Natural Language Processing with Python 笔记
网上能找到的pdf格式中英文版均基于Python2.5,NLTK现已更新支持Python3.0,最新书籍英文版参看这里。还有Errata。

Preface
Software Requirements
- Python
The material presented in this book assumes that you are using Python version 3.2 or later. (Note that NLTK 3.0 also works with Python 2.6 and 2.7.) - NLTK
The code examples in this book use NLTK version 3.0. Subsequent releases of NLTK will be backward-compatible with NLTK 3.0. - NLTK-Data
This contains the linguistic corpora that are analyzed and processed in the book. - NumPy
(recommended) This is a scientific computing library with support for multidimensional arrays and linear algebra, required for certain probability, tagging, clustering, and classification tasks. - Matplotlib
(recommended) This is a 2D plotting library for data visualization, and is used in some of the book’s code samples that produce line graphs and bar charts. - Stanford NLP Tools:
(recommended) NLTK includes interfaces to the Stanford NLP Tools which are useful for large scale language processing (see http://nlp.stanford.edu/software/). - NetworkX
(optional) This is a library for storing and manipulating network structures consisting of nodes and edges. For visualizing semantic networks, also install the Graphviz library. - Prover9
(optional) This is an automated theorem prover for first-order and equational logic, used to support inference in language processing.
Natural Language Toolkit (NLTK)
| Language processing task | NLTK modules | Functionality |
|---|---|---|
| Accessing corpora | corpus | standardized interfaces to corpora and lexicons |
| String processing | tokenize, stem | tokenizers, sentence tokenizers, stemmers |
| Collocation discovery | collocations | t-test, chi-squared, point-wise mutual information |
| Part-of-speech tagging | tag | n-gram, backoff, Brill, HMM, TnT |
| Machine learning | classify, cluster, tbl | decision tree, maximum entropy, naive Bayes, EM, k-means |
| Chunking | chunk | regular expression, n-gram, named-entity |
| Parsing | parse, ccg | chart, feature-based, unification, probabilistic, dependency |
| Semantic interpretation | sem, inference | lambda calculus, first-order logic, model checking |
| Evaluation metrics | metrics | precision, recall, agreement coefficients |
| Probability and estimation | probability | frequency distributions, smoothed probability distributions |
| Applications | app, chat | graphical concordancer, parsers, WordNet browser, chatbots |
| Linguistic fieldwork | toolbox | manipulate data in SIL Toolbox format |
Language Processing and Python
本章要解决的问题:
- What can we achieve by combining simple programming techniques with large quantities of text?
- How can we automatically extract key words and phrases that sum up the style and content of a text?
- What tools and techniques does the Python programming language provide for such work?
- What are some of the interesting challenges of natural language processing?
在Ubuntu里设置时可能的坑
为了用新例子,更改Ubuntu的默认Python版本为3.2以上的版本。
1 | # 安装pyenv |
此时nltk等包需安装在Python指定版本下。用python -m pip install nltk。
如果不能正常使用IDLE,提示"IDLE can’t import Tkinter. Your python may not be configured for Tk."。使用以下方法:
- First uninstall Python 3.5.1 :
pyenv uninstall 3.5.1, then - Run
sudo apt-get install tk-dev - And reinstall Python 3.5.1 :
pyenv install 3.5.1
Computing with Language: Texts and Words
Token: technical name for a sequence of characters that we want to treat as a group.
Word Type: the form or spelling of the word independently of its specific occurrences in a text. i.e. the word considered as a unique item of vocabulary.
1 | # import nltk module |
A Closer Look at Python: Texts as Lists of Words
基础Python3语法复习。
官方Python文档。
注意这里index从0开始。
Computing with Language: Simple Statistics
Hapaxes: words that occur only once.
Collocation: a sequence of words that occur together unusually often.
Bigrams: a list of word pairs.
Frequency Distributions
1 | # find frequency distribution in text |
Fine-grained Selection of Words
1 | # find the words that are longer than seven characters that occur more than 7 times |
Collocations and Bigrams
1 | # find bigrams |
Counting Other Things
1 | # the distribution of word lengths in a text |
Functions Defined for NLTK’s Frequency Distributions
| Example | Description |
|---|---|
| fdist = FreqDist(samples) | create a frequency distribution containing the given samples |
| fdist[sample] += 1 | increment the count for this sample |
| fdist[‘monstrous’] | count of the number of times a given sample occurred |
| fdist.freq(‘monstrous’) | frequency of a given sample |
| fdist.N() | total number of samples |
| fdist.most_common(n) | the n most common samples and their frequencies |
| for sample in fdist: | iterate over the samples |
| fdist.max() | sample with the greatest count |
| fdist.tabulate() | tabulate the frequency distribution |
| fdist.plot() | graphical plot of the frequency distribution |
| fdist.plot(cumulative=True) | cumulative plot of the frequency distribution |
| fdist1 ¦= fdist2 | update fdist1 with counts from fdist2 |
| fdist1 < fdist2 | test if samples in fdist1 occur less frequently than in fdist2 |
Back to Python: Making Decisions and Taking Control
Some Word Comparison Operators
| Function | Meaning |
|---|---|
| s.startswith(t) | test if s starts with t |
| s.endswith(t) | test if s ends with t |
| t in s | test if t is a substring of s |
| s.islower() | test if s contains cased characters and all are lowercase |
| s.isupper() | test if s contains cased characters and all are uppercase |
| s.isalpha() | test if s is non-empty and all characters in s are alphabetic |
| s.isalnum() | test if s is non-empty and all characters in s are alphanumeric |
| s.isdigit() | test if s is non-empty and all characters in s are digits |
| s.istitle() | test if s contains cased characters and is titlecased (i.e. all words in s have initial capitals) |
1 | sorted(wd for wd in set(text3) if wd.istitle() and len(wd) > 10) |
Automatic Natural Language Understanding
Word Sense Disambiguation
Nearby words have closely related meanings.
Example:
a. The lost children were found by the searchers (agentive — Chesterton was the author of the book)
b. The lost children were found by the mountain (locative — the stove is where the cup is)
c. The lost children were found by the afternoon (temporal — Friday is the time of the submitting)
Pronoun Resolution
Who did what to whom.
Example:
a. The thieves stole the paintings. They were subsequently sold.
b. The thieves stole the paintings. They were subsequently caught.
c. The thieves stole the paintings. They were subsequently found.
They到底指代谁。
Anaphora Resolution: identifying what a pronoun or noun phrase refers to.
Semantic Role Labeling: identifying how a noun phrase relates to the verb.
Generating Language Output
Question Answering and Machine Translation
a. Text: … The thieves stole the paintings. They were subsequently sold. …
b. Human: Who or what was sold?
c. Machine: The paintings.
翻译成法语,指thief时用男性,指painting时用女性。
a. The thieves stole the paintings. They were subsequently found.
b. Les voleurs ont volé les peintures. Ils ont été trouvés plus tard. (the thieves)
c. Les voleurs ont volé les peintures. Elles ont été trouvées plus tard. (the paintings)
Machine Translation
把一个句子翻译过去又翻译回来就可以看到翻译系统的不足。
0> how long before the next flight to Alice Springs?
1> wie lang vor dem folgenden Flug zu Alice Springs?
2> how long before the following flight to Alice jump?
3> wie lang vor dem folgenden Flug zu Alice springen Sie?
4> how long before the following flight to Alice do you jump?
5> wie lang, bevor der folgende Flug zu Alice tun, Sie springen?
6> how long, before the following flight to Alice does, do you jump?
7> wie lang bevor der folgende Flug zu Alice tut, tun Sie springen?
8> how long before the following flight to Alice does, do you jump?
9> wie lang, bevor der folgende Flug zu Alice tut, tun Sie springen?
10> how long, before the following flight does to Alice, do do you jump?
11> wie lang bevor der folgende Flug zu Alice tut, Sie tun Sprung?
12> how long before the following flight does leap to Alice, does you?
Text Alignment: pair up the sentences of different languages.
Spoken Dialog Systems
Turing Test: can a dialogue system, responding to a user’s text input, perform so natually that we cannot distinguish it from a human-generated response?
nltk.chat.chatbots()来感受一下分分钟起无名火的聊天系统。
Textual Entailment
Recognizing Textual Entailment (RTE)分析某段文字能否为某论点提供论证。
a. Text: David Golinkin is the editor or author of eighteen books, and over 150 responsa, articles, sermons and books
b. Hypothesis: Golinkin has written eighteen books
需要做如下论证:
(i) if someone is an author of a book, then he/she has written that book; (ii) if someone is an editor of a book, then he/she has not written (all of) that book; (iii) if someone is editor or author of eighteen books, then one cannot conclude that he/she is author of eighteen books.
Limitations of NLP
An important goal of NLP research has been to make progress on the difficult task of building technologies that “understand language,” using superficial yet powerful techniques instead of unrestricted knowledge and reasoning capabilities.
Accessing Text Corpora and Lexical Resources
本章要解决的问题:
- What are some useful text corpora and lexical resources, and how can we access them with Python?
- Which Python constructs are most helpful for this work?
- How do we avoid repeating ourselves when writing Python code?
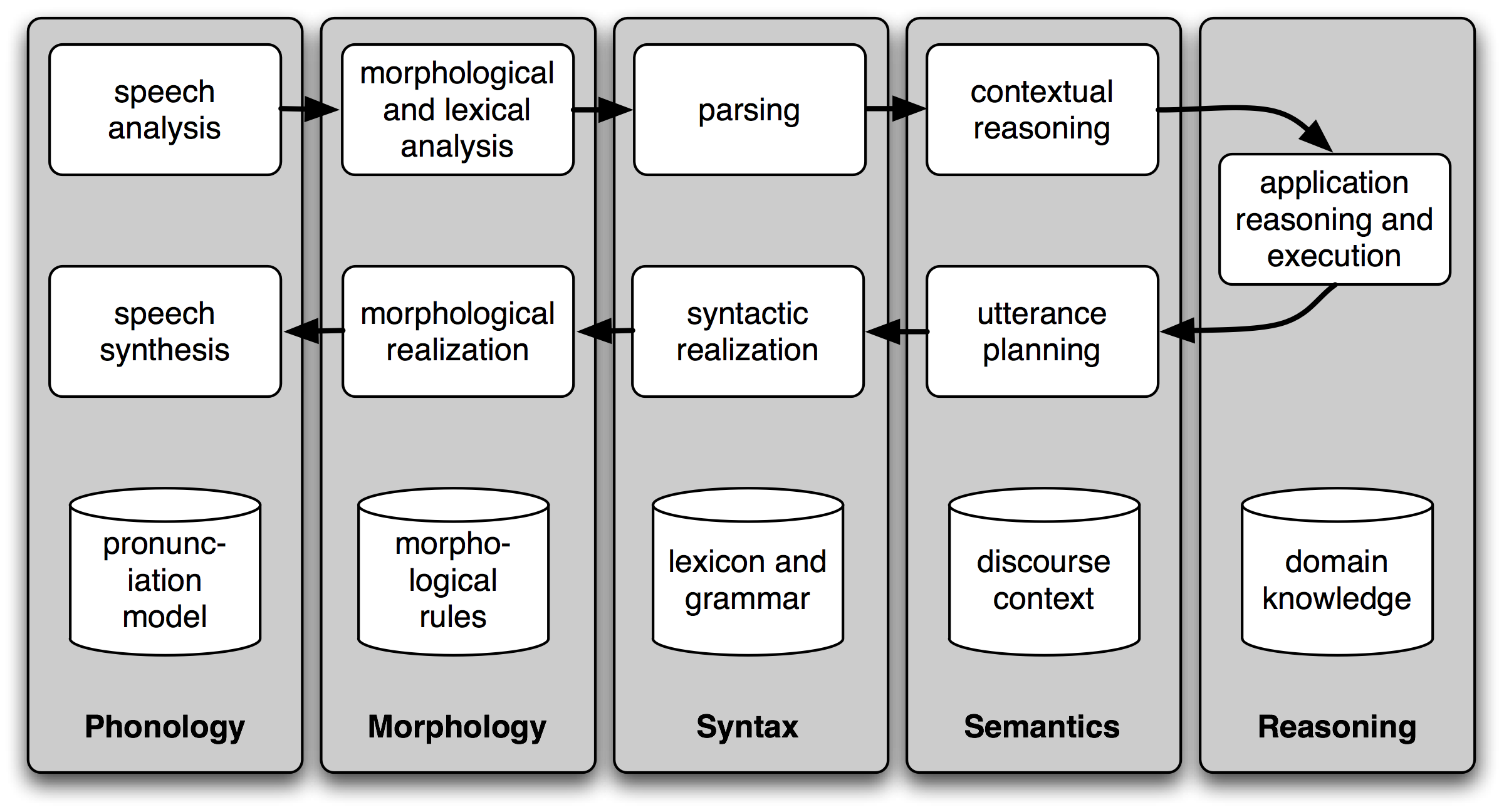
Copora: large bodied of linguistic data.
Accessing Text Corpora
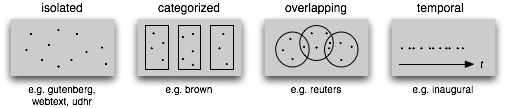
Corporas
Gutenberg Corpus
contains some 25,000 free electronic books, hosted at http://www.gutenberg.org/.
1 | from nltk.corpus import gutenberg |
1 | ''' |
1 | # sents() divides the text up into its sentences |
words(),raw(),sents()之外还有更多操作,以后再讲。
Web and Chat Text
content from a Firefox discussion forum, conversations overheard in New York, the movie script of Pirates of the Carribean, personal advertisements, wine reviews.
1 | from nltk.corpus import webtext |
instant messaging chat sessions.
1 | from nltk.corpus import nps_chat |
Brown Corpus
first million-word electronic corpus of English, sources categorized by genre.
genre的完整列表见http://icame.uib.no/brown/bcm-los.html。
1 | # compare genres in their usage of modal verbs |
Reuters Corpus
classified into 90 topics, grouped into “training” and “test”.
1 | # categories overlap with each other |
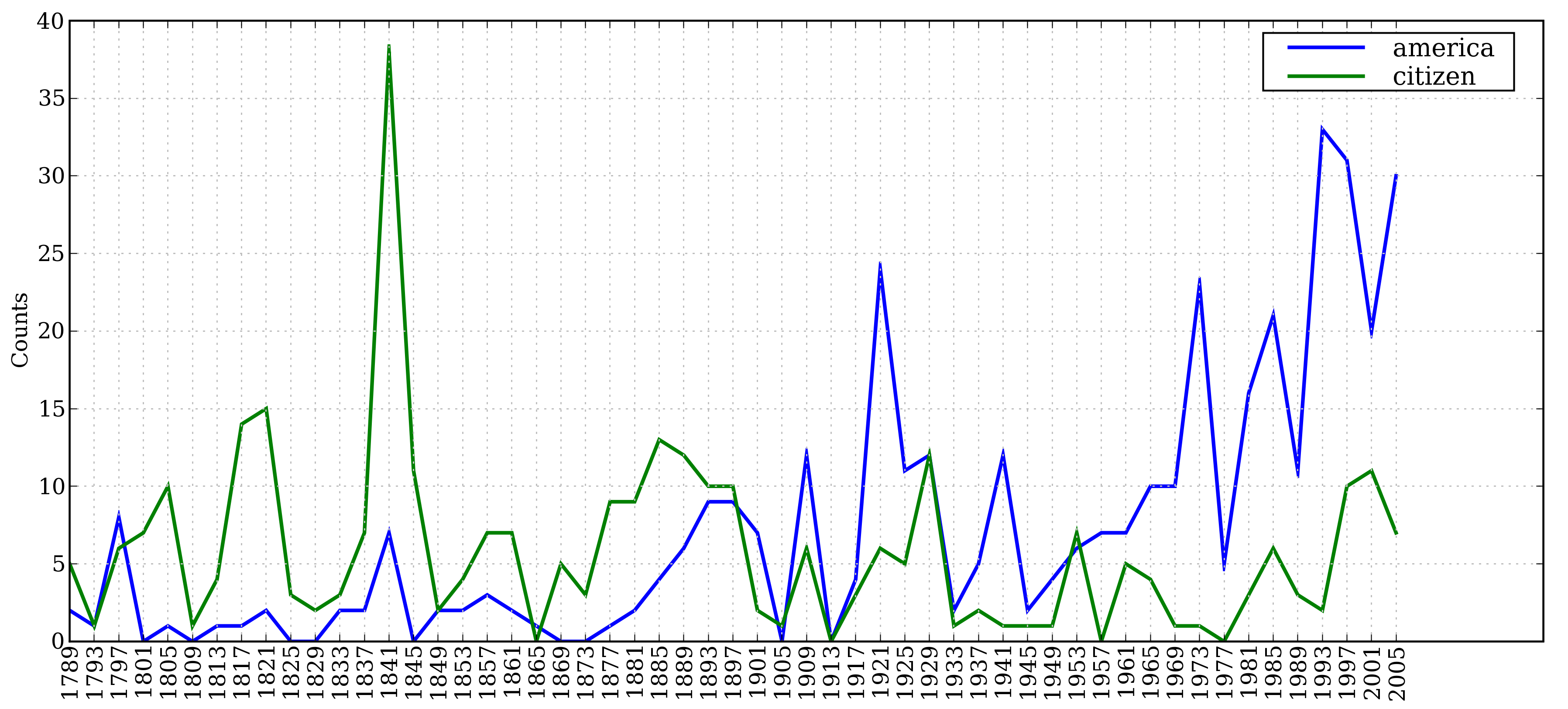
Inaugural Address Corpus
a collection of 55 texts.
1 | # get the year of each text |
Annotated Text Corpora
contain linguistic annotations, representing POS tags, named entities, syntactic structures, semantic roles, and so forth.
For information about downloading them, see http://nltk.org/data. For more examples of how to access NLTK corpora, please consult the Corpus HOWTO at http://nltk.org/howto.
Some of the Corpora and Corpus Samples Distributed with NLTK
| Corpus | Compiler | Contents |
|---|---|---|
| Brown Corpus | Francis, Kucera | 15 genres, 1.15M words, tagged, categorized |
| CESS Treebanks | CLiC-UB | 1M words, tagged and parsed (Catalan, Spanish) |
| Chat-80 Data Files | Pereira & Warren | World Geographic Database |
| CMU Pronouncing Dictionary | CMU | 127k entries |
| CoNLL 2000 Chunking Data | CoNLL | 270k words, tagged and chunked |
| CoNLL 2002 Named Entity | CoNLL | 700k words, pos- and named-entity-tagged (Dutch, Spanish) |
| CoNLL 2007 Dependency Treebanks (sel) | CoNLL | 150k words, dependency parsed (Basque, Catalan) |
| Dependency Treebank | Narad | Dependency parsed version of Penn Treebank sample |
| FrameNet | Fillmore, Baker et al | 10k word senses, 170k manually annotated sentences |
| Floresta Treebank | Diana Santos et al | 9k sentences, tagged and parsed (Portuguese) |
| Gazetteer Lists | Various | Lists of cities and countries |
| Genesis Corpus | Misc web sources | 6 texts, 200k words, 6 languages |
| Gutenberg (selections) | Hart, Newby, et al | 18 texts, 2M words |
| Inaugural Address Corpus | CSpan | US Presidential Inaugural Addresses (1789-present) |
| Indian POS-Tagged Corpus | Kumaran et al | 60k words, tagged (Bangla, Hindi, Marathi, Telugu) |
| MacMorpho Corpus | NILC, USP, Brazil | 1M words, tagged (Brazilian Portuguese) |
| Movie Reviews | Pang, Lee | 2k movie reviews with sentiment polarity classification |
| Names Corpus | Kantrowitz, Ross | 8k male and female names |
| NIST 1999 Info Extr (selections) | Garofolo | 63k words, newswire and named-entity SGML markup |
| Nombank | Meyers | 115k propositions, 1400 noun frames |
| NPS Chat Corpus | Forsyth, Martell | 10k IM chat posts, POS-tagged and dialogue-act tagged |
| Open Multilingual WordNet | Bond et al | 15 languages, aligned to English WordNet |
| PP Attachment Corpus | Ratnaparkhi | 28k prepositional phrases, tagged as noun or verb modifiers |
| Proposition Bank | Palmer | 113k propositions, 3300 verb frames |
| Question Classification | Li, Roth | 6k questions, categorized |
| Reuters Corpus | Reuters | 1.3M words, 10k news documents, categorized |
| Roget’s Thesaurus | Project Gutenberg | 200k words, formatted text |
| RTE Textual Entailment | Dagan et al | 8k sentence pairs, categorized |
| SEMCOR | Rus, Mihalcea | 880k words, part-of-speech and sense tagged |
| Senseval 2 Corpus | Pedersen | 600k words, part-of-speech and sense tagged |
| SentiWordNet | Esuli, Sebastiani | sentiment scores for 145k WordNet synonym sets |
| Shakespeare texts (selections) | Bosak | 8 books in XML format |
| State of the Union Corpus | CSPAN | 485k words, formatted text |
| Stopwords Corpus | Porter et al | 2,400 stopwords for 11 languages |
| Swadesh Corpus | Wiktionary | comparative wordlists in 24 languages |
| Switchboard Corpus (selections) | LDC | 36 phonecalls, transcribed, parsed |
| Univ Decl of Human Rights | United Nations | 480k words, 300+ languages |
| Penn Treebank (selections) | LDC | 40k words, tagged and parsed |
| TIMIT Corpus (selections) | NIST/LDC | audio files and transcripts for 16 speakers |
| VerbNet 2.1 | Palmer et al | 5k verbs, hierarchically organized, linked to WordNet |
| Wordlist Corpus | OpenOffice.org et al | 960k words and 20k affixes for 8 languages |
| WordNet 3.0 (English) | Miller, Fellbaum | 145k synonym sets |
Corpora in Other Languages
1 | nltk.corpus.cess_esp.words() |
Text Corpus Structure
Corpus Functionality
Basic Corpus Functionality defined in NLTK [More]
| Example | Description |
|---|---|
| fileids() | the files of the corpus |
| fileids([categories]) | the files of the corpus corresponding to these categories |
| categories() | the categories of the corpus |
| categories([fileids]) | the categories of the corpus corresponding to these files |
| raw() | the raw content of the corpus |
| raw(fileids=[f1,f2,f3]) | the raw content of the specified files |
| raw(categories=[c1,c2]) | the raw content of the specified categories |
| words() | the words of the whole corpus |
| words(fileids=[f1,f2,f3]) | the words of the specified fileids |
| words(categories=[c1,c2]) | the words of the specified categories |
| sents() | the sentences of the whole corpus |
| sents(fileids=[f1,f2,f3]) | the sentences of the specified fileids |
| sents(categories=[c1,c2]) | the sentences of the specified categories |
| abspath(fileid) | the location of the given file on disk |
| encoding(fileid) | the encoding of the file (if known) |
| open(fileid) | open a stream for reading the given corpus file |
| root | if the path to the root of locally installed corpus |
| readme() | the contents of the README file of the corpus |
corpus readers can be used to work with new corpora.
Loading your own Corpus
Use NLTK’s PlaintextCorpusReader.
Set file location as the value of corpus_root.
1 | from nltk.corpus import PlaintextCorpusReader |
1 | from nltk.corpus import BracketParseCorpusReader |
Conditional Frequency Distributions
Conditions and Events
A conditional frequency distribution needs to pair each event with a condition, so we will process a sequence of pairs with the form (condition, event).
Counting Words by Genre
1 | from nltk.corpus import brown |
Plotting and Tabulating Distributions
1 | # 前文america和citizen在不同年份词频图 |
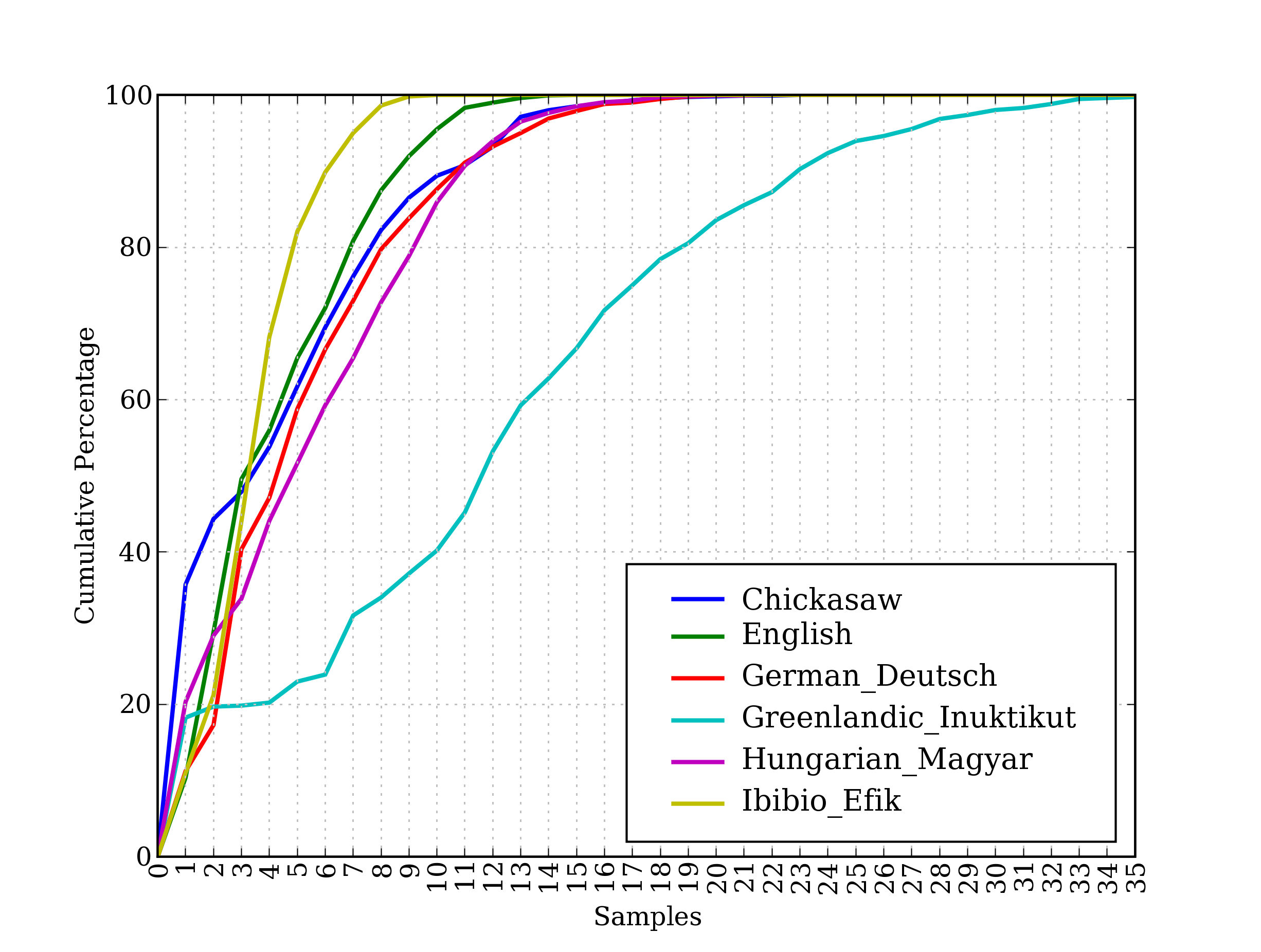
1 | # 前文不同语言词汇数图 |
还可以看前文Brown Corpus那里的例子。
Generating Random Text with Bigrams
1 | def generate_model(cfdist, word, num=15): |
NLTK’s Conditional Frequency Distributions
commonly-used methods and idioms for defining, accessing, and visualizing a conditional frequency distribution of counters.
| Example | Description |
|---|---|
| cfdist = ConditionalFreqDist(pairs) | create a conditional frequency distribution from a list of pairs |
| cfdist.conditions() | the conditions |
| cfdist[condition] | the frequency distribution for this condition |
| cfdist[condition][sample] | frequency for the given sample for this condition |
| cfdist.tabulate() | tabulate the conditional frequency distribution |
| cfdist.tabulate(samples, conditions) | tabulation limited to the specified samples and conditions |
| cfdist.plot() | graphical plot of the conditional frequency distribution |
| cfdist.plot(samples, conditions) | graphical plot limited to the specified samples and conditions |
| cfdist1 < cfdist2 | test if samples in cfdist1 occur less frequently than in cfdist2 |
More Python: Reusing Code
text editors and Python functions.
Creating Programs with a Text Editor
IDLE -> File Menu -> New File
Run Menu -> Run Module or from test import *
Functions
1 | def plural(word): |
Modules
1 | from text_proc import plural |
Lexical Resources
Lexicon(or Lexical Resource): a collection of words and/or phrases along with associated information such as part of speech and sense definitions.
A lexical entry consists of a headword (also known as a lemma) along with additional information such as the part of speech and the sense definition. Two distinct words having the same spelling are called homonyms.

Wordlist Corpora
nothing more than wordlist. The Words Corpus is the /usr/share/dict/words file from Unix, used by some spell checkers.
1 | # Filtering a Text: |
stopwords: high-frequency words like the, to and also that we sometimes want to filter out of a document before further processing.
1 | from nltk.corpus import stopwords |
Example:

1 | # The FreqDist comparison method permits us to check that the frequency of each letter in the candidate word |
Names ending in the letter a are almost always female.
1 | from nltk.corpus import names |
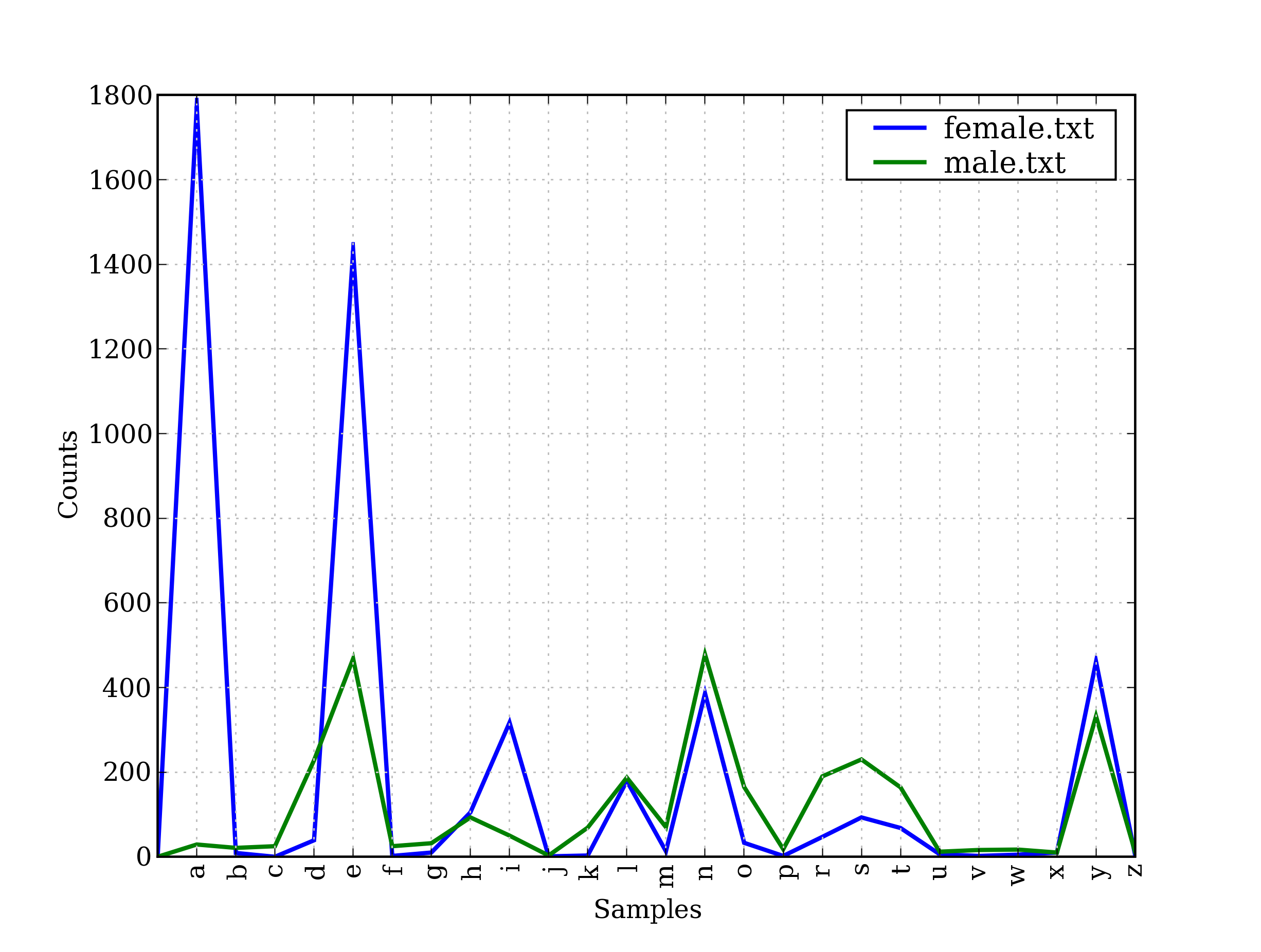
A Pronouncing Dictionary
spreadsheet containing a word plus some properties in each row.
CMU Pronouncing Dictionary for US English, which was designed for use by speech synthesizers. 单词和其发音,如('fireball', ['F', 'AY1', 'ER0', 'B', 'AO2', 'L']),数字表示重音。
1 | entries = nltk.corpus.cmudict.entries() |
1 | # finds all words whose pronunciation ends with a syllable sounding like nicks. |
1 | # find words having a particular stress pattern. |
1 | # find all the p-words consisting of three sounds, and group them according to their first and last sounds. |
1 | prondict = nltk.corpus.cmudict.dict() |
Comparative Wordlists
Swadesh wordlists consist of of about 200 common words in several languages. The languages are identified using an ISO 639 two-letter code.
1 | from nltk.corpus import swadesh |
Shoebox and Toolbox Lexicons
A Toolbox file consists of a collection of entries, where each entry is made up of one or more fields. loose structured.
1 | from nltk.corpus import toolbox |
WordNet
WordNet is a semantically-oriented dictionary of English, similar to a traditional thesaurus but with a richer structure.
Senses and Synonyms
The entity car.n.01 is called a synset, or “synonym set”, a collection of synonymous words (or “lemmas”):
1 | from nltk.corpus import wordnet as wn |
The WordNet Hierarchy
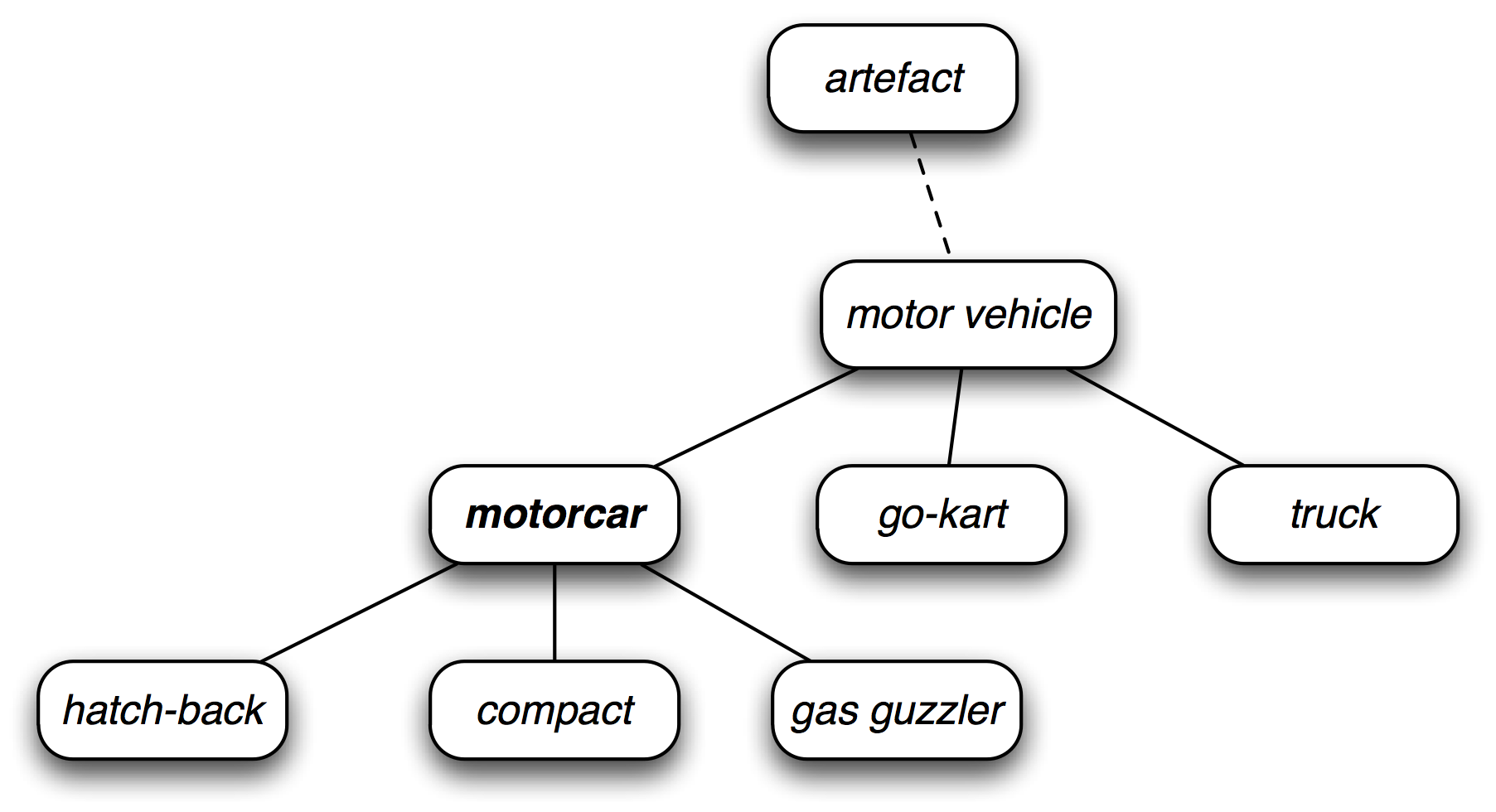
1 | motorcar = wn.synset('car.n.01') |
More Lexical Relations
from items to their components (meronyms) or to the things they are contained in (holonyms)
1 | wn.synset('tree.n.01').part_meronyms() |
the act of walking involves the act of stepping, so walking entails stepping.
1 | wn.synset('eat.v.01').entailments() |
Some lexical relationships hold between lemmas, e.g., antonymy
1 | wn.lemma('supply.n.02.supply').antonyms() |
查看synset的lexical relation可以用dir(wn.synset('harmony.n.02'))。
Semantic Similarity
1 | right = wn.synset('right_whale.n.01') |
查看帮助help(wn)。另一个相似的verb lexicon是nltk.corpus.verbnet。
Processing Raw Text
本章要解决的问题:
- How can we write programs to access text from local files and from the web, in order to get hold of an unlimited range of language material?
- How can we split documents up into individual words and punctuation symbols, so we can carry out the same kinds of analysis we did with text corpora in earlier chapters?
- How can we write programs to produce formatted output and save it in a file?
从本章起,代码执行前先:
1 | import nltk, re, pprint |
Accessing Text from the Web and from Disk
Electronic Books
http://www.gutenberg.org/catalog/上有25000本书,多语种的。
1 | # Access number 2554 from gutenberg |
如果开了代理,要用:
1 | proxies = {'http': 'http://www.someproxy.com:3128'} |
Tokenization: break up the string into words and punctuation.
1 | # tokenization |
Deal with HTML
1 | # original web page |
Processing Search Engine Results
Massive yet unstable.
Processing RSS Feeds
1 | import feedparser |
Reading Local Files
1 | # read whole text |
1 | import os |
Extracting Text from PDF, MSWord and Other Binary Formats
Use thirdparty libraries like pypdf and pywin32.
Better save is as a txt file manually. Or if the file is on the web, use search engine’s HTML version of the document.
Capturing User Input
1 | s = input("Enter some text: ") |
The NLP Pipiline

Strings: Text Processing at the Lowest Level
Strings are immutable, Lists are mutable.
1 | couplet = "Shall I compare thee to a Summer's day?"\ |
1 | from nltk.corpus import gutenberg |
Useful String Methods:
| Method | Functionality |
|---|---|
| s.find(t) | index of first instance of string t inside s (-1 if not found) |
| s.rfind(t) | index of last instance of string t inside s (-1 if not found) |
| s.index(t) | like s.find(t) except it raises ValueError if not found |
| s.rindex(t) | like s.rfind(t) except it raises ValueError if not found |
| s.join(text) | combine the words of the text into a string using s as the glue |
| s.split(t) | split s into a list wherever a t is found (whitespace by default) |
| s.splitlines() | split s into a list of strings, one per line |
| s.lower() | a lowercased version of the string s |
| s.upper() | an uppercased version of the string s |
| s.title() | a titlecased version of the string s |
| s.strip() | a copy of s without leading or trailing whitespace |
| s.replace(t, u) | replace instances of t with u inside s |
Text Processing with Unicode
What is Unicode?
In Python, code points are written in the form \uXXXX, where XXXX is the number in 4-digit hexadecimal form.
From a Unicode perspective, characters are abstract entities which can be realized as one or more glyphs. Only glyphs can appear on a screen or be printed on paper. A font is a mapping from characters to glyphs.
Extracting encoded text from files
1 | path = nltk.data.find('corpora/unicode_samples/polish-lat2.txt') |
In Python 3, source code is encoded using UTF-8 by default.
1 | ord('ń') # 324 |
1 | import unicodedata |
1 | # re dealing with unicode |
1 | # NLTK tokenizers allow Unicode |
Using your local encoding in Python
include the string # -*- coding: <coding> -*- as the first or second line of your file. Note that
Regular Expressions for Detecting Word Patterns
1 | import re |
Basic Regular Expression Meta-Characters, Including Wildcards, Ranges and Closures
| Operator | Behavior |
|---|---|
| . | Wildcard, matches any character |
| ^abc | Matches some pattern abc at the start of a string |
| abc$ | Matches some pattern abc at the end of a string |
| [abc] | Matches one of a set of characters |
| [A-Z0-9] | Matches one of a range of characters |
| ed¦ing¦s | Matches one of the specified strings (disjunction) |
| * | Zero or more of previous item, e.g. a*, [a-z]* (also known as Kleene Closure) |
| + | One or more of previous item, e.g. a+, [a-z]+ |
| ? | Zero or one of the previous item (i.e. optional), e.g. a?, [a-z]? |
| {n} | Exactly n repeats where n is a non-negative integer |
| {n,} | At least n repeats |
| {,n} | No more than n repeats |
| {m,n} | At least m and no more than n repeats |
| a(b¦c)+ | Parentheses that indicate the scope of the operators |
Useful Applications of Regular Expressions
Extract Word Pieces
1 | # find all the vowels in a word, then count them |
Doing More with Word Pieces
1 | # compress word like 'declaration' -> 'dclrtn' |
Finding Word Stems
比如搜索的时候,laptops和laptop的效果是一样的。
我们将来用NLTK的内置stemmer,不过可以先看看用正则表达式可以怎么做。
1 | def stem(word): |
Searching Tokenized Text
a special kind of regular expression for searching across multiple words in a text.
1 | from nltk.corpus import gutenberg, nps_chat |
nltk.re_show(p, s)annotates the string s to show every place where pattern p was matched. nltk.app.nemo()provides a graphical interface for exploring regular expressions.
Normalizeing Text
Stemmers
1 | raw = """DENNIS: Listen, strange women lying in ponds distributing swords |
1 | # indexing some texts and want to support search using alternative forms of words |
Lemmatization
1 | # compile the vocabulary of some texts and want a list of valid lemmas |
Regular Expressions for Tokenizing Text
Simple Approaches to Tokenization
最简单的就是从空格劈开。re.split(r'[ \t\n]+', raw)。
所有字母组劈开。re.split(r'\W+', raw)。
考虑连字符等。re.findall(r"\w+(?:[-']\w+)*|'|[-.(]+|\S\w*", raw)。
Regular Expression Symbols
| Symbol | Function |
|---|---|
| \b | Word boundary (zero width) |
| \d | Any decimal digit (equivalent to [0-9]) |
| \D | Any non-digit character (equivalent to [^0-9]) |
| \s | Any whitespace character (equivalent to [ \t\n\r\f\v]) |
| \S | Any non-whitespace character (equivalent to [^ \t\n\r\f\v]) |
| \w | Any alphanumeric character (equivalent to [a-zA-Z0-9_]) |
| \W | Any non-alphanumeric character (equivalent to [^a-zA-Z0-9_]) |
| \t | The tab character |
| \n | The newline character |
NLTK’s Regular Expression Tokenizer
1 | text = 'That U.S.A. poster-print costs $12.40...' |
可以先列好一组词,然后和tokenlizer的结果比较判断好坏。set(tokens).difference(wordlist)。
Segmentation
Sentence Segmentation
Punkt sentence segmenter
1 | text = nltk.corpus.gutenberg.raw('chesterton-thursday.txt') |
Word Segmentataion
没有明显词语边界的语言,比如我们中文。或者一些实时语言流,没有标注,也无法预知后一词。
Object Function,该字后要分词就标1,用下图方式评估好坏,然后随机出一大堆,选里面坠吼得。
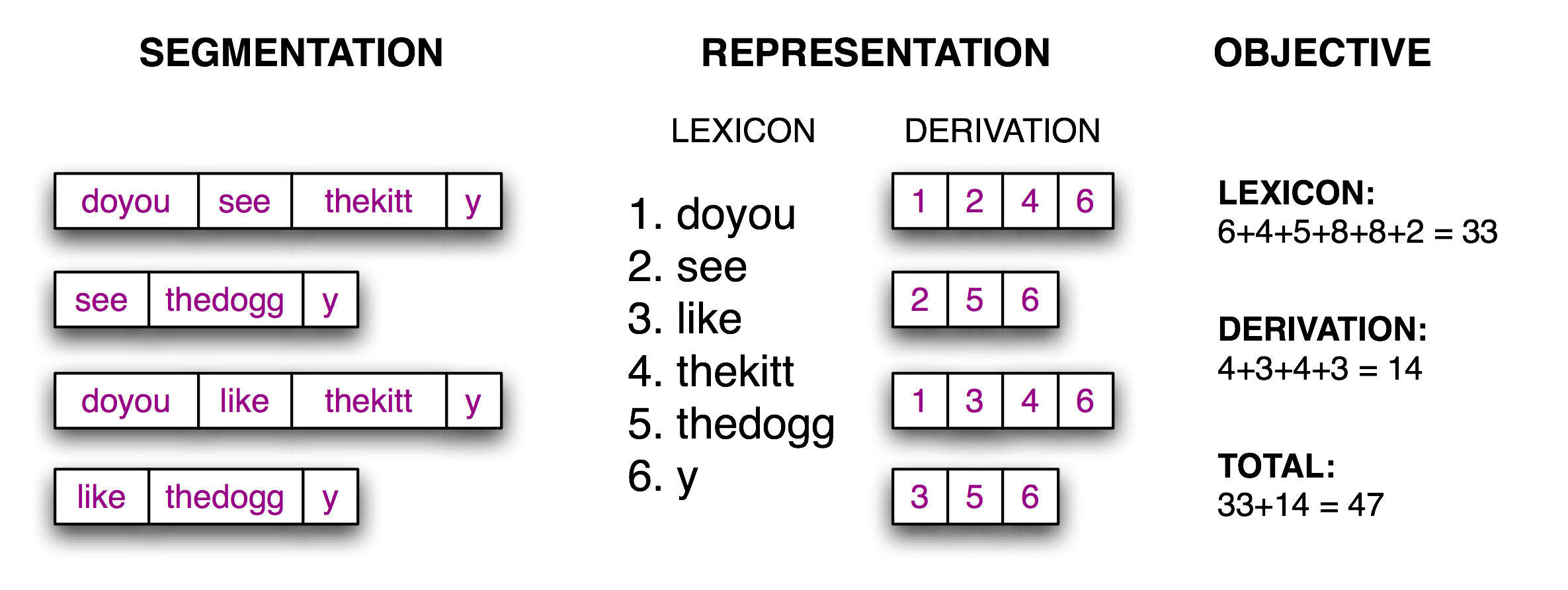
1 | # Reconstruct Segmented Text from String Representation |
Formatting: From Lists to Strings
From Lists to Strings
join()
1 | silly = ['We', 'called', 'him', 'Tortoise', 'because', 'he', 'taught', 'us', '.'] |
Strings and Formats
1 | fdist = nltk.FreqDist(['dog', 'cat', 'dog', 'cat', 'dog', 'snake', 'dog', 'cat']) |
Lining Things Up
1 | '{:<6}' .format(41) # '41 ' |
1 | # tabulating data |
Writing Results to a File
文件名中不要有空格,或是只有大小写不同。
1 | output_file = open('output.txt', 'w') |
Text Wrapping
1 | from textwrap import fill |
Writing Structured Programs
本章要解决的问题:
- How can you write well-structured, readable programs that you and others will be able to re-use easily?
- How do the fundamental building blocks work, such as loops, functions and assignment?
- What are some of the pitfalls with Python programming and how can you avoid them?
Back to the Basics
Assignment
List的Assignment实际上是引用。用id()可以看到id是否相同。
1 | nested = [[]] * 3 |
想要拷贝list,使用bar = foo[:],不过list里面的引用还是老样子。如果完全不想拷贝任何引用,使用copy.deepcopy()。
Equality
==表示值相等,is表示是同一物体。
Conditionals
在if条件中,非空string或list被视为True,空的string或list视为False。
all()和any()可以被用在list上,检查all或any项满足某条件。
1 | all(len(w) > 4 for w in sent) # False |
Sequences
tuple初始化时用,,可以省略()。
1 | typleT = 'walk', 'fem', 3 |
Operating on Sequence Types
| Python Expression | Comment |
|---|---|
| for item in s | iterate over the items of s |
| for item in sorted(s) | iterate over the items of s in order |
| for item in set(s) | iterate over unique elements of s |
| for item in reversed(s) | iterate over elements of s in reverse |
| for item in set(s).difference(t) | iterate over elements of s not in t |
1 | words = ['I', 'turned', 'off', 'the', 'spectroroute'] |
1 | text = nltk.corpus.nps_chat.words() |
Combining Different Sequence Types
1 | # sorting the words in a string by their length |
We often use lists to hold sequences of words. In contrast, a tuple is typically a collection of objects of different types, of fixed length. We often use a tuple to hold a record, a collection of different fields relating to some entity.
1 | lexicon = [ |
Generator Expressions
1 | max([w.lower() for w in word_tokenize(text)]) |
Questions of Style
“The Art of Computer Programming”.
Python Coding Style
A style guide for Python code published by the designers of the Python language.
consistency.
Procedural vs Declarative Style
Procedural更像机器操作步骤,应该用Declarative风格。
1 | total = sum(len(t) for t in tokens) |
Some Legitimate Uses for Counters
1 | m, n = 3, 7 |
Functions: The Foundation of Structured Programming
1 | import re |
Function Inputs and Outputs
Functions should modify the contents of a parameter, or return a value, not both.
Parameter Passing
value只传值,有结构的东西传的是引用。
Variable Scopr
Function可以通过global改变global变量的值,不过应该尽量避免使用。应该用参数和返回值。
Checking Parameter Types
1 | def tag(word): |
Functional Decomposition
大函数分解成若干小函数。不要有副作用。
1 | from urllib import request |
Documenting Functions
1 | def accuracy(reference, test): |
Doing More with Functions
Functions as Arguments
1 | sent = ['Take', 'care', 'of', 'the', 'sense', ',', 'and', 'the', |
Accumulative Functions
These functions start by initializing some storage, and iterate over input to build it up, before returning some final object.
1 | def search2(substring, words): |
1 | def permutations(seq): |
Higher-Order Functions
filter()
1 | def is_content_word(word): |
map()applies a function to every item in a sequence.
1 | # equivalent |
Named Arguments
Take care not to use a mutable object as the default value of a parameter.
1 | def repeat(msg='<empty>', num=1): |
*args= all the unnamed parameters of the function. **kwargs=named parameters.
1 | def generic(*args, **kwargs): |
1 | # 用with会自动关闭打开的文档 |
Program Development
Key high-level abilities are algorithm design and its manifestation in structured programming. Key low-level abilities include familiarity with the syntactic constructs of the language, and knowledge of a variety of diagnostic methods for trouble-shooting a program which does not exhibit the expected behavior.
Structure of a Python Module
The purpose of a program module is to bring logically-related definitions and functions together in order to facilitate re-use and abstraction.
individual .py files.
可以用__file__查看NLTK module的位置:
1 | nltk.metrics.distance.__file__ # '/usr/lib/python2.5/site-packages/nltk/metrics/distance.pyc' |
Some module variables and functions are only used within the module. These should have names beginning with an underscore, e.g. _helper(), since this will hide the name. If another module imports this one, using the idiom: from module import *, these names will not be imported. You can optionally list the externally accessible names of a module using a special built-in variable like this: __all__ = ['edit_distance', 'jaccard_distance'].
Multi-Module Programs

Sources of Error
First, the input data may contain some unexpected characters.
Second, a supplied function might not behave as expected.
Third, our understanding of Python’s semantics may be at fault.
Debugging Techniques
print, stack trace
Python’s debugger:
1 | import pdb |
help/ step/ next/ break/ continue
Defensive Programming
assert如assert(isinstance(text, list))。
maintain a suite of test cases.regression testing
Algorithm Design
看我自己的算法总结系列。
Examples:
1 | # Four Ways to Compute Sanskrit Meter: |
A Sample of Python Libraries
Matplotlib: 二维图形。
1 | from numpy import arange |
NetworkX: for defining and manipulating structures consisting of nodes and edges, known as graphs.
1 | import networkx as nx |
csv: read and write files stored in this format.
1 | import csv |
NumPy: provides substantial support for numerical processing in Python.
1 | # array |
NLTK’s clustering package nltk.cluster makes extensive use of NumPy arrays, and includes support for k-means clustering, Gaussian EM clustering, group average agglomerative clustering, and dendrogram plots. For details, type help(nltk.cluster).
Other Python Libraries
help of the Python Package Index.
Categorizing and Tagging Words
本章要解决的问题:
- What are lexical categories and how are they used in natural language processing?
- What is a good Python data structure for storing words and their categories?
- How can we automatically tag each word of a text with its word class?
The process of classifying words into their parts of speech and labeling them accordingly is known as part-of-speech tagging, POS-tagging, or simply tagging. Parts of speech are also known as word classes or lexical categories. The collection of tags used for a particular task is known as a tagset.
Using a Tagger
1 | text = word_tokenize("They refuse to permit us to obtain the refuse permit") |
Tagged Corpora
Representing Tagged Tokens
1 | sent = ''' |
Reading Tagged Corpora
1 | nltk.corpus.sinica_treebank.tagged_words() |
相对应的,tagged_sents() divides up the tagged words into sentences rather than presenting them as one big list.
A Universal Part-of-Speech Tagset
| Tag | Meaning | English Examples |
|---|---|---|
| ADJ | adjective | new, good, high, special, big, local |
| ADP | adposition | on, of, at, with, by, into, under |
| ADV | adverb | really, already, still, early, now |
| CONJ | conjunction | and, or, but, if, while, although |
| DET | determiner, article | the, a, some, most, every, no, which |
| NOUN | noun | year, home, costs, time, Africa |
| NUM | numeral | twenty-four, fourth, 1991, 14:24 |
| PRT | particle | at, on, out, over per, that, up, with |
| PRON | pronoun | he, their, her, its, my, I, us |
| VERB | verb | is, say, told, given, playing, would |
| . | punctuation marks | . , ; ! |
| X | other | ersatz, esprit, dunno, gr8, univeristy |
1 | # most common tags in the news category of the Brown corpus. |
Nouns
Syntactic Patterns involving some Nouns:
| Word | After a determiner | Subject of the verb |
|---|---|---|
| woman | the woman who I saw yesterday … | the woman sat down |
| Scotland | the Scotland I remember as a child … | Scotland has five million people |
| book | the book I bought yesterday … | this book recounts the colonization of Australia |
| intelligence | the intelligence displayed by the child … | Mary’s intelligence impressed her teachers |
N for common nouns like book, NP for proper nouns like Scotland.
