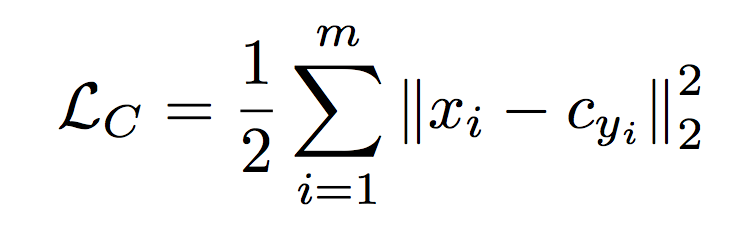
是第 i 个 deep feature,属于第 个类别,是其 deep feature 的中心。
| id | 简介 | 论文 |
|---|---|---|
| 143 | Increased the dimension of hidden representations and added supervision to early convolutional layers | Y. Sun, Y. Chen, X. Wang, and X. Tang. Deep learning face representation by joint identification-verification. In NIPS, pages 1988– 1996, 2014. |
| 173 | Combined the face identification and verification supervisory signals to learn a discriminative representation, and joint Bayesian (JB) was applied to obtain a robust embedding space. | W.-S. T. WST. Deeply learned face representations are sparse, selective, and robust. perception, 31:411–438, 2008. |
| 144 | Further introduced VGGNet and GoogleNet | Y. Sun, D. Liang, X. Wang, and X. Tang. Deepid3: Face recognition with very deep neural networks. arXiv preprint arXiv:1502.00873, 2015. |
| 170 | The center loss learned a center for each class and penalized the distances between the deep features and their corresponding class centers. | Y. Wen, K. Zhang, Z. Li, and Y. Qiao. A discriminative feature learning approach for deep face recognition. In ECCV, pages 499–515. Springer, 2016. |
| 179 | A center-invariant loss that penalizes the difference between each center of classes. | Y. Wu, H. Liu, J. Li, and Y. Fu. Deep face recognition with center invariant loss. In Proceedings of the on Thematic Workshops of ACM Multimedia 2017, pages 408–414. ACM, 2017. |
| 205 | Used a range loss to minimize k greatest range’s harmonic mean values in one class and maximize the shortest inter-class distance within one batch . | X. Zhang, Z. Fang, Y. Wen, Z. Li, and Y. Qiao. Range loss for deep face recognition with long-tail. arXiv preprint arXiv:1611.08976, 2016. |
| 135 | First introduced triplet loss to deep FR using hard triplet face samples. 公式(1) | F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In CVPR, pages 815– 823, 2015. |
| 115 | O. M. Parkhi, A. Vedaldi, A. Zisserman, et al. Deep face recognition. In BMVC, volume 1, page 6, 2015. | |
| 131 | learned a linear projection W to construct triplet loss. 公式(3) | S. Sankaranarayanan, A. Alavi, and R. Chellappa. Triplet similarity embedding for face verification. arXiv preprint arXiv:1602.03418, 2016. |
| 130 | learned a linear projection W to construct triplet loss. 公式(2) | S. Sankaranarayanan, A. Alavi, C. D. Castillo, and R. Chellappa. Triplet probabilistic embedding for face verification and clustering. In BTAS, pages 1–8. IEEE, 2016. |
| 96 | J. Liu, Y. Deng, T. Bai, Z. Wei, and C. Huang. Targeting ultimate accuracy: Face recognition via deep embedding. arXiv preprint arXiv:1506.07310, 2015. | |
| 25 | J.-C. Chen, V. M. Patel, and R. Chellappa. Unconstrained face verification using deep cnn features. In WACV, pages 1–9. IEEE, 2016. | |
| 192 | D. Yi, Z. Lei, S. Liao, and S. Z. Li. Learning face representation from scratch. arXiv preprint arXiv:1411.7923, 2014. | |
| 43 | C. Ding and D. Tao. Robust face recognition via multimodal deep face representation. IEEE Transactions on Multimedia, 17(11):2049–2058, 2015. | |
| 36 | Selected the farthest intra-class samples and the nearest inter- class samples to compute a margin loss. | J. Deng, Y. Zhou, and S. Zafeiriou. Marginal loss for deep face recognition. In CVPR Workshops, volume 4, 2017. |
angular/cosine-margin-based loss
Angular/cosine- margin-based loss makes learned features potentially separable with a larger angular/cosine distance.
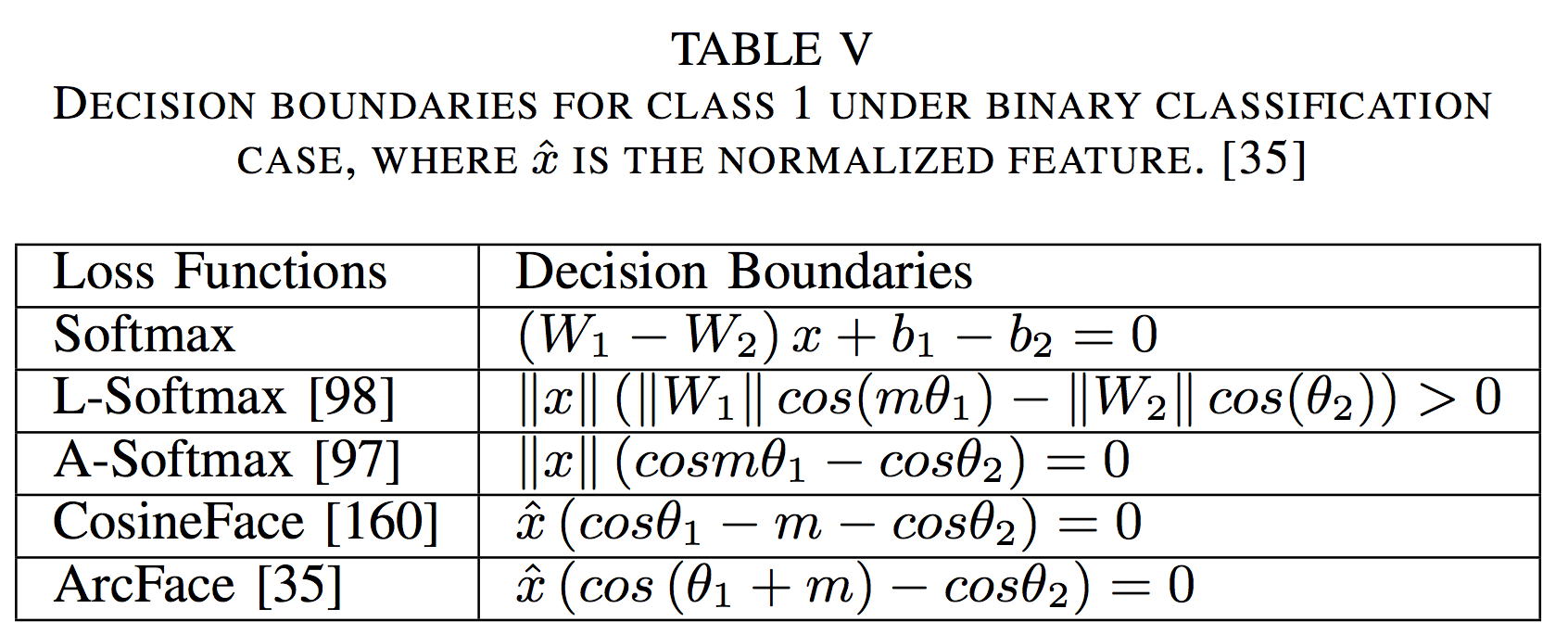
todo
- Large-margin Softmax (L-Softmax) Loss:
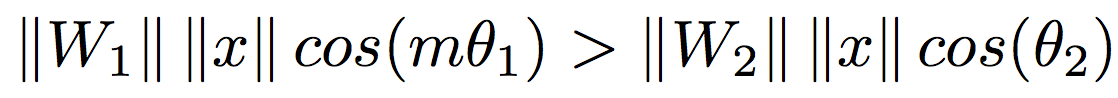
是正数表示 angular margin, 是 the weight of the last fully connected layer, 是 deep feature, 是 deep feature 之间的角度。
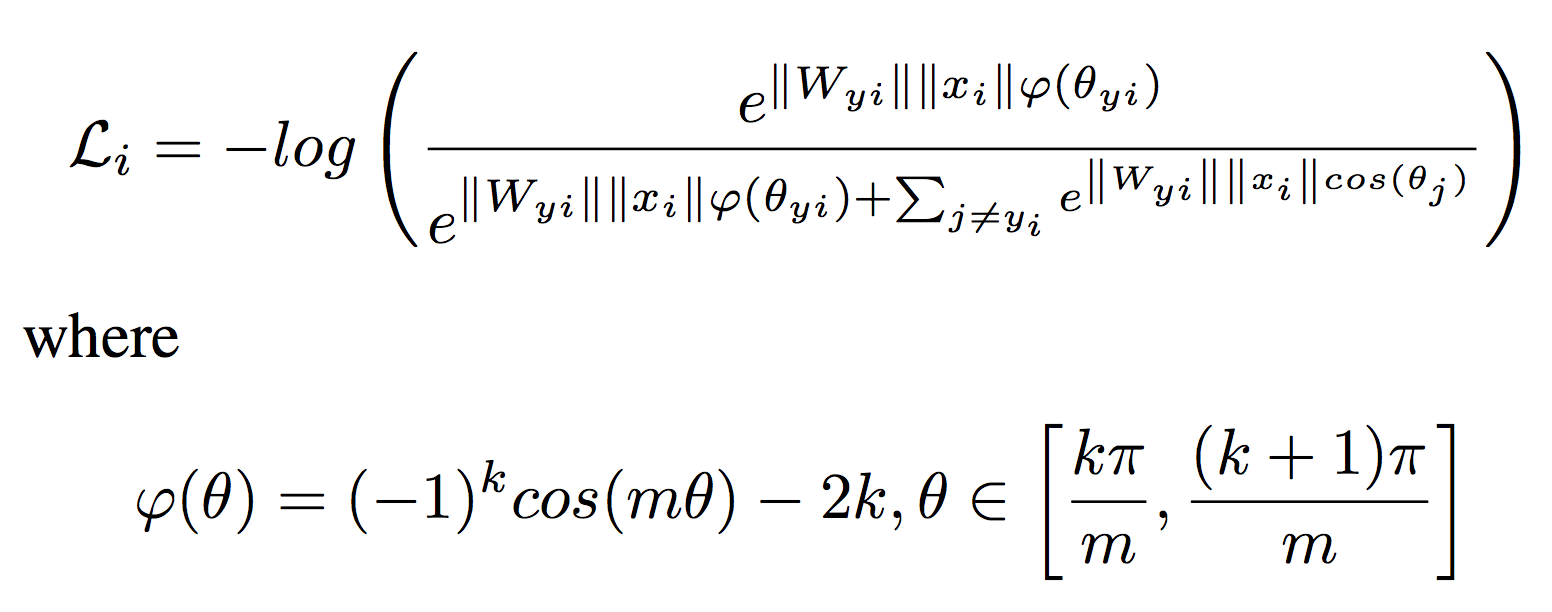
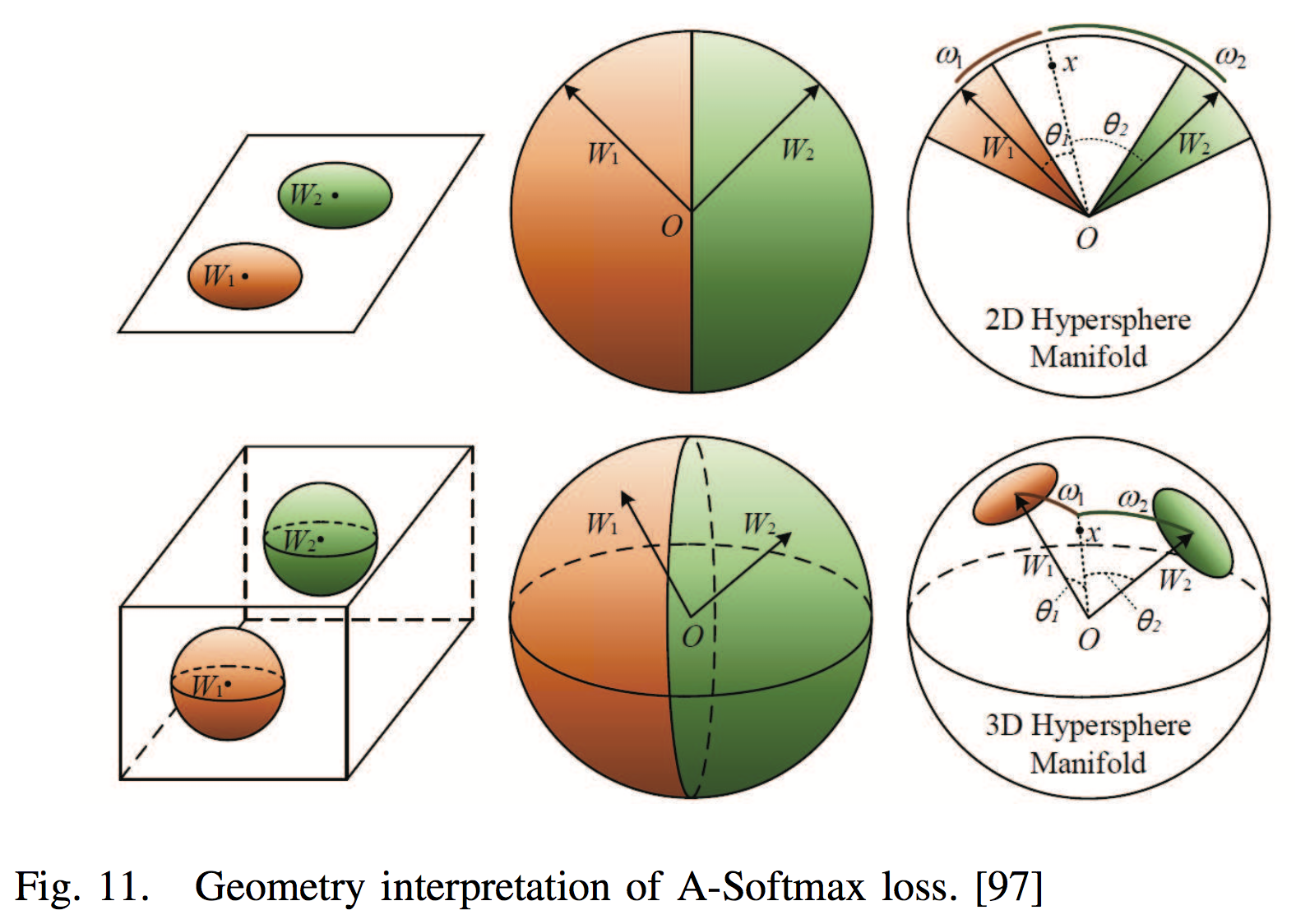
- A-Softmax Loss
Based on L-Softmax,further normalized the weight W by its L2 norm such that the normalized vector will lie on a hypersphere, and then the discriminative face features can be learned on a hypersphere manifold with an angular margin.
- Additive angular/consine Margin and 。todo
| id | 简介 | 论文 |
|---|---|---|
| 98 | W. Liu, Y. Wen, Z. Yu, and M. Yang. Large-margin softmax loss for convolutional neural networks. In ICML, pages 507–516, 2016. | |
| 97 | W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song. Sphereface: Deep hypersphere embedding for face recognition. In CVPR, volume 1, 2017. | |
| 160 | F. Wang, W. Liu, H. Liu, and J. Cheng. Additive margin softmax for face verification. arXiv preprint arXiv:1801.05599, 2018. | |
| 35 | J. Deng, J. Guo, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. arXiv preprint arXiv:1801.07698, 2018. | |
| 162 | H. Wang, Y. Wang, Z. Zhou, X. Ji, Z. Li, D. Gong, J. Zhou, and W. Liu. Cosface: Large margin cosine loss for deep face recognition. arXiv preprint arXiv:1801.09414, 2018. | |
| 99 | a deep hy- perspherical convolution network (SphereNet) that adopts hy- perspherical convolution as its basic convolution operator and is supervised by angular-margin-based loss. | W. Liu, Y.-M. Zhang, X. Li, Z. Yu, B. Dai, T. Zhao, and L. Song. Deep hyperspherical learning. In NIPS, pages 3953–3963, 2017. |
softmax loss and its variations
- weight normalization + feature normalization

[97], [160], [35], [99], normalize weights only and trained with angular/cosine margin to make the learned features be discriminative.
[120], [57], adopted feature normalization only to overcome the bias to the sample distribution of the softmax.
