Bagging 与 Random Forest
欲得到泛化性能强的集成,集成中的个体学习器应尽可能相互独立,其中一种做法就是训练样本采样出不同子集用于训练不同基学习器。但是,每个基学习器也不能太差,如果采样出的每个子集都完全不同,数据太少不足以有效学习,所以考虑使用相互有交叠的采样子集。
Bagging
Introduction
并行式集成学习的代表。
自助采样法,给定包含 m 个样本的数据集,先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时,该样本仍有可能被选中。这样经过 m 次随机采样操作,我们得到含 m 个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的从未出现。
基于这些采样集分别训练出基学习器,再将他们结合。分类任务常用投票法,回归任务用平均法。

由于每个基学习器只用了一部分样本,剩下的样本可用作验证集来对泛化性能进行包外估计,out-of-bag estimate。此外,包外样本还有许多其他用途。当基学习器是决策树时,可使用包外样本来辅助剪枝,或用于估计决策树中各节点的后验概率以辅助对零训练样本节点的处理;当基学习器是神经网络时,可使用包外样本来辅助早期停止以减少过拟合风险。
从偏差-方差的角度看,Bagging 主要关注降低方差,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效用更为明显。
Parameters that control bagging
- Changing the seed.
- Row (Sub) sampling or Bootstrapping.
- Shuffling.
- Column (Sub) sampling.
- Model-specific parameters.
- Number of models (or bags).
- (Optionally) parallelism.
Examples of Bagging
BaggingClassifier and BaggingRegressor from Sklearn.
1 | # train is the training data |
Random Forest
是 Bagging 的一个扩展变体。RF 在以决策树为基学习器构建 Bagging 集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
即样本是子集,属性集也是子集。两者都要扰动。
使用 k 控制随机性的引入程度,k=d 则和传统决策树相同,k=1则是随机选择一个属性用于划分,一般情况下推荐值 k=log2d。
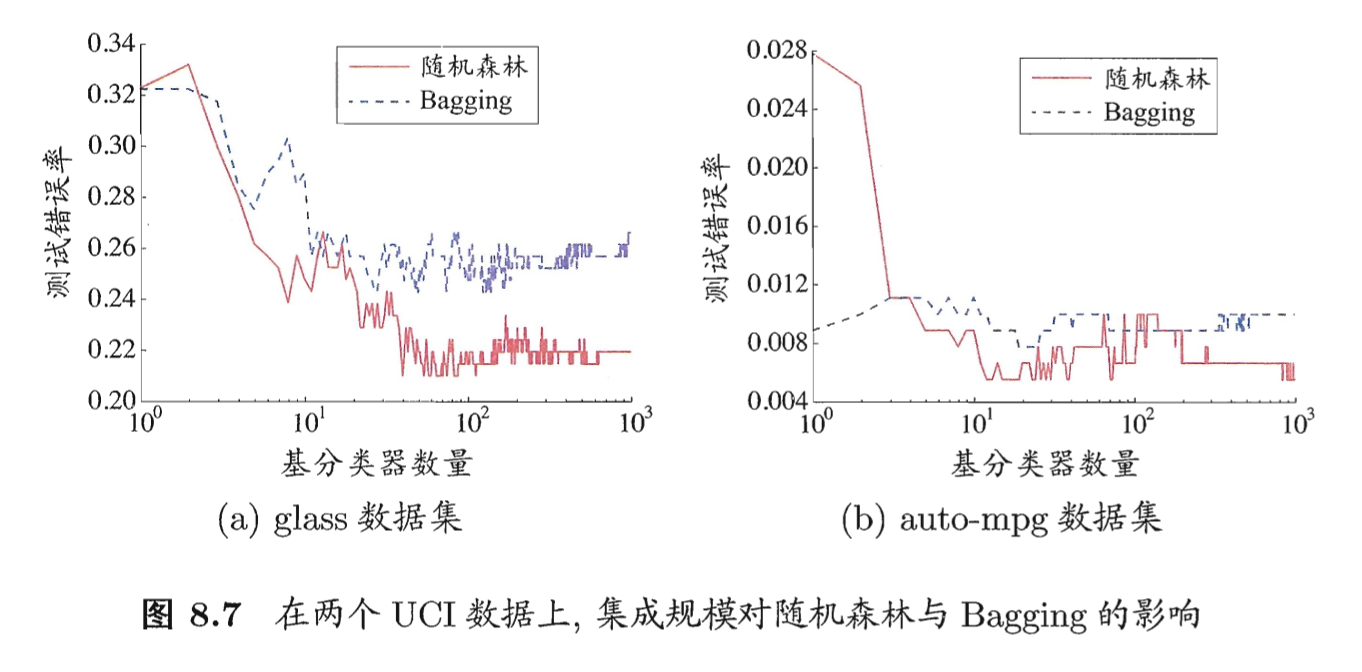
随机森林的起始性能往往比较差,因为属性扰动让随机森林中的个体学习器的性能进一步降低。随着个体学习器数目增加,随机森林通常会收敛到更低的泛化误差,效率也更高。
Ref
[1] 机器学习 - 周志华
[2] Coursera - How to Win a Data Scieance Competition