1 | # what parts of speech occur before a noun |
Verbs
Syntactic Patterns involving some Verbs:
| Word | Simple | With modifiers and adjuncts (italicized) |
|---|---|---|
| fall | Rome fell | Dot com stocks suddenly fell like a stone |
| eat | Mice eat cheese | John ate the pizza with gusto |
VBD past tense, VBN past participle.
1 | wsj = nltk.corpus.treebank.tagged_words(tagset='universal') |
Adjectives and Adverbs
Each dictionary and grammar classifies differently.
Unsiplified Tags
1 | # finds all tags starting with NN, and provides a few example words for each one. |
Exploring Tagged Corpora
1 | # "often" used as what? |
1 | # searching for Three-Word Phrases Using POS Tags |
Mapping Words to Properties Using Python Dictionaries
Indexing Lists vs Dictionaries
Linguistic Objects as Mappings from Keys to Values:
| Linguistic Object | Maps From | Maps To |
|---|---|---|
| Document Index | Word | List of pages (where word is found) |
| Thesaurus | Word sense | List of synonyms |
| Dictionary | Headword | Entry (part-of-speech, sense definitions, etymology) |
| Comparative Wordlist | Gloss term | Cognates (list of words, one per language) |
| Morph Analyzer | Surface form | Morphological analysis (list of component morphemes) |
Dictionaries in Python
1 | pos = {} |
Defining Dictionaries
dictionary keys must be immutable types.
1 | pos = {'colorless': 'ADJ', 'ideas': 'N', 'sleep': 'V', 'furiously': 'ADV'} |
Default Dictionaries
寻某值不遇时,自动创建一个有默认值的项。
1 | pos = defaultdict(list) |
1 | # 出现太少的词用UNK代替 |
Incrementally Updating a Dictionary
1 | # Incrementally Updating a Dictionary, and Sorting by Value |
NLTK中创建defaultdict(list)的一个更方便的形式。其实nltk.FreqDist实际上也是脱胎于defaultdict(int)。
1 | anagrams = nltk.Index((''.join(sorted(w)), w) for w in words) |
Complex Keys and Values
1 | pos = defaultdict(lambda: defaultdict(int)) |
Inverting a Dictionary
当想根据value查找key的时候。
1 | pos = {'colorless': 'ADJ', 'ideas': 'N', 'sleep': 'V', 'furiously': 'ADV'} |
Python’s Dictionary Methods: A summary of commonly-used methods and idioms involving dictionaries.
| Example | Description |
|---|---|
| d = {} | create an empty dictionary and assign it to d |
| d[key] = value | assign a value to a given dictionary key |
| d.keys() | the list of keys of the dictionary |
| list(d) | the list of keys of the dictionary |
| sorted(d) | the keys of the dictionary, sorted |
| key in d | test whether a particular key is in the dictionary |
| for key in d | iterate over the keys of the dictionary |
| d.values() | the list of values in the dictionary |
| dict([(k1,v1), (k2,v2), …]) | create a dictionary from a list of key-value pairs |
| d1.update(d2) | add all items from d2 to d1 |
| defaultdict(int) | a dictionary whose default value is zero |
Automatic Tagging
Automatically add part-of-speech tags to text. 因为word的tag在句子中才有意义,所以我们分析tagged过的sentence。
1 | # 我们用这个示例 |
The Default Tagger
把所有词都tag成最可能的那一款。
1 | tags = [tag for (word, tag) in brown.tagged_words(categories='news')] |
The Regular Expression Tagger
根据一定pattern对word做匹配。
1 | patterns = [ |
The Lookup Tagger
先总结最常用词的tag,然后用他们做表在里面查找,没有就用默认值。
随着model size变大,tagger表现迅速达到一个高值,然后就停滞了。
1 | def performance(cfd, wordlist): |
Evaluation
评估表现很重要,因为错误在流水线中会不断放大。
N-Gram Tagging
Unigram Tagging
给每个词其最可能的tag。有点像lookup tagger,只不过是通过training建立的model。
Separating the Training and Testing Data.
1 | from nltk.corpus import brown |
General N-Gram Tagging
An n-gram tagger is a generalization of a unigram tagger whose context is the current word together with the part-of-speech tags of the n-1 preceding tokens, as shown in 5.1. The tag to be chosen, tn, is circled, and the context is shaded in grey. In the example of an n-gram tagger shown in 5.1, we have n=3; that is, we consider the tags of the two preceding words in addition to the current word. An n-gram tagger picks the tag that is most likely in the given context.
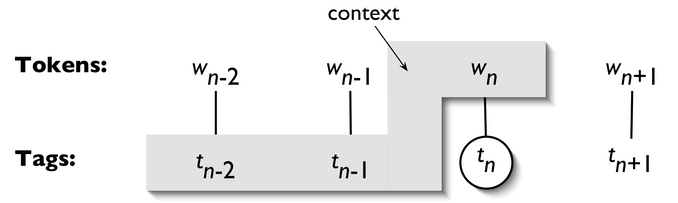
NgramTagger
对见过的句子表现的很好,没见过的就糟糟糟。
1 | bigram_tagger = nltk.BigramTagger(train_sents) |
Combining Taggers
Use the more accurate algorithms when we can, but to fall back on algorithms with wider coverage when necessary.
例如:
Try tagging the token with the bigram tagger.
If the bigram tagger is unable to find a tag for the token, try the unigram tagger.
If the unigram tagger is also unable to find a tag, use a default tagger.
用NLTK tagger的backoff参数。
1 | t0 = nltk.DefaultTagger('NN') |
Tagging Unknown Words
A useful method to tag unknown words based on context is to limit the vocabulary of a tagger to the most frequent n words, and to replace every other word with a special word UNK.
During training, a unigram tagger will probably learn that UNK is usually a noun. However, the n-gram taggers will detect contexts in which it has some other tag.
Storing Taggers
保存训练好的tagger。
1 | # save tagger t2 to a file t2.pk1 |
Performance Limitations
1 | # part-of-speech ambiguity of a trigram tagger. |
confusion matrix charts expected tags (the gold standard) against actual tags generated by a tagger.
1 | test_tags = [tag for sent in brown.sents(categories='editorial') |
Transformation-Based Tagging
n-gram tagger会有较大的稀疏散列表存储n-gram table(or language model)。而且只考虑之前word的tagger而忽略word本身的信息。
Brill Tagging,begin with broad brush strokes then fix up the details, with successively finer changes.
比如先用Unigram标记一遍,然后根据Brill Tagging中的每条Rule修改一遍结果,这些Rule也是training出来的。
1 | nltk.tag.brill.demo() |
How to Determine the Category of a Word
In general, linguists use morphological, syntactic, and semantic clues to determine the category of a word.
Morphological Clues
词的内部结构提供的信息,例如-ness is a suffix that combines with an adjective to produce a noun。
Syntactic Clues
该词出现的上下文。
Semantic Clues
根据词的定义。
New Words
名词多。noun属于open class,而preposition就是closed class。
Morphology in Part of Speech Tagsets
不同的语法结构暗示该词词性。
Learning to Classify Text
本章要解决的问题:
- How can we identify particular features of language data that are salient for classifying it?
- How can we construct models of language that can be used to perform language processing tasks automatically?
- What can we learn about language from these models?
Supervised Classification
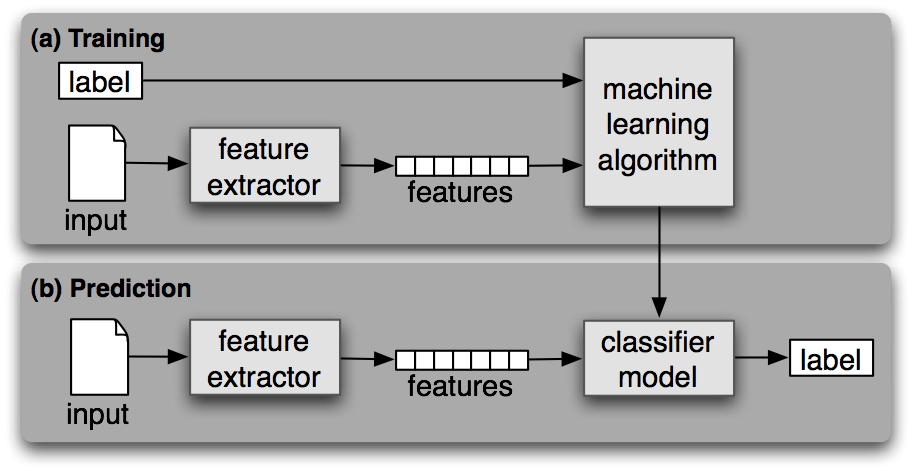
Gender Identification
首先要想好what features of the input are relevant, and how to encode those features.
1 | # feature set |
Choosing the Right Features
充分理解手头任务,好好设计feature。
可以先使用想到的所有可能feature,然后检查哪些才是真正有用的。feature用得太多容易对training data过拟合。
使用一个dev set,用其进行error analysis。看看出错的都是哪些项,总结一下,修改feature。
1 | def gender_features2(name): |
Document Classification
看看一篇影评到底是在肯定还是否定。
1 | # get movie reviews in a tuple |
Part-of-Speech Tagging
通过后缀猜测词性。
1 | # find the most common suffixes |
Exploiting Context
不再只是孤立看待每个词,还要看上下文。所以参数不能只是一个词了,而是整句话。
1 | def pos_features(sentence, i): |
Sequence Classification
In order to capture the dependencies between related classification tasks, we can use joint classifier models, which choose an appropriate labeling for a collection of related inputs. In the case of part-of-speech tagging, a variety of different sequence classifier models can be used to jointly choose part-of-speech tags for all the words in a given sentence.
Consecutive classification(greedy sequence classification): find the most likely class label for the first input, then to use that answer to help find the best label for the next input. The process can then be repeated until all of the inputs have been labeled. Used by bigram tagger.
1 | # Part of Speech Tagging with a Consecutive Classifier |
Other Methods for Sequence Classification
之前的算法都是定了tag就不能回头。
一种方法是改用一个transformational strategy的classifier。Transformational joint classifiers work by creating an initial assignment of labels for the inputs, and then iteratively refining that assignment in an attempt to repair inconsistencies between related inputs. 比如The Brill tagger.
另一种方法是给每个tag打分,然后比较总分。就是Hidden Markov Models用的方法。还有Maximum Entropy Markov和Linear-Chain Conditional Random Field Models。
Further Examples of Supervised Classification
Sentence Segmentation
Sentence Segmentation: whenever we encounter a symbol that could possibly end a sentence, such as a period or a question mark, we have to decide whether it terminates the preceding sentence.
1 | # obtain some data that has already been segmented into sentences and convert it into a form that is suitable for extracting features |
Identifying Dialogue Act Types
1 | # extract the basic messaging data |
Recognizing Textual Entailment
Recognizing Textual Entailment: the task of determining whether a given piece of text T entails another text called the “hypothesis”.
两句话是否是合理的上下文对话。注意这个合理并不是逻辑上,而是whether a human would conclude that the text provides reasonable evidence for taking the hypothesis to be true.也就是从text中能否合理推论出hypothesis的论点。
1 | # word types serve as proxies for information, and out features count the degree of word overlap, and the degree to which there are words in the hypothesis but not in the text |
Scaling Up to Large Datasets
python的效率比较低,如果数据量大的话看看NLTK’s facilities for interfacing with external machine learning packages.