[161], [101], [58], normalize both features and weights. - others
[20] proposed a noisy softmax to mitigate early saturation by injecting annealed noise in softmax.
| id | 简介 | 论文 |
|---|---|---|
| 120 | enforced all the features to have the same L2-norm by feature normalization such that similar attention is given to good quality frontal faces and blurry faces with extreme pose. | R. Ranjan, C. D. Castillo, and R. Chellappa. L2-constrained softmax loss for discriminative face verification. arXiv preprint arXiv:1703.09507, 2017. |
| 161 | F. Wang, X. Xiang, J. Cheng, and A. L. Yuille. Normface: l 2 hypersphere embedding for face verification. arXiv preprint arXiv:1704.06369, 2017. | |
| 57 | Normalize features with and | A. Hasnat, J. Bohne, J. Milgram, S. Gentric, and L. Chen. Deepvisage: ´ Making face recognition simple yet with powerful generalization skills. arXiv preprint arXiv:1703.08388, 2017. |
| 101 | After normalizing features and weights, optimized the cosine distance among data features. | Y. Liu, H. Li, and X. Wang. Rethinking feature discrimination and polymerization for large-scale recognition. arXiv preprint arXiv:1710.00870, 2017. |
| 119 | X. Qi and L. Zhang. Face recognition via centralized coordinate learning. arXiv preprint arXiv:1801.05678, 2018. | |
| 20 | noisy softmax. | B. Chen, W. Deng, and J. Du. Noisy softmax: improving the generalization ability of dcnn via postponing the early softmax saturation. arXiv preprint arXiv:1708.03769, 2017. |
| 58 | used the von Mises-Fisher (vMF) mixture model as the theoretical basis to develop a novel vMF mixture loss and its corresponding vMF deep features. | M. Hasnat, J. Bohne, J. Milgram, S. Gentric, L. Chen, et al. von ´ mises-fisher mixture model-based deep learning: Application to face verification. arXiv preprint arXiv:1706.04264, 2017. |
Similarity Comparison
image -> deep feature representation
计算 feature 之间的 cosine distance 或 L2 distance,然后用 nearest neighbor 或 threshold comparison,用于 identification 或 verification task。
对 deep feature 还可以有一些预处理,比如 metric learning, sparse-representation-based classifier (SRC) 等。
- [22] JB model

- [158] first used product quantization (PQ) [76] to directly retrieve the top-k most similar faces and re-ranked these faces by combining similarities from deep features and the COTS matcher [51].
- In [191], Yang et al. extracted the local adaptive convolution features from the local regions of the face image and used the extended SRC for FR with a single sample per person.
- [53] combined deep features and the SVM classifier to recognize all the classes.
Databases of Face Recognition
增加数据可以提高 FR 的表现。
Real-World Scenes

Cross-factor FR
Problem: Variations caused by people themselves.
Method: image synthetic, domain adaptation, separating cross factors from identity.
Cross-Pose Face Recognition
| Attempts |
|---|
| [16] first attempt to perform frontalization in the deep feature space but not in the image space. A deep residual equivariant mapping (DREAM) block dynamically adds residuals to an input representation to transform a profile face to a frontal image. |
| [24] proposed combining feature ex- traction with multi-view subspace learning to simultaneously make features be more pose robust and discriminative. |
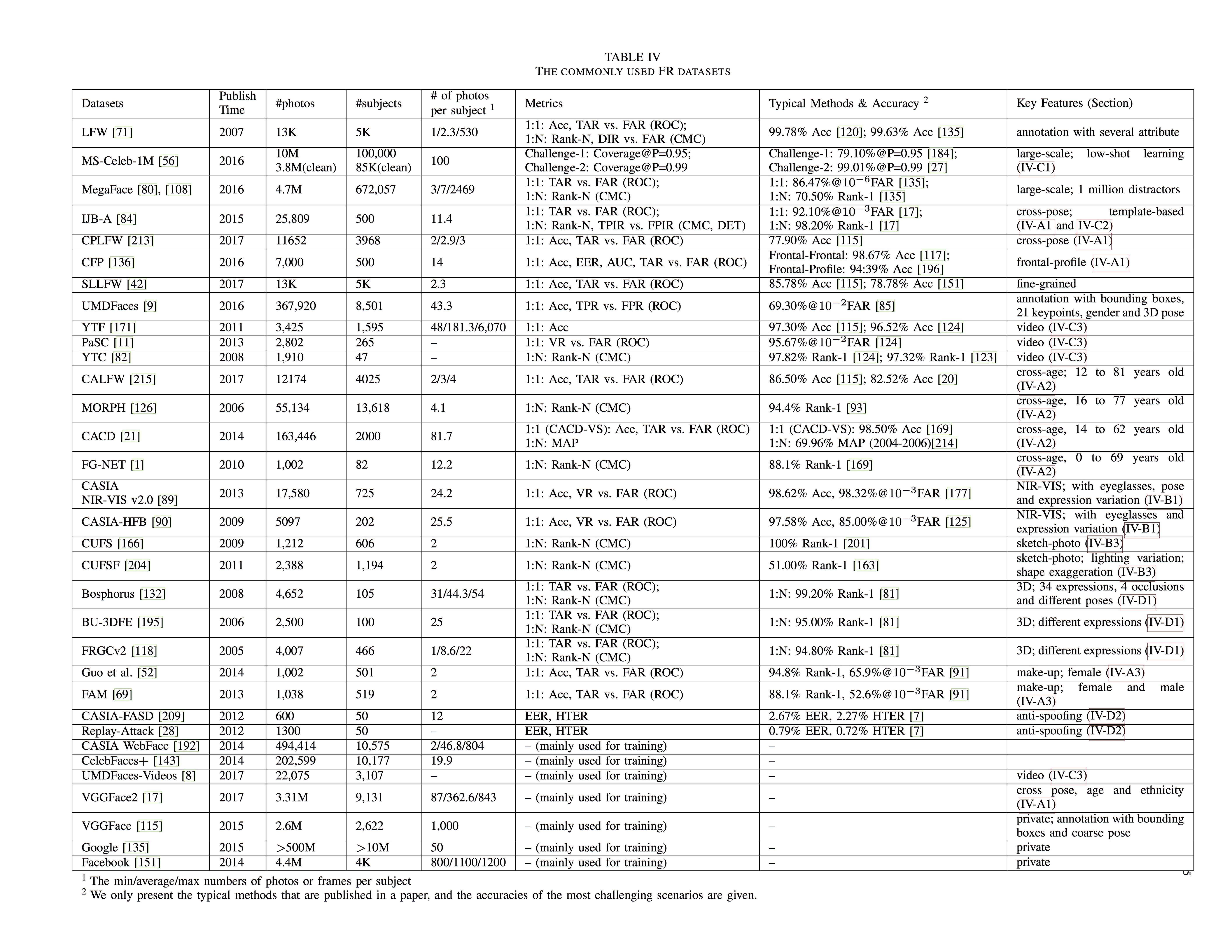
Cross-Age Face Recognition
- One direct approach is to synthesize the input image to the target age.