Evaluation
看看classification model到底可靠否。
The Test Set
即evaluation set。training data和test data不要太相似,别是同一个种类同一个文件的。
Accuracy
nltk.classify.accuracy()
Precision and Recall
- True positives are relevant items that we correctly identified as relevant.
- True negatives are irrelevant items that we correctly identified as irrelevant.
- False positives (or Type I errors) are irrelevant items that we incorrectly identified as relevant.
- False negatives (or Type II errors) are relevant items that we incorrectly identified as irrelevant.
于是
- Precision, which indicates how many of the items that we identified were relevant, is TP/(TP+FP).
- Recall, which indicates how many of the relevant items that we identified, is TP/(TP+FN).
- The F-Measure (or F-Score), which combines the precision and recall to give a single score, is defined to be the harmonic mean of the precision and recall: (2 × Precision × Recall) / (Precision + Recall).
Confusion Matrices
A confusion matrix is a table where each cell [i,j] indicates how often label j was predicted when the correct label was i.
1 | def tag_list(tagged_sents): |
Cross-Validation
perform multiple evaluations on different test sets, then to combine the scores from those evaluations, a technique known as cross-validation.
Decision Trees
Three machine learning methods that can be used to automatically build classification models: decision trees, naive Bayes classifiers, and Maximum Entropy classifiers.
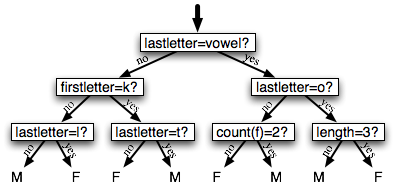
Entropy and Information Gain
information gain, measures how much more organized the input values become when we divide them up using a given feature. To measure how disorganized the original set of input values are, we calculate entropy of their labels, which will be high if the input values have highly varied labels, and low if many input values all have the same label. In particular, entropy is defined as the sum of the probability of each label times the log probability of that same label. 每个label都要有一定分量才好,不要只有一个label最多。
1 | import math |
Decision Tree的缺点是分支多就需要更大的training data,branches几何级数增长,影响力小的feature很难用上,被迫按照一定顺序进行判断。
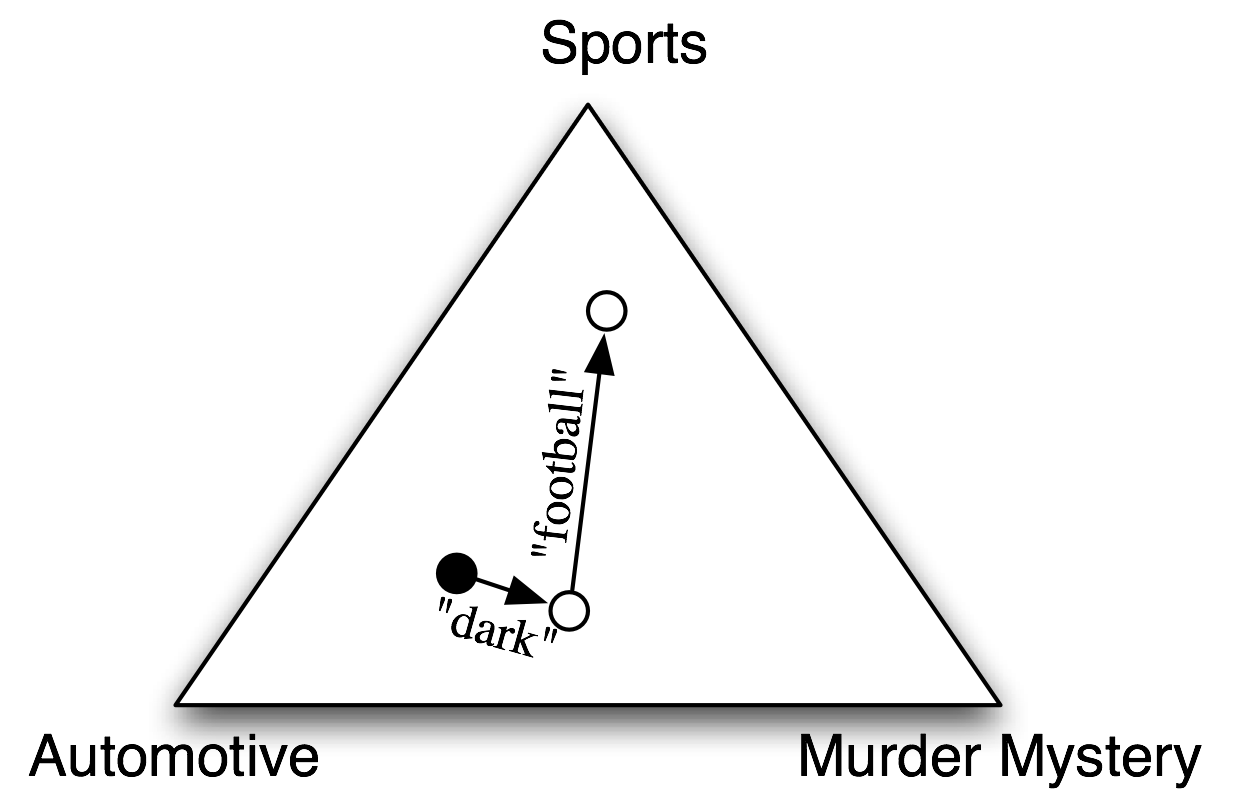
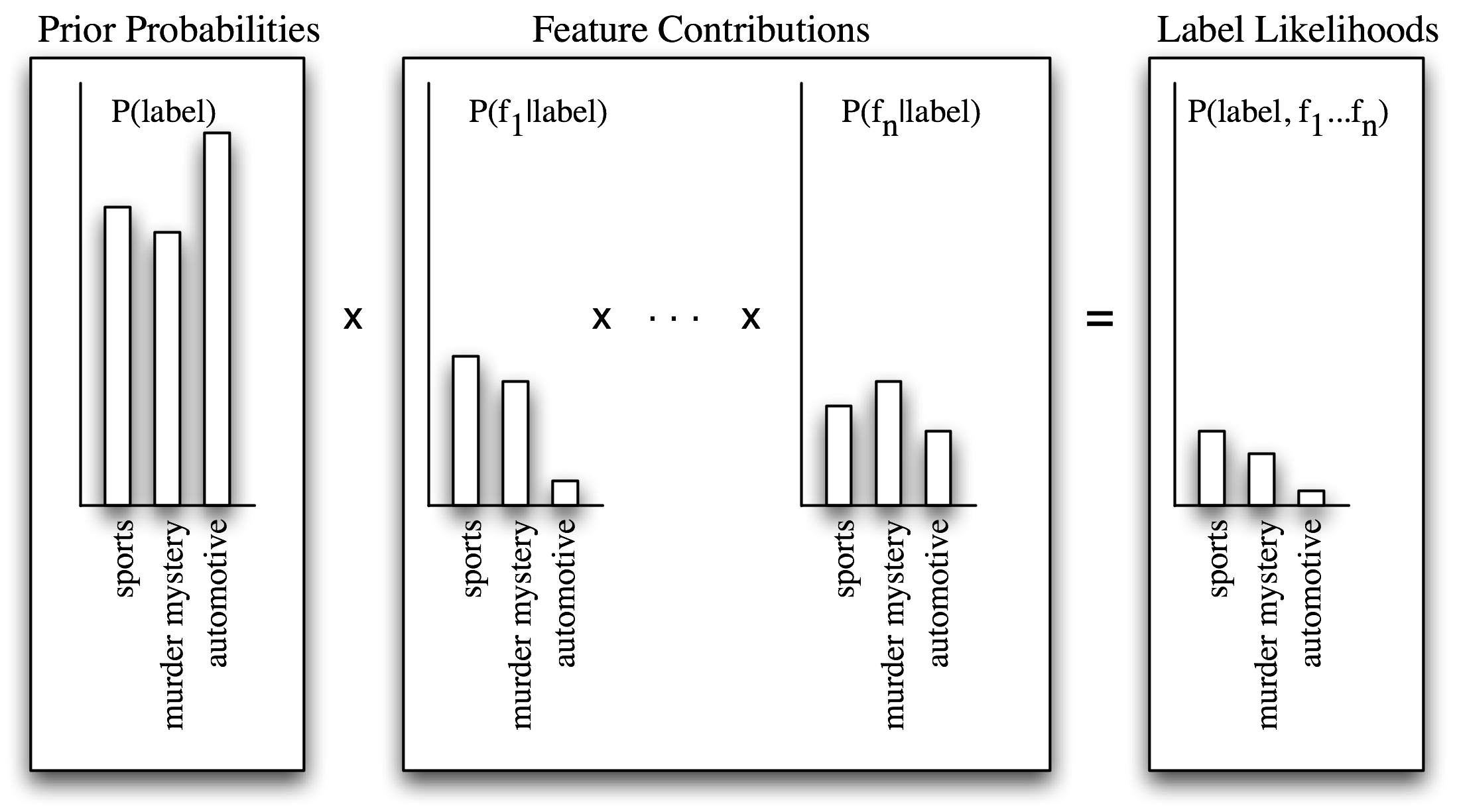
Naive Bayes Classifiers
In naive Bayes classifiers, every feature gets a say in determining which label should be assigned to a given input value. To choose a label for an input value, the naive Bayes classifier begins by calculating the prior probability of each label, which is determined by checking frequency of each label in the training set. The contribution from each feature is then combined with this prior probability, to arrive at a likelihood estimate for each label. The label whose likelihood estimate is the highest is then assigned to the input value.
每个feature在每种label里的可能性自己乘起来。是假设feature之间是完全独立的,所以naive。
Maximum Entropy Classifiers
不用probabilites,而是用search techniques to find a set of parameters that will maximize the performance of the classifier.
In particular, it looks for the set of parameters that maximizes the total likelihood of the training corpus, which is defined as:
使用iterative optimization,从随机参数开始,逐步迭代改进。算法可能会比较慢。
Generative vs Conditional Classifiers
Naive Bayes Classifier is an example of a generative classifier, which builds a model that predicts P(input, label), the joint probability of a (input, label) pair.可以回答以下问题:
- What is the most likely label for a given input?
- How likely is a given label for a given input?
- What is the most likely input value?
- How likely is a given input value?
- How likely is a given input value with a given label?
- What is the most likely label for an input that might have one of two values (but we don’t know which)?
Maximum Entropy Classifier is an example of a conditional classifier. Conditional classifiers build models that predict P(label|input) — the probability of a label given the input value. Thus, conditional models can still be used to answer questions 1 and 2. However, conditional models can not be used to answer the remaining questions 3-6.
Modeling Linguistic Patterns
Classifier的存在是为了更好地分析Linguistic Patterns。
descriptive models and explanatory models.
Descriptive models capture patterns in the data but they don’t provide any information about why the data contains those patterns.
Explanatory models attempt to capture properties and relationships that cause the linguistic patterns.
从corpus直接分析出来的一般都是descriptive models。
Extracting Information from Text
本章要解决的问题:
- How can we build a system that extracts structured data, such as tables, from unstructured text?
- What are some robust methods for identifying the entities and relationships described in a text?
- Which corpora are appropriate for this work, and how do we use them for training and evaluating our models?
Information Extraction
First convert the unstructured data of natural language sentences into the structured data of the text. Then we reap the benefits of powerful query tools such as SQL.