| Attempts |
|---|
| A generative probabilistic model was used by [46] to model the facial aging process at each short-term stage. |
| Antipov et al. [6] proposed aging faces by GAN, but the synthetic faces cannot be directly used for face verification due to its imperfect preservation of identities. |
| Then, [5] used a local manifold adaptation (LMA) approach to solve the problem of [6]. |
- An alternative is to decompose aging/identity components separately and extract age-invariant representations.
| Attempts |
|---|
| [169] developed a latent identity analysis (LIA) layer to separate the two components. |
| In [214], age-invariant features were obtained by subtracting age- specific factors from the representations with the help of the age estimation task. |
- other methods
| Attempts |
|---|
| [12], [47] fine-tuned the CNN to transfer knowledge. |
| [167] proposed a siamese deep network of multi-task learning of FR and age estimation. |
| [92] integrated feature extraction and metric learning via a deep CNN. |
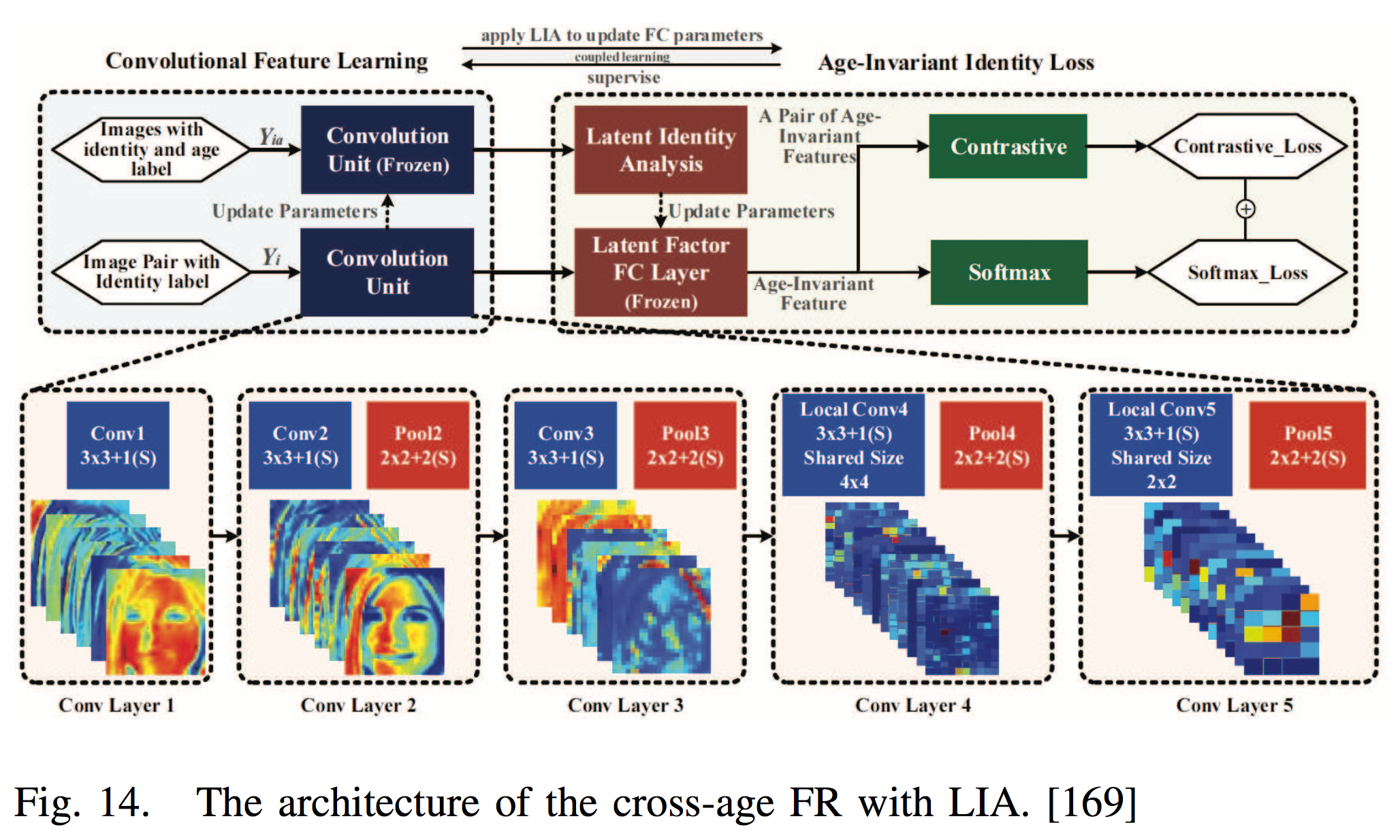
Makeup Face Recognition
| Attempts |
|---|
| [91] generated nonmakeup images from makeup ones by a bi-level adversarial network (BLAN) and then used the synthesized nonmakeup images for verification. |
| [145] pretrained a triplet network on the free videos and fine- tuned it on small makeup and nonmakeup datasets. |
Heterogenous FR
Problem: Matching faces across different visual domains. Domain gap caused by sensory devices and cameras settings.
Method: Domain adaptation, image synthetic.
NIR-VIS Face Recognition
Near-infrared spectrum NIS images, low-light scenarios, used in surveillance systems. 与其他 Visible light (VIS) spectrum images 不一样。
| Attempts |
|---|
| [133] [100] transferred the VIS deep networks to the NIR domain by fine-tuning. |
| [87] used a VIS CNN to recognize NIR faces by transforming NIR images to VIS faces through cross-spectral hallucination and restoring a low-rank structure for features through low-rank embedding. |
| [125] trained two networks, a VISNet (for visible images) and a NIRNet (for near-infrared images), and coupled their output features by creating a siamese network. |
| [62], [63] divided the high layer of the network into a NIR layer, a VIS layer and a NIR-VIS shared layer; then, a modality-invariant feature can be learned by the NIR-VIS shared layer. |
| [142] embedded cross-spectral face hallucination and discriminative feature learning into an end- to-end adversarial network. |
| In [177], the low-rank relevance and cross-modal ranking were used to alleviate the semantic gap. |
Low-Resolution Face Recognition
[198] proposed a CNN with a two-branch architecture (a super-resolution network and a feature extraction network) to map the high- and low- resolution face images into a common space where the intra- person distance is smaller than the inter-person distance.
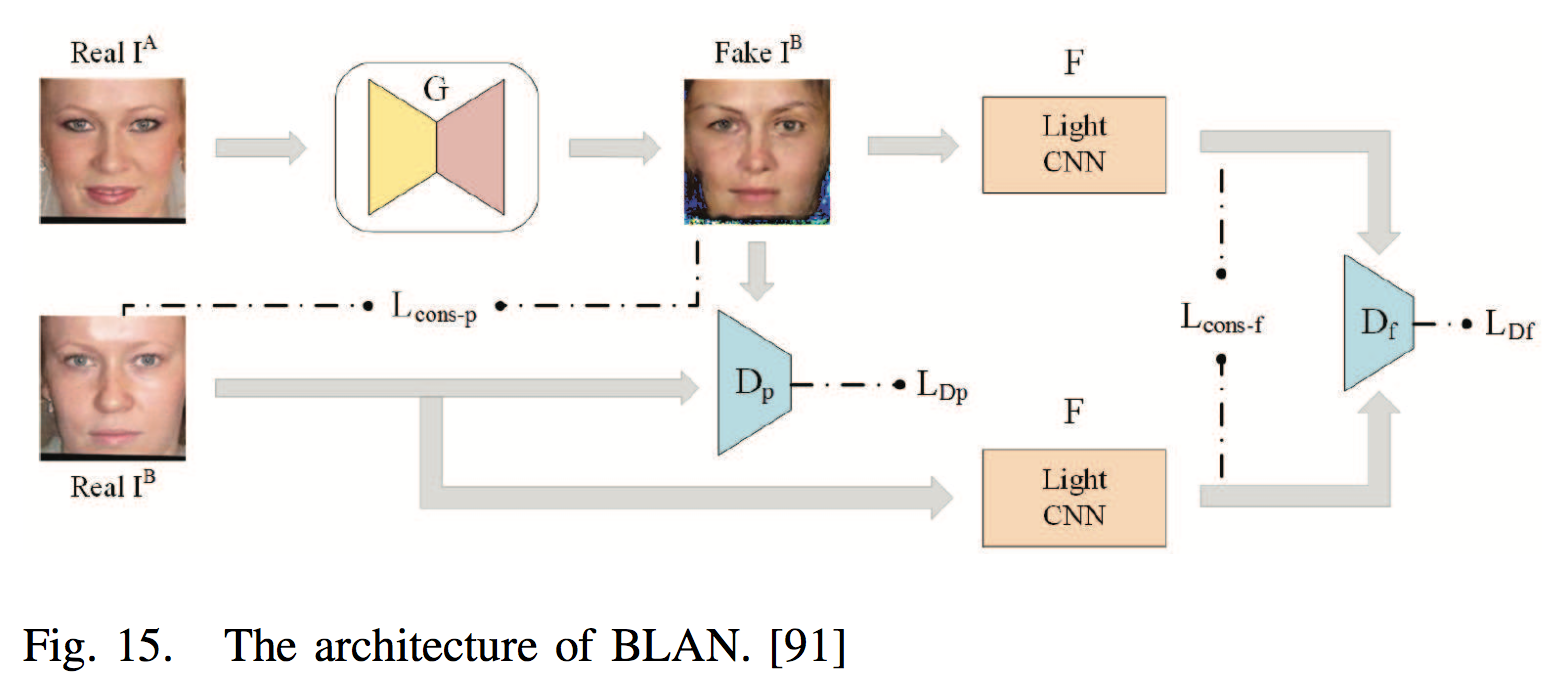
Photo-Sketch Face Recognition
The photo-sketch FR may help law enforcement to quickly identify suspects.
- Method 1, utilize transfer learning to directly match photos to sketches, where the deep networks are first trained using a large face database of photos and are then fine-tuned using small sketch database [106], [48].
- Method 2, to use the image-to-image translation, where the photo can be transformed to a sketch or the sketch to a photo; then, FR can be performed in one domain.
| Attempts |
|---|
| [201] developed a fully con- volutional network with generative loss and a discriminative regularizer to transform photos to sketches. |
| [199] utilized a branched fully convolutional neural network (BFCN) to generate a structure-preserved sketch and a texture-preserved sketch, and then they fused them together via a probabilistic method. |
| GAN, [193], [83], [218] used two generators, GA and GB, to generate sketches from photos and photos from sketches, respectively. |
| Based on [218], [163] proposed a multi-adversarial network to avoid artifacts by leveraging the implicit presence of feature maps of different resolutions in the generator subnetwork. |
Multiple (or single) media FR
Low-Shot Face Recognition
Training sample 很少时。
- Enlarging the training data.