使用此技术的应用有:business intelligence, resume harvesting, media analysis, sentiment detection, patent search, and email scanning.
Information Extraction Architecture
![Simple Pipeline Architecture for an Information Extraction System. This system takes the raw text of a document as its input, and generates a list of (entity, relation, entity) tuples as its output. For example, given a document that indicates that the company Georgia-Pacific is located in Atlanta, it might generate the tuple ([ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']).](http://www.nltk.org/images/ie-architecture.png)
1 | ## first 3 steps |
Next, in named entity detection, we segment and label the entities that might participate in interesting relations with one another.
Finally, in relation extraction, we search for specific patterns between pairs of entities that occur near one another in the text, and use those patterns to build tuples recording the relationships between the entities.
Chunking
Entity Detection中一个基础技术Chunking。小方块表示word-level tokenization和part-of-speech tagging,大方块表示higher-level chunking。大方块就是Chunking。chunk们不会重叠。
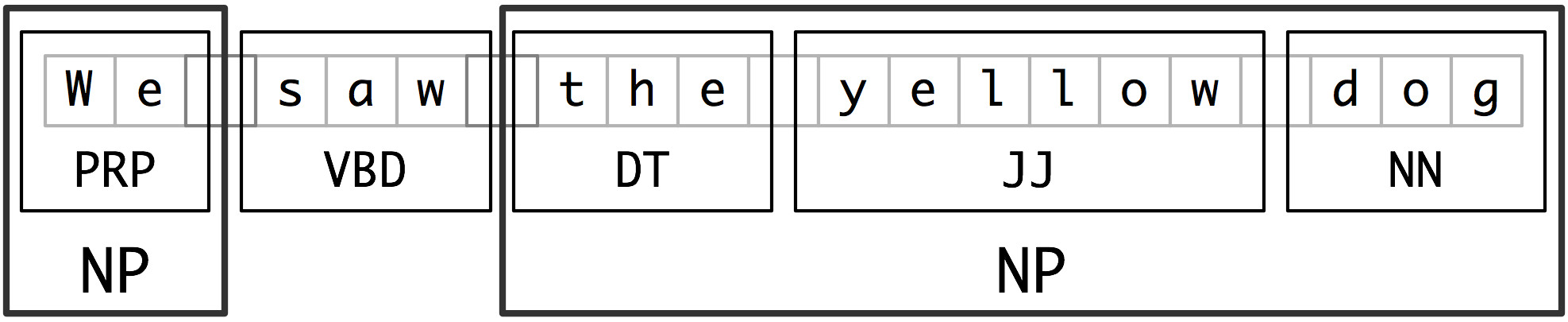
Noun Phrase Chunking
NP-chunking。找individual noun phrases。part-of-speech tags在这里很有用。
1 | # Example of a simple regular expression based NP Chunker |
Tag Patterns
如<DT>?<JJ.*>*<NN.*>+表示 any sequence of tokens beginning with an optional determiner, followed by zero or more adjectives of any type (including relative adjectives like earlier/JJR), followed by one or more nouns of any type.
Chunking with Regular Expressions
可以同时指定多条chunking rule。
1 | grammar = r""" |
Exploring Text Corpora
extract phrases matching a particular sequence of part-of-speech tags.
1 | cp = nltk.RegexpParser('CHUNK: {<V.*> <TO> <V.*>}') |
Chinking
Chink is a sequence of tokens that is not included in a chunk.
||Entire chunk| Middle of a chunk| End of a chunk|
|—|---|—|
|Input| [a/DT little/JJ dog/NN]| [a/DT little/JJ dog/NN]| [a/DT little/JJ dog/NN]
|Operation| Chink “DT JJ NN”| Chink “JJ”| Chink “NN”
|Pattern| }DT JJ NN{| }JJ{| }NN{
|Output| a/DT little/JJ dog/NN| [a/DT] little/JJ [dog/NN]| [a/DT little/JJ] dog/NN
1 | # put the entire sentence into a single chunk, then excise the chinks. |
Representing Chunks: Tags vs Trees
最广泛使用的文件表达方式用了IOB tags。In this scheme, each token is tagged with one of three special chunk tags, I (inside), O (outside), or B (begin). A token is tagged as B if it marks the beginning of a chunk. Subsequent tokens within the chunk are tagged I. All other tokens are tagged O.
表现成Tag是这样的:

在文件中表示是这样的:
1 | We PRP B-NP |
表示成Tree是这样的:
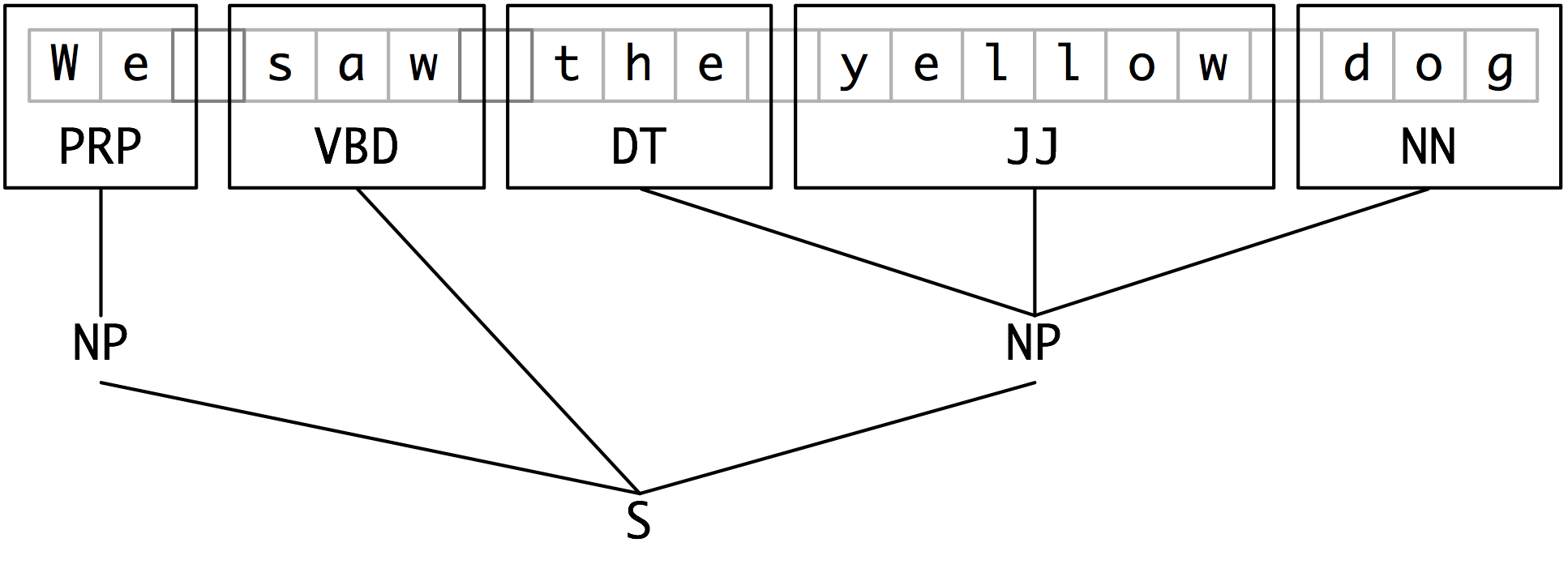
Developing and Evaluating Chunkers
Reading IOB Format and the CoNLL 2000 Corpus
nltk.chunk.conllstr2tree(text, chunk_types=['NP']).draw()

1 | # 从CoNLL 2000里拿出100句NP chunk的句子。 |
Simple Evaluation and Baselines
1 | # Noun Phrase Chunking with a Unigram Tagger |
Training Classifier-Based Chunkers
Regular-expression based chunkers和N-gram chunkers都是完全根据part-of-speech tags来判断如何分chunk的。有时这个信息并不够,还应该用word本身有的信息。
例如下面的句子,chunk分法应完全不同。
1 | a. Joey/NN sold/VBD the/DT farmer/NN rice/NN ./. |
1 | # Noun Phrase Chunking with a Consecutive Classifier |
Recursion in Linguistic Structure
Building Nested Structure with Cascaded Chunkers
build chunk structures of arbitrary depth, simply by creating a multi-stage chunk grammar containing recursive rules.
1 | # a chunker that handles NP, PP, VP and S |
并不是最好的方法,期待第8章学的full parsing。
Trees
1 | tree1 = nltk.Tree('NP', ['Alice']) |
Tree Traversal
1 | # a recursive function to traverse a tree |
Named Entity Recognition
“Facility”: human-made artifacts in the domains of architecture and civil engineering; and “GPE”: geo-political entities such as city, state/province, and country.
Commonly Used Types of Named Entity
| NE Type | Examples |
|---|---|
| ORGANIZATION | Georgia-Pacific Corp., WHO |
| PERSON | Eddy Bonte, President Obama |
| LOCATION | Murray River, Mount Everest |
| DATE | June, 2008-06-29 |
| TIME | two fifty a m, 1:30 p.m. |
| MONEY | 175 million Canadian Dollars, GBP 10.40 |
| PERCENT | twenty pct, 18.75 % |
| FACILITY | Washington Monument, Stonehenge |
| GPE | South East Asia, Midlothian |
NER的目标就是identifying the boundaries of the NE, and identifying its type.
NLTK已经有一个训练好的classifer来识别named entities,nltk.ne_chunk().
1 | print(nltk.ne_chunk(sent, binary=False)) # binary为True则只识别出NE,不区分出子类。 |
Relation Extraction
当named entites确定了以后就要找关系了。
一个简单的方法,找(X, a, Y)的关系,其中a是一串表达此关系的词汇。
1 | IN = re.compile(r'.*\bin\b(?!\b.+ing)') # 其中的(?!\b.+ing\b)是删掉类似success in supervising the transition of这样的结构。 |
用NLTK库里自带的方法,使用part-of-speech tags。例子是Dutch的。
1 | from nltk.corpus import conll2002 |
Analyzing Sentence Structure
本章要解决的问题:
- How can we use a formal grammar to describe the structure of an unlimited set of sentences?
- How do we represent the structure of sentences using syntax trees?
- How do parsers analyze a sentence and automatically build a syntax tree?
Some Grammatical Dilemmas
Linguistic Data and Unlimited Possibilities
使用一些template可以将句子组合成无限长,由许多grammatical sentences组成。
Grammars use recursive productions of the form S → S and S.
Ubiquitous Ambiguity
例句:While hunting in Africa, I shot an elephant in my pajamas. How he got into my pajamas, I don’t know.
1 | groucho_grammar = nltk.CFG.fromstring(""" |
这个句子可以被解读为这样两棵树。
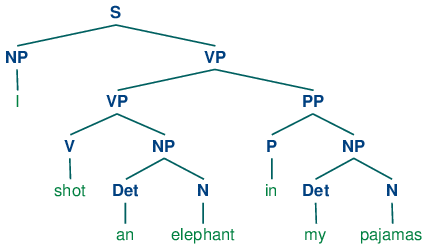
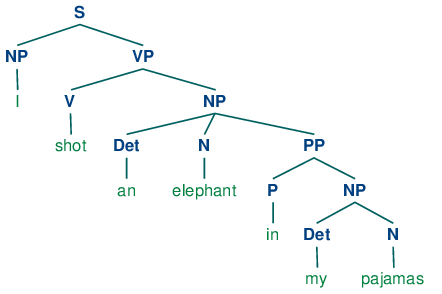
What’s the Use of Syntax?
Beyond n-grams