- Learning more powerful features.
| Attempts |
|---|
| [66] generated images in various poses using a 3D face model and adopted deep domain adaptation to handle the other variations, such as blur, occlusion, and expression. |
| [29] used data augmentation methods and a GAN for pose transition and attribute boosting to increase the size of the training dataset. |
| [178] proposed a framework with hybrid classifiers using a CNN and a nearest neighbor (NN) model. |
| [55] made the norms of the weight vectors of the one-shot classes and the normal classes aligned to address the data imbalance problem. |
| [27] proposed an enforced softmax that contains optimal dropout, selective attenuation, L2 normalization and model-level optimization. |
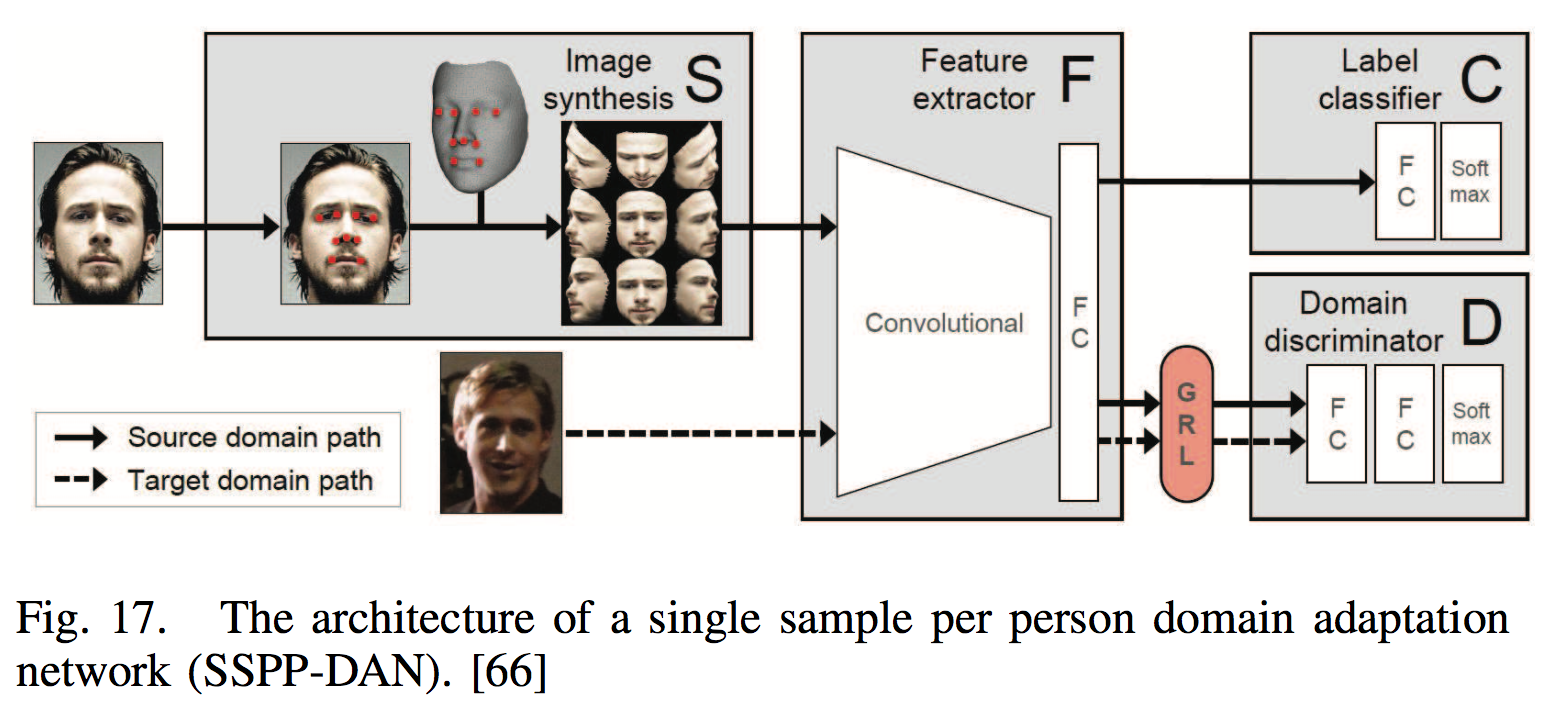
Set/Template-Based Face Recognition
Set/template- based FR problems assume that both probe and gallery sets are represented using a set of media, e.g., images and videos, rather than just one. After learning a set of face representations from each medium individually, two strategies are generally adopted for face recognition between sets.
- One is to use these representations for similarity comparison between the media in two sets and pool the results into a single, final score, such as max score pooling [104], average score pooling [102] and its variations [210], [14].
- The other strategy is to aggregate face representations through average or max pooling and generate a single representation for each set and then perform a comparison between two sets, which we call feature pooling [104], [25], [130].
- Others
For example, [59] proposed a deep heterogeneous feature fusion network to exploit the features’ complementary information generated by different CNNs.
Video Face Recognition
Two key issues:
- Integrate the information across different frames together to build a representation of the video face.
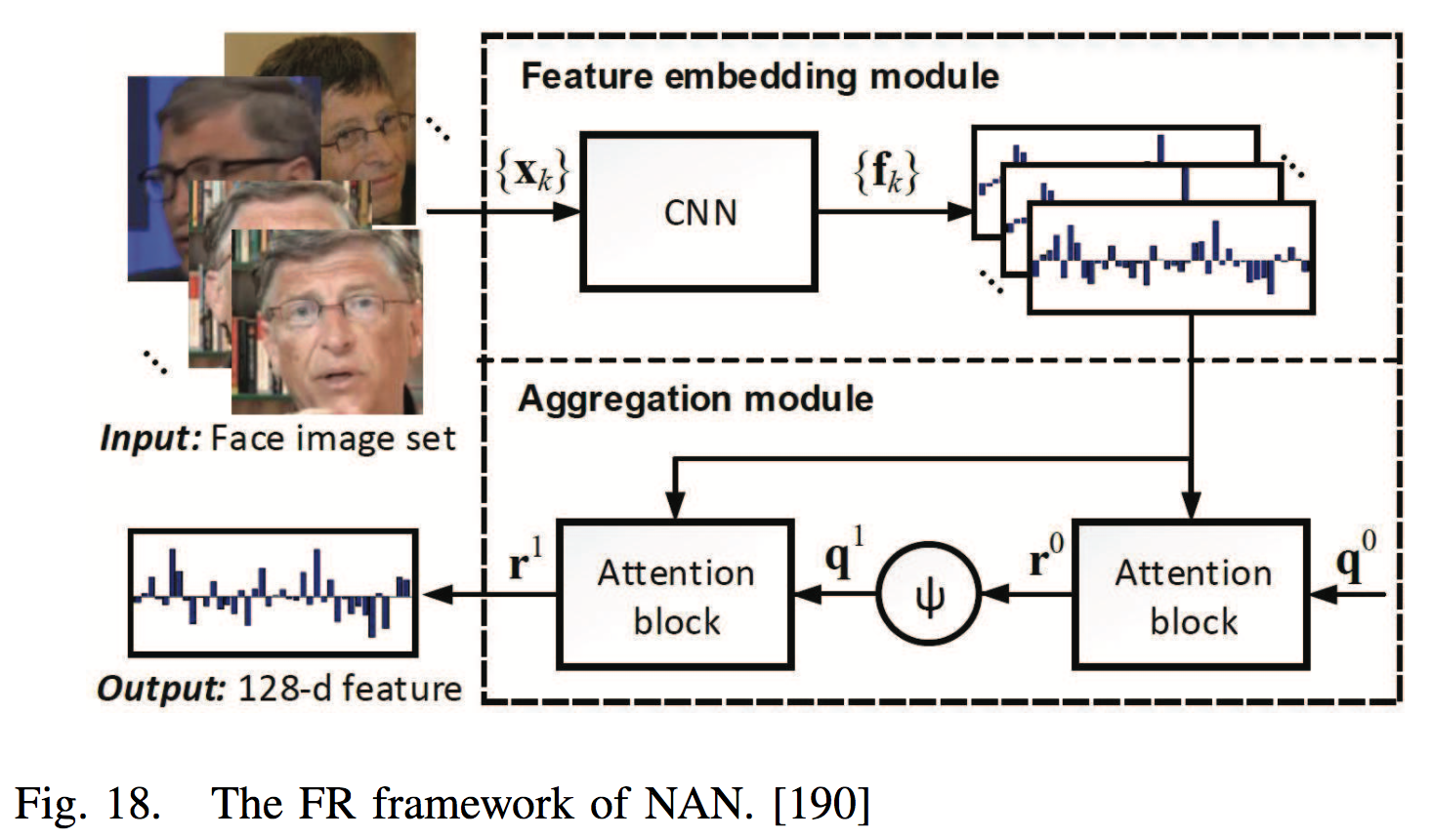
[190] proposed a neural aggregation network (NAN) in which the aggregation module, consisting of two attention blocks driven by a memory, produces a 128-dimensional vector representation.
Rao et al. [123] aggregated raw video frames directly by combining the idea of metric learning and adversarial learning. - Handle video frames with severe blur, pose variations, and occlusions.
[124] discarded the bad frames by treating this operation as a Markov decision process and trained the attention model through a deep reinforcement learning framework.
[44] artificially blurred clear still images for training to learn blur-robust face representations.
[113] used a CNN to reconstruct a lower-quality video into a high-quality face.
FR in industry
除了accuracy 仍需考虑 anti-spoofing, high efficiency。
3D Face Recognition
没有 large annotated 3D data.
- Use the methods of “one-to-many augmentation” to synthesize 3D faces.
- 还需探索。
[81] fine-tuned a 2D CNN with a small amount of 3D scans for 3D FR.
[223] used a three- channel (corresponding to depth, azimuth and elevation angles of the normal vector) image as input and minimized the average prediction log-loss.
[200] selected 30 feature points from the Candide-3 face model to characterize faces and then conducted the unsupervised pretraining of face depth data and the supervised fine-tuning.
Face Anti-spoofing
Various types of spoofing attacks, such as print attacks, replay attacks, and 3D mask attacks, are becoming a large threat.
[7] proposed a novel two-stream CNN in which the local features discriminate the spoof patches independent of the spatial face areas, and holistic depth maps ensure that the input live sample has a face-like depth.
[188] trained a CNN using both a single frame and multiple frames with five scales, and the live/spoof label is assigned as the output.
[185] proposed a long short- term memory (LSTM)-CNN architecture that learns temporal features to jointly predict for multiple frames of a video.
[88], [116] fine-tuned their networks from a pretrained model by training sets of real and fake images.
Face Recognition for Mobile Devices
运算能力。
[73], [67], [30], [207] proposed lightweight deep networks, and these networks have potential to be introduced into FR.
[150] proposed a multibatch method that first generates signatures for a minibatch of k face images and then constructs an unbiased estimate of the full gradient by relying on all k^2 − k pairs from the minibatch.
Ref:
[1] https://arxiv.org/pdf/1804.06655.pdf
Paper References